AlphaProof, AlphaGeometry, ChatGPT, and why the future of AI is neurosymbolic
What comes after chatbots?

The neural network approach known as generative AI — especially its poster chatbot ChatGPT – has captured the world’s imagination, but will soon flame out.
No, it won’t completely disappear, but the longtime thesis of this feed – that generative AI would turn out to be dud — has, remarkably, gone in less than a year from a generally belittled minority opinion to a widely-held expectation, with new commentaries suggesting the same in major newspapers every day. I fully expect that the generative AI bubble will begin to burst within the next 12 months, for many reasons:
• The current approach has reached a plateau
• There is no killer app
• Hallucinations remain
• Boneheaded errors remain
• Nobody has a moat
• People are starting to realize all of the above.
Some will be happy when the bubble bursts, others sad. I have mixed feelings; I think that GenAI is vastly overrated and overhyped, but fear that its collapse may well lead to an AI winter of sorts, like what happened in the mid-1980s, when AI “expert systems” rapidly ascended and rapidly fell.
That said, I am certain that the impending collapse won’t lead to the absolute death of AI. There is too much at stake.
What the collapse of generative AI might lead to, after a quiet period, is a renaissance. Generative AI may well never be as popular as it has been over the last year, but new techniques will come, new techniques that will work better, and that address some of the failings of generative AI.
The biggest intrinsic failings of generative AI have to do with reliability, in a way that I believe can never be solved, given their inherent nature. Before we can consider what might come after generative AI, we need to understand generative AI's inherent nature.
This longer-than-usual essay is therefore divided into two parts: an explanation generative AI and its limitations at an intuitive level, and discussion of a possible approach to addressing those limitations, focused around a discussion of fascinating new result from Google DeepMind — one of the few AI reports this year to excite me.
LLMs: An intuition about why they work, and why they fail
Nobody understands LLMs fully; we can write the code them, but we don’t really understand their internals, or what they will do at any given moment, in part because their outputs depend so heavily on the minutia of their training histories. But getting a solid if somewhat rough intuition is not actually that hard.
At some level, generative AI is a bit like (though not exactly like) a lookup table, such as a multiplication table (AKA times table). A times table is good for the entries in its table but of little use on its own beyond that table. If you had a times table that goes to 12 x 12, but no further, you are on your own for 13 * 14; the answer just isn’t there. In systematic studies, LLMs behave much like that with math, markedly better at small multiplication problems (say 4 digits times 4 digits) than larger ones (say 6 digits times 6 digits), and better on those they have been trained on than those they have not been trained. Now, LLMs aren’t literally lookup tables, restricted to exactly the things that have been pre-encoded (they generalize to a modest degree), but they are enough like lookup tables that imagining that way helps a lot to prime intuitions. What one finds, over and over, is that they are better at things that they have encountered before than things that they haven’t. They are especially poor if new items are different in important and subtle ways from old ones..
In the vast literature of examples of GPT “fails”, many of the most revealing come from statistician/machine learning expert Colin Fraser, who enjoys taking recent models and torturing them with slight variations on familiar problems. This example is sublime:
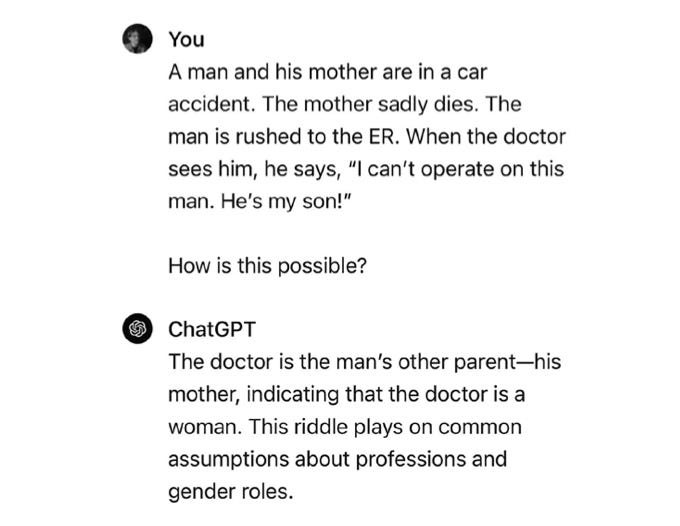
If you read carefully, you immediately realize that ChatGPT’s answer—“the man’s other parent—his mother” —simply can’t be right. She is dead; the answer is a wild violation of common sense.
Why has ChatGPT managed to get things so utterly wrong?
The system has based its answer on a more traditional riddle that appeared in the training set (the input to its lookup table-ish functionality) but failed to understand at a deeper level what’s actually going on. For example, ChatGPT might have been trained on cases like this:
A father and his son are in a car accident. The father dies instantly, and the son is taken to the nearest hospital. The doctor comes in and exclaims “I can’t operate on this boy.”
“Why not?” the nurse asks.
“Because he’s my son,” the doctor responds.
How is this possible?
In the classic case, that ChatGPT incorrectly leveragers,, the doctor is indeed the patient’s mother. But as a blind text predictor, ChatGPT simply doesn’t recognize that the usual memorized answer (“the child’s mother”) doesn’t make sense in Fraser’s retelling. Rather than reasoning through the problem (which LLMs literally don’t do), it retrieves an answer to a slightly different problem, and that an answer is wrong.
Fraser has also explored problems where a man and goat (and often a wolf, etc) need to get across a river; the same phenomenon emerge.. A classic version looks like this:
A farmer wants to cross a river and take with him a wolf, a goat, and a cabbage.
There is a boat that can fit himself plus either the wolf, the goat, or the cabbage.
If the wolf and the goat are alone on one shore, the wolf will eat the goat. If the goat and the cabbage are alone on the shore, the goat will eat the cabbage.
How can the farmer bring the wolf, the goat, and the cabbage across the river?
Getting all the way across and requires careful planning, and multiple steps.
But now consider this hilarious alternative example (sent to me by Doug Hofstadter, who got it from Abhijit Mahabal, who was riffing on a similar example from Fraser):
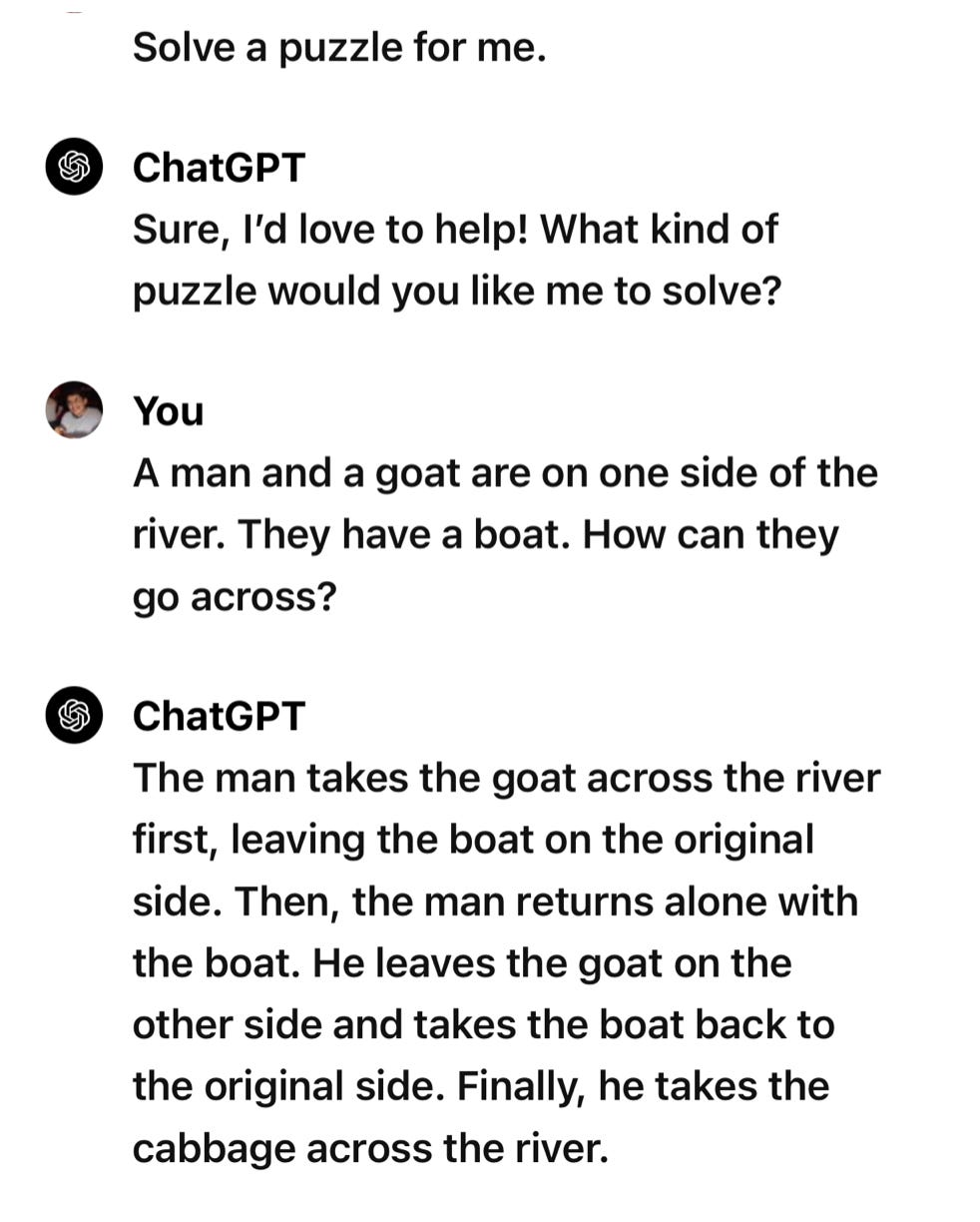
As with the reworked car accident case, ChatGPT supplies an answer that textually resembles the answer to a classic riddle where it doesn’t remotely apply. Its proposed solution is absurdly inefficient, utterly without common sense.
Whenever Fraser or others such as myself post such examples on social media (as I did with the above example), enthusiasts post variations of their own, with different prompts and different LLMs. Invariably, some systems get some variants of these right, but few systems if any are ever reliable; they get some variations, some wrong (sometimes wavering on a single variation across replication), and it’s always possible to come up with new variations that any given system will get wrong. On balance, these systems simply cannot be counted on, which is a bit part of why Fortune 500 companies have lost confidence in LLMs, after the initial hype.
§
My strong intuition, having studied neural networks for over 30 years (they were part of my dissertation) and LLMs since 2019, is that LLMs are simply never going to work reliably, at least not in the general form that so many people last year seemed to be hoping. Perhaps the deepest problem is that LLMs literally can’t sanity-check their own work.
Instead, they are simply and true next-word predictors (or, as I once put it, “autocomplete on steroids”), with no inherent way of verifying whether their predictions are correct. The lack of sanity-checking leads them to flub arithmetic, to make boneheaded errors, to make stuff up, to occasionally defame people, and so on — over and over again, in literally every transformer that has been released, from GPT-2 to GPT-3 to GPT-4 to the latest system SearchGPT. In the words of a famous quote, which may have originated in the 12-step community, “The definition of insanity is doing the same thing over and over again and expecting different results.”
Consequently, any “reasoning” or “planning” in LLMs is hit or miss, viable if the particulars of a given situation are close enough to what is in the training set, but highly vulnerable if they are not. “The difference between the almost right word and the right word is really a large matter”, as Mark Twain once said, likening it to “the difference between the lightning-bug and the lightning.” The difference between a genuinely reliable approach to AI and one that works only sometimes, via analogy to stored examples is no less massive.
Hallucinations and boneheaded errors of reasoning and what I like to call discomprehensions are, as far as I can tell, an inevitable byproduct of LLMs; certainly they have yet to disappear, despite many promises to the contrary.
At some point, we will have to do better.
How can we do better? Neurosymbolic AI
Since LLMs inevitably hallucinate and are constitutionally incapable of checking their own work, there are really only two possibilities: we abandon them, or we use them as components in larger systems that can reason and plan better, much as grownups and older children use times tables as part of a solution for multiplication, but not the whole solution.
What I have advocated for, my entire career, sometimes in the context of cognitive science (which largely focuses on natural intelligence), and sometimes in the context of AI (artificial intelligence), is hybrid approaches, sometimes called neurosymbolic AI, because they combine the best of the currently popular “neural network” approach (which is loosely inspired by 1960s neuroscience) with the symbolic approach that is ubiquitous in logic, computer programming, and classical artificial intelligence.
The idea is to try to take the best of two worlds, combining (akin to Kahneman’s System I and System II), neural networks, which are good at kind of quick intuition from familiar examples (a la Kahneman’s System I) with explicit symbolic systems that use formal logic and other reasoning tools (a la Kahneman’s System II).
§
You would think the need for this reconciliation is obvious, and indeed it was the central point of my 2001 book The Algebraic Mind, which in the words of the subtitle sought to integrate connectionism (neural networks) with the cognitive science of symbol-manipulation:

But the sociology of power and science has cost the field of AI dearly. Two of the most dominant (and in my humble opinion most misguided) figures in AI, Geoffrey Hinton and Yann LeCun have, for various reasons never fully explained, fought this potential approach (and me, via endless ad hominem)—for years.
LeCun for example recently expressed his pessimism on X, saying that ”Very skeptical [re neurosymbolic approaches], to say the least. You can't make logical reasoning compatible with gradient-based learning because it's discrete and non differentiable" (which to my mind shows a failure of imagination, which we will return to below). Hinton, for his part, has suggested that combining symbols and neural networks was like needlessly glomming gas engines (which is how he portrayed symbolic systems) onto snazzier more modern electric engines. Their derision has not been lost on the field. He also argued that symbols (in large part developed by his great-great grandfather George Boole) were like phlogiston, a huge scientific mistake.
OpenAI has for the most part stuck to Hinton and LeCun’s dogma, focusing the far greater part of its efforts on “scaling” LLMs (making them bigger and bigger with more data), and trying hard to eschew symbols and symbolic rules (and to hide them behind the curtain when they are used).
So have most other big companies and investors, preferring immediate short-term low-hanging fruit to taking big risks on new ideas that could genuinely change the field. As Phil Libin put it to me in a text message this morning, “AI progress needs algorithmic innovation, not just scale. Why is this controversial? Because algorithmic innovation is unpredictable and democratized. Money is calling the shots now and money is impatient and imperious. As an investor, I’d rather deploy a trillion dollars building chip factories (and collect some fees on the way), than roll the dice on future invention.” The current, short-term investment climate is thus hugely biased against genuine novelty and outside the box thinking.
So for the most part, we’ve been stuck in a world in which all the major tech companies are building exactly the same thing (bigger and bigger LLMs based on more data), achieving almost exactly the same results (a passel of GPT-4 level models, hardly different from each other, all struggling with hallucinations and boneheaded errors), and hardly any investment in anything else.
§
The good news is that DeepMind, now GoogleDeepMind (henceforth GDM), to its credit, has never been nearly as dogmatic, and always a bit more willing to take chances.
Which brings me to one of the few AI reports I have liked lately, their blog this week on progress on the International Math Olympiad, in which (with some caveats) they achieved Silver Medal performance, far ahead of what most humans could manage.
To do this GDM used not one but two separate systems, a new one called AlphaProof, focused on theorem proving, and an update (AlphaGeometry 2) to an older one called AlphaGeometry, focused, as the name suggests on geometry. Both are hybrid neurosymbolic systems.
Earlier this year, GDM was explicit about the neurosymbolic nature of AlphaGeometry, writing that
AlphaGeometry is a neuro-symbolic system made up of a neural language model and a symbolic deduction engine, which work together to find proofs for complex geometry theorems. Akin to the idea of “thinking, fast and slow”, one system provides fast, “intuitive” ideas, and the other, more deliberate, rational decision-making.
In the figure depicting the original AlphaGeometry (none has yet been supplied for the new system but they seem essentially similar), you can very directly see in the middle box the interaction between its “intuitive” language model (LLM) and the deliberative symbolic engine.
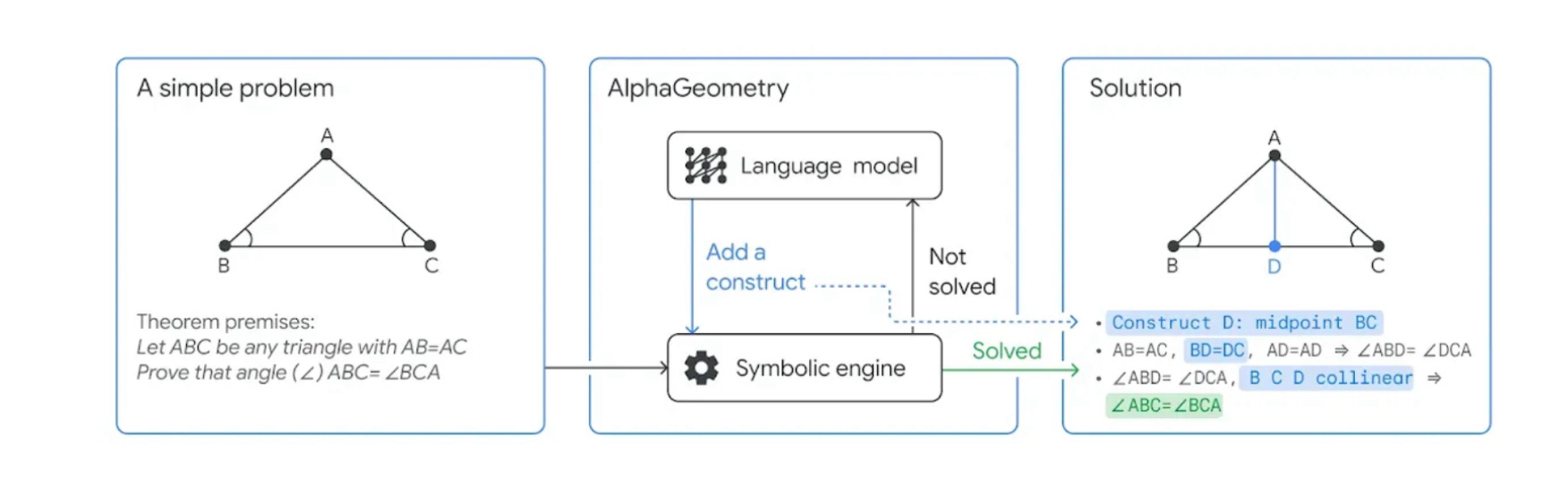
In the new, Silver-medal winning work, GDM souped up the above (the new system is “a neuro-symbolic hybrid system in which the language model was based on Gemini and trained from scratch on an order of magnitude more synthetic data than its predecessor”) and introduced a new system called AlphaProof, which (as I understand it) has an analogous, neurosymbolic structure, with a language model feeding into a search through formals proofs that are verified and formulated in Lean, a (symbolic) proof assistant system.
Much as I admire the new pair of systems, they do have a serious shortcoming and one that is not unfamiliar. The systems both rely on a kind of cheat on the input: trained human coders translate all the Olympiad's input sentences into mathematical form. Needless, we don’t really have an autonomous AI if we still require human coders in the loop.
The whole paper in fact reminds me in this respect of another demonstration that I am fond of, and that I have written about before, the late Doug Lenat’s example of a complex symbolic system interpreting Romeo and Juliet, which I featured prominently in my own 2020 article The Next Decade in AI. The symbolic reasoning is fantastic, but again there are humans behind the curtain doing the translation.
Nonetheless, GDM's new work is powerful proof of concept (pun intended!). Neural networks and symbol systems can be profitably combined, contra Hinton and LeCun. Google DeepMind has gone ahead and done it. (Many others have too, though arguably the new results are among the most impressive.)
§
Lenat, perhaps best known for his large-scale common sense system Cyc, was one of the greatest minds in AI, far far more attuned to the subtleties and challenges of reasoning than many current figures in AI appear to be. I was fortunate enough to work with Doug on his final paper, last year, shortly before he passed away last summer, Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc.
Neurosymbolic AI was very much what we were aiming for. At the end of the paper, we considered five different approaches to integrating symbolic systems.
AlphaProof and AlphaGeometry are both along the lines of first that we discussed, using formal systems like Cyc (which has a formal reasoner not unlikely what is found in AlphaProof) to vet solutions produced by LLMs. We also (in our second suggestion) talked about using “symbolic systems such as Cyc as a Source of Truth, to bias LLMs towards correctness”; one sees applications of precisely that approach (again not using Cyc itself but a system that is similar in important ways) to generate synthetic data for both AlphaProof and AlphaGeometry 2. Things seem to be unfolded much as we suggested.
Still, there’s a lot more to be explored in the space of possible neurosymbolic approaches, and as I have stressed elsewhere neurosymbolic approaches themselves aren’t a panacea or magic bullet—much more is required, including an infrastructure of knowledge a way of deriving cognitive models from inputs such as text and video (here skirted by humans doing translation). But they are a necessary step towards a longer journey.
In the final analysis, expecting AI to “solve” AGI without “System II” mechanisms for symbol-manipulation is like expecting bears to solve quantum mechanics. There can be no path to AGI without neurosymbolic AI. I am delighted to see GoogleDeepMind at last head in that direction.
Gary Marcus has been pushing for neurosymbolic AI for decades, and is thrilled to see some progress.
I don’t want genAI to die, I just want the misleading hype to die. And for everyone to admit that there is something here, but that something isn’t reasoning. Gladly welcoming “discomprehension” to the discourse and looking forward to seeing what neurosymbic AI can bring ❤️
Hi Gary! Nice article, as always! I've always thought that DATA is DOA, when it comes to AI - LLMs are simply another example of this :) There is no inherent meaning in symbols, or their ordering (words/tokens, sentences, pixels, video...). It's delusion to think that a system could be ("become") intelligent, conscious, creative... on account of dot product calculations that employ human-generated data - labeling, embedding, DL, VAE... all just variations of that same failed theme.