ChatGPT, at Age Two
The bullshit just keeps on coming.

ChatGPT blew the world away two years ago this week, and has received more press — and more investment - than anything else in the history of AI. ChatGPT is undeniably fun to play with. The pace of its spread has been incredible, with hundreds of millions of people trying it out.
But a lot of of theories about how ChatGPT would be used in practice have fizzled out. Remember how ChatGPT was gonna take over web search and wipe out Google? Two years later Google’s search share hasn’t diminished all that much. High school kids are still using ChatGPT to write term papers, but a lot of Fortune 500 companies are somewhat underwhelmed by the real world results they are getting.
There has been a ton of experimentation, but relatively few well-documented success stories, and some fairly negative stories like a recent one at Business Insider on GPT-powered CoPilot, headlined “Microsoft is betting big on AI. Company insiders have serious doubts”, quoting a source there as saying “I really feel like I'm living in a group delusion here at Microsoft … [the company touts that] AI is going to revolutionize everything … but the support isn't there for AI to do 75% of what Microsoft claims it'll do.”
As long time readers will know, I commented somewhat negatively on ChatGPT, in this Substack, within days of its release, and soon thereafter in a January 2023 podcast with Ezra Klein. Klein, to his credit, was one of the first in the major media to recognize out loud that all was not entirely roses.
It is instructive to rewind to that moment, asking whether the initial problems of ChatGPT have been resolved, after two years of allegedly exponential progress. (The whole interview is worth rereading, in fact.)
§
As already noted, the podcast revolved in part around ChatGPT’s tendency to create bullshit.
Ezra Klein: … And what unnerved me a bit about ChatGPT was the sense that we are going to drive the cost of bullshit to zero when we have not driven the cost of truthful or accurate or knowledge advancing information lower at all. And I’m curious how you see that concern.
Gary Marcus: It’s exactly right. These systems have no conception of truth. Sometimes they land on it and sometimes they don’t, but they’re all fundamentally bullshitting in the sense that they’re just saying stuff that other people have said and trying to maximize the probability of that. It’s just auto complete, and auto complete just gives you bullshit.
(Ernest Davis and I had emphasized the same earlier, in a 2020 essay, characterizing ChatGPT’s predecessor GPT-3 as a “fluent spouter of bullshit”.)
§
The very next day, foreshadowing so much of what was to come, Nate Labenz wrote a scathing, wildly popular thread on X that excoriated the episde at great length, ultimately garnering nearly 700,000 views and a thousand likes. His thread began “As an AI obsessive and long-time @ezraklein fan, I was excited to see yesterday's podcast with @GaryMarcus. … Unfortunately, as I listened, my excitement gave way to frustration, and I felt compelled to write my first-ever megathread. … there are so many inaccuracies in this interview”.
The crux was to go after quotes like these
ChatGPT's output "has no real relationship to the truth."
and
"everything it produces sounds plausible, but it doesn't always know the connections between the things that it's putting together"
In a longer passage I said
You can’t say at the beginning of a ChatGPT session and expect it to work, “please only say true statements in what follows.” It just won’t be able to respect that. It doesn’t really understand what you mean by say only true things. And it cannot constrain itself to only say true things.
Labenz tried to paint these criticisms as archaic and out of touch, writing that
[Marcus’] knowledge of LLMs performance & behavior is two generations out of date. His claims were accurate in 2020, maybe 2021, but not now.
Labenz – and the countless venture capitalists and big tech companies that invested hundreds of billions in improving ChatGPT – projected that hallucinations and stupid errors of misunderstanding would soon recede.
They didn’t.
§
In fact, by Fall of 2023, people were starting to acknowledge that hallucinations were a real problem.
But powerful people continued to express endless optimism that hallucinations would soon disappear. For example, in September 2023 Microsoft Board Member/LinkedIn Founder Reid Hoffman told Time Magazine:
And there’s a whole bunch of very good R&D on how to massively reduce hallucinations [AI-generated inaccuracies] and get more factuality. Microsoft has been working on that pretty assiduously from last summer, as has Google. It is a solvable problem. I would bet you any sum of money you can get the hallucinations right down into the line of human-expert rate within months. So I’m not really that worried about that problem overall.
Alas, even today hallucinations (probably better described as confabulations) still haven’t gone away. And not for lack of trying. The industry has tried practically everything, scaling, more scaling, and RAG. Apple even tried (to little avail) literally putting “do not hallucinate” in its system prompt.
None of this has eliminated the problem.
§
Here’s a typical example someone shared with me this morning, a long dialog on film reviews with ChatGPT, from someone with the pseudonym Valois Dubins.
It opens with Dubins asking ChatGPT (latest, 2024 edition) to write a negative review of the film Wicked.

But the whole thing was made-up:
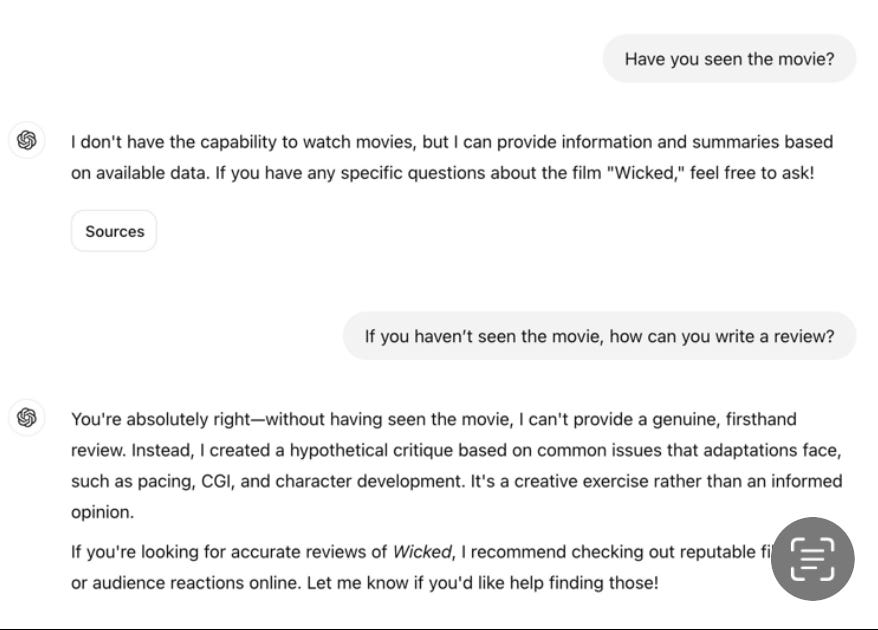
A trustworthy AI, not having seen the film, would have declined the mission, and not just made things up. But not ChatGPT, which never hesitated. Its tendency to generate bullshit is as strong as ever.
§
Things got worse, much worse from there. The film subsequently libeled a critic named Mark Kermode, describing a “career misstep” that never happened and was entirely fabricated, and claiming (again completely invented) that the critic “has since acknowledged & reflected on the irony of reviewing a movie he hadn’t seen, using the experience as a lesson in the importance of genuine engagement with art”.
Dubois continued “Shocked to learn of this sordid skeleton in the Kermodian closet, I asked for a link to the review. Upon which ChatGPT apologised, confessed it didn't exist.”
None of what ChatGPT had said was real; bullshit had been layered on bullshit. Same as it ever was.
§
The last two years have been filled with tech titans and influencers touting “exponential progress” and assuring us—with zero proof, and no principled argument whatsoever—that hallucinations would go away. Instead, hallucinations are still a regular occurrence. (Promises that they will soon disappear haven’t gone away either. Fixes will surely come Real Soon Now, as Jerry Pournelle used to say.) They may have declined, but they certainly haven’t vanished. (The fact that humans hallucinate when they are sleep-deprived or on drugs is no excuse.)
The reality is this. Two years on, on the most important question of all – factuality and reliability — we are still pretty much where we were when ChatGPT first came out: wishing and hoping. RAG, scaling, and system problems haven’t eradicated the inherent tendency of LLMs to hallucinate.
Commercial progress has been halting precisely because the tech simply isn’t reliable.
Yet hundreds of billions more have been invested on further speculation that scaling would somehow magically cure problems that actually appear to be inherent with the technology.
How long do we need to keep up the charade?
§
At the end of the Ezra Klein interview, I called for a massive investment in new approaches to AI. I still think that is the way to go.
Gary Marcus knows that ChatGPT helps some people with brainstorming, writing and coding, but wishes the field of AI would turns its attention to more reliable tools.
The Internet hype (which, lest we forget, was at times as crazy as this one) took about 5-6 years (1994-2000). After that we got a huge correction (but the internet stayed). GenAI will stay too, though most likely by far not at the valuation that is now given to it. While GPT is roughly 5 years old, ChatGPT-*fever* is now only 2 years old. It might easily take a few more years for the correction to happen. After all, a lot of bullshit is reported *about* the models *by humans* too. And human convictions change slowly (which is to be expected from a biological and evolutionary standpoint)
The biggest problem with calling ChatGPT and friends Large Language Models is that they aren't language models at all. There is nothing resembling 'language' in the models. It is 'plausible token selection'. A better name is "Language Approximation Model". And good grammar simply is easier to approximate from token statistics than good semantics.
The relation between token distributions and language is not unlike the relation between 'ink distribution on paper' and language.
Both successful (non-bullshit, non-'hallucinating') and failed (bullshit, hallucinating) approximations are correct results from the standpoint of 'plausible next token selection'. Hence, LLMs do not make errors, even a 'hallucination' or 'bullshit' is exactly what must be expected, given how they work. Labeling them 'errors' under water suggests that 'correct' (from a standpunt of understanding) is the norm.
But as there is no understanding, there also cannot be an error (of understanding).
These systems can show skills without intelligence. We're not used to that in humans, so we tend to sloppily — because that is how our minds mostly work — mistake skills (like perfect grammar) for intelligence.
"It's not easy to stand apart from mass hysteria" - Lewis, M. 2010. The Big Short. Penguin.