BREAKING: The AI 2027 doomsday scenario has officially been postponed
The good news is that you can rest more easily; the bad news is we have been building our world around a fantasy

It’s official. The widely-discussed AI 2027 scenario, named-checked by Vice President Vance, lauded by The New York Times, and panned by me —you know the one in which AGI is reached in 2027 and in short order kills us all—has officially been postponed, by its co-creator:
The White House Senior Policy Advisor Sriram Krishnan took note, and is frankly pissed that he was sold a bill of goods:
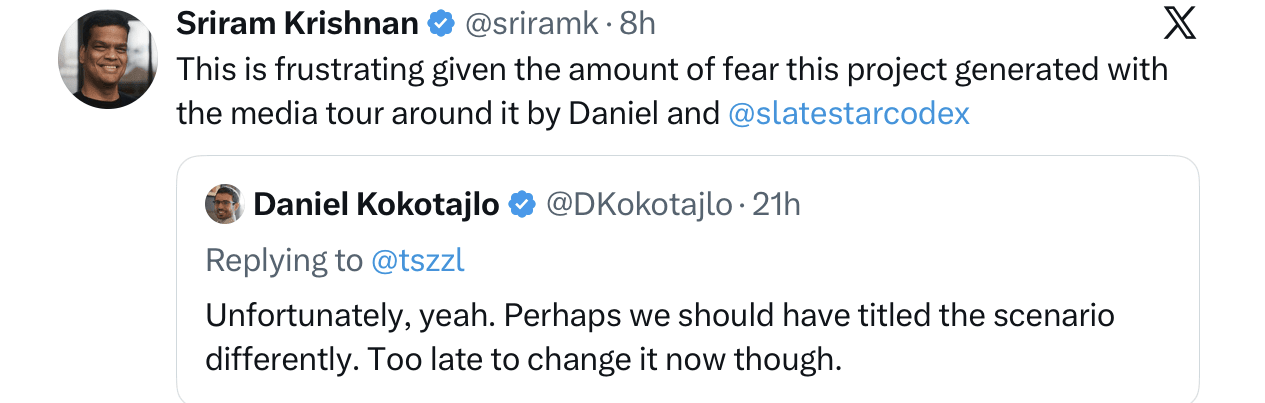
In reality, the problems with the report should have been clear at the time. As I wrote here then, “I honestly wish, though, that [the AI 2027 report] wasn’t being taken so seriously. It’s a work of fiction, not a work of science… stoking fear, uncertainty and doubt”, adding that “The logic for their prediction that “superhuman AI over the next decade will exceed the Industrial Revolution”, though, is thin”. The core was this:
“[AI doomsday in 2027] is a conceivable scenario; there is probably some very small probability that the future of AI and humanity could go exactly like what they describe. But there is a vastly higher probability that the future won’t transpire as described; it might not go anything at all like what they describe”
§
As far I can tell, The White House is getting its cues from the podcast crowd (All-In, Dwarkesh, Lex, Hard Fork, etc), and those guys refused to allow me to voice a rebuttal. They were all in on AI 2027, with very little dissent acknowledged, much less aired. Many of the essay’s talking points have resonated in Washington’s talking points.
Sam Altman probably lapped every minute of it. As I wrote at the time:
materials like [AI 2027] are practically marketing materials for companies like OpenAI and Anthropic, who want you to believe that AGI is imminent, so that they can raise astoundingly large amounts of money. Their stories about this are, in my view, greatly flawed, but having outside groups with science fiction chops writing stuff like this distracts away from those flaws, and gives more power to the very companies trying hardest to race towards AGI
But here we are. AGI ain’t actually coming in 2027, and even Kokotajlo, known for his aggressive timelines, is now with me in thinking we probably won’t see AGI this decade.
A LOT of things need to be reconsidered, economically, intellectually, and politically. I will spell this out more in a later essay.
Suffice for now to say that we have built (and continue to build) our entire national policy (such as it is) around an idea that was never grounded in a sound analysis of AI. AGI is NOT in fact coming in Trump’s second term, and never was.
And it’s not just our policies that need to be rethought, but also our entire economy, which is being rebuilt at enormous expense around a myth.
Much needs to be reconsidered, including what we should do now, given more realistic timelines. But also how and why so much critical decision-making revolved around sheer speculation—and why dissenting voices were not taken seriously.
When I learned that an LLM is simply an average of the Internet, I knew it could be nothing more EVER than a large but shallow pool of mediocrity.
That benchmark is so absurd. How well an LLM does on coding tasks has everything to do with what it’s been trained and fine tuned on. Putting time to complete task on the y-axis is silly.
Coding LLMs are all fine tuned on popular stacks (ex: React/Next, Tailwind, FastAPI) and common patterns, so you can have an LLM cook up a React component that would have taken a dev a few days, even weeks or months, as long as what you need isn’t too far away from the training distribution (think drop downs, profile pages, comment sections, CRUD endpoints, ect). If not, then it’s mostly garbage code that will need to be rewritten.
It’s also quite hard to tell where the edge of the distribution is. In my experience I’ve been surprised how many basic tasks Claude Code falls apart on.
Of course the irony is that if you don’t know what you’re doing (most vibe coders don’t) then you’ll be generating code much lower quality than the equivalent open source library and taking way longer to get it working right.
Even the idea that you can accurately measure the time a coding task will take is laughable to any professional software engineer. SWE work isn’t like construction, it’s very hard to estimate timing.