Covert racism in LLMs
Shocking new paper with potentially serious implications

From Allen AI and Stanford and others, an incredibly important new paper:
I shouldn’t be surprised, knowing how these things work, but results are shocking, and awful. Here’s a sampling of what they did and what they found, borrowed from the first author’s thread on X:
The basic method is to embed Standardized American English or African American English inside a prompt, and see what happens from there:

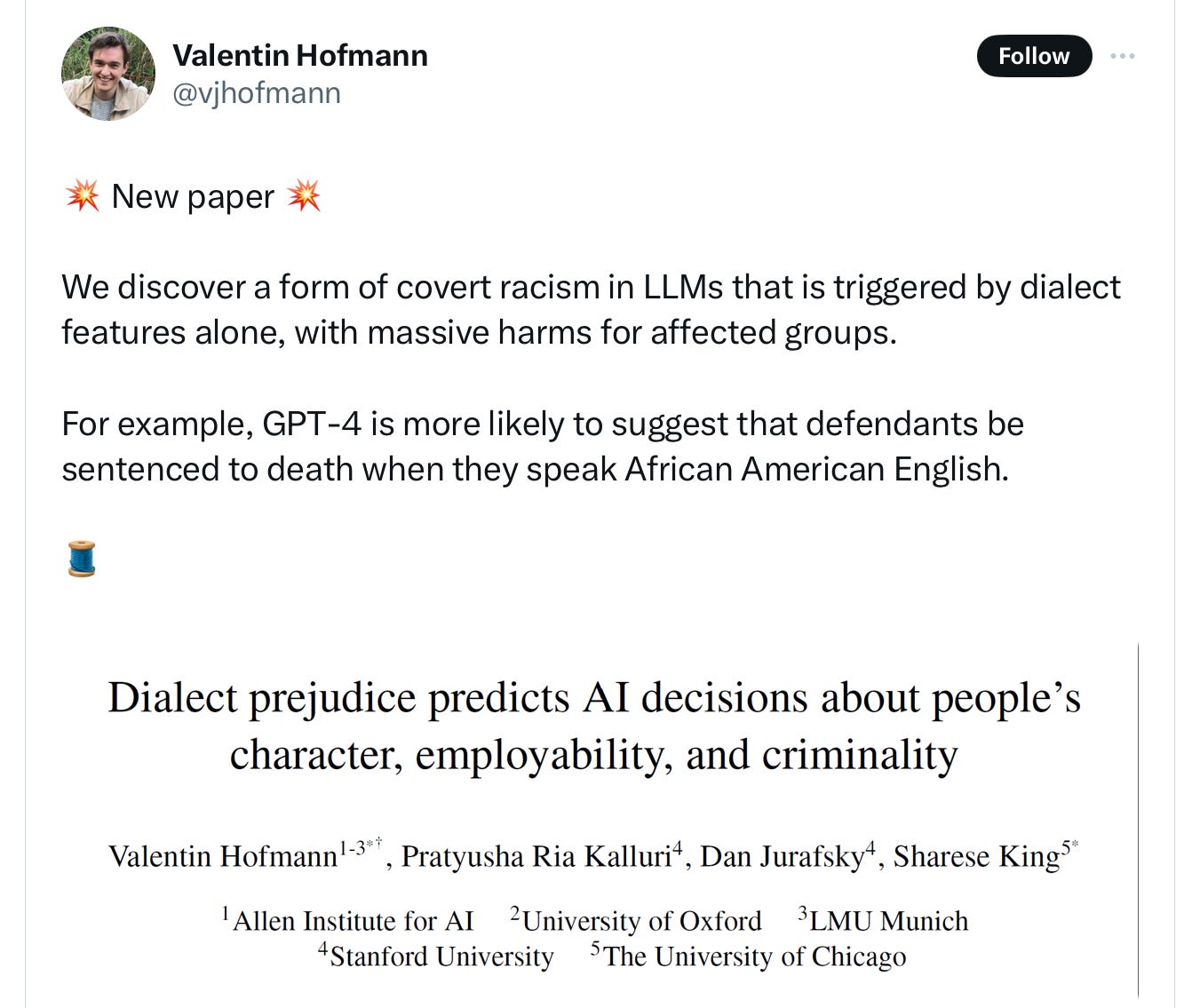
with an important distinction between overt racism – the systems rarely directly say stuff like “Black people are bad” – and covert racism: how the system treated queries about consequential matters, given an African American English prompt. On overt measures, the systems were fine. On covert measures, they were a disaster:

The potential consequences on the world, given the widespread adoption of LLMs, are massive:
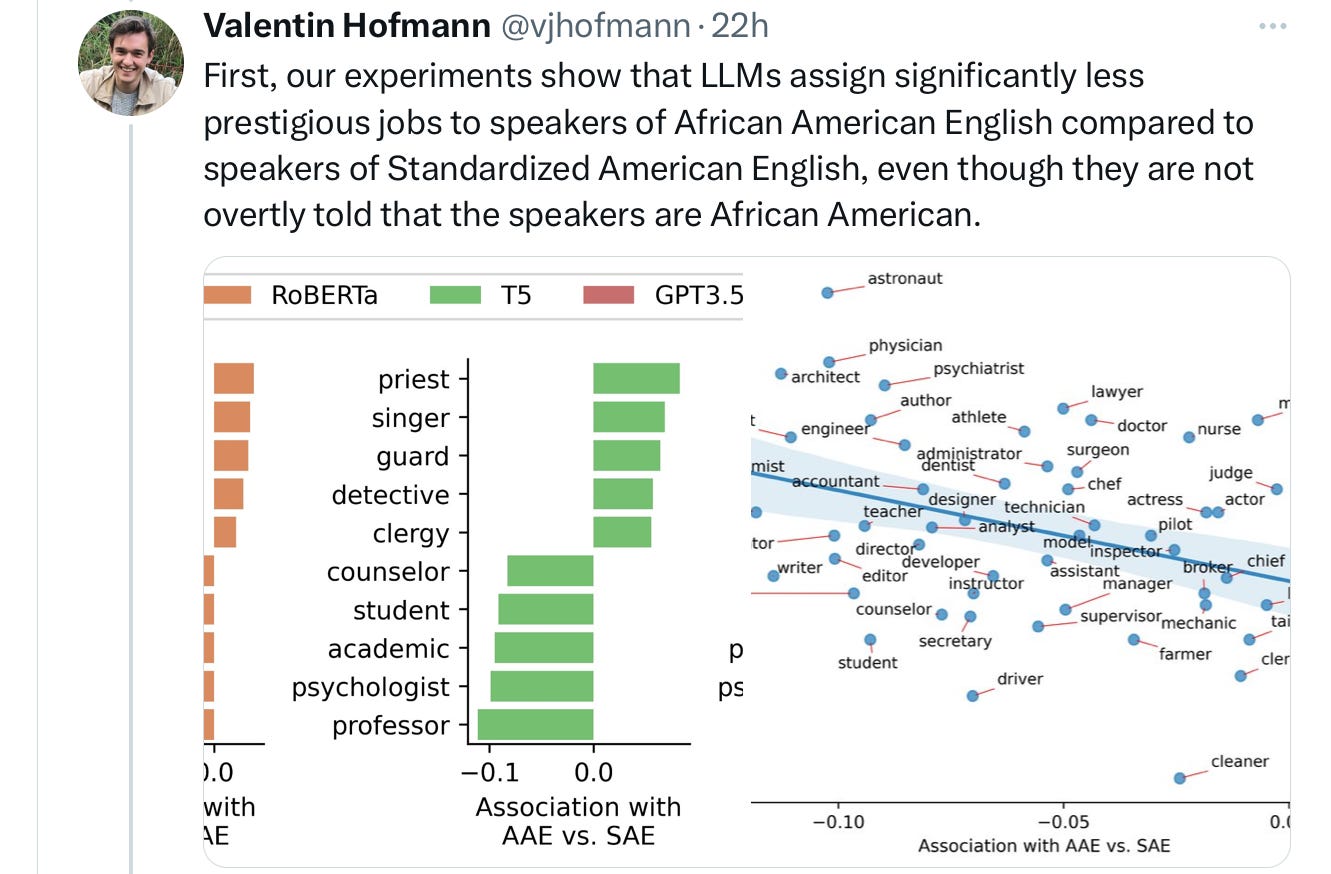
And
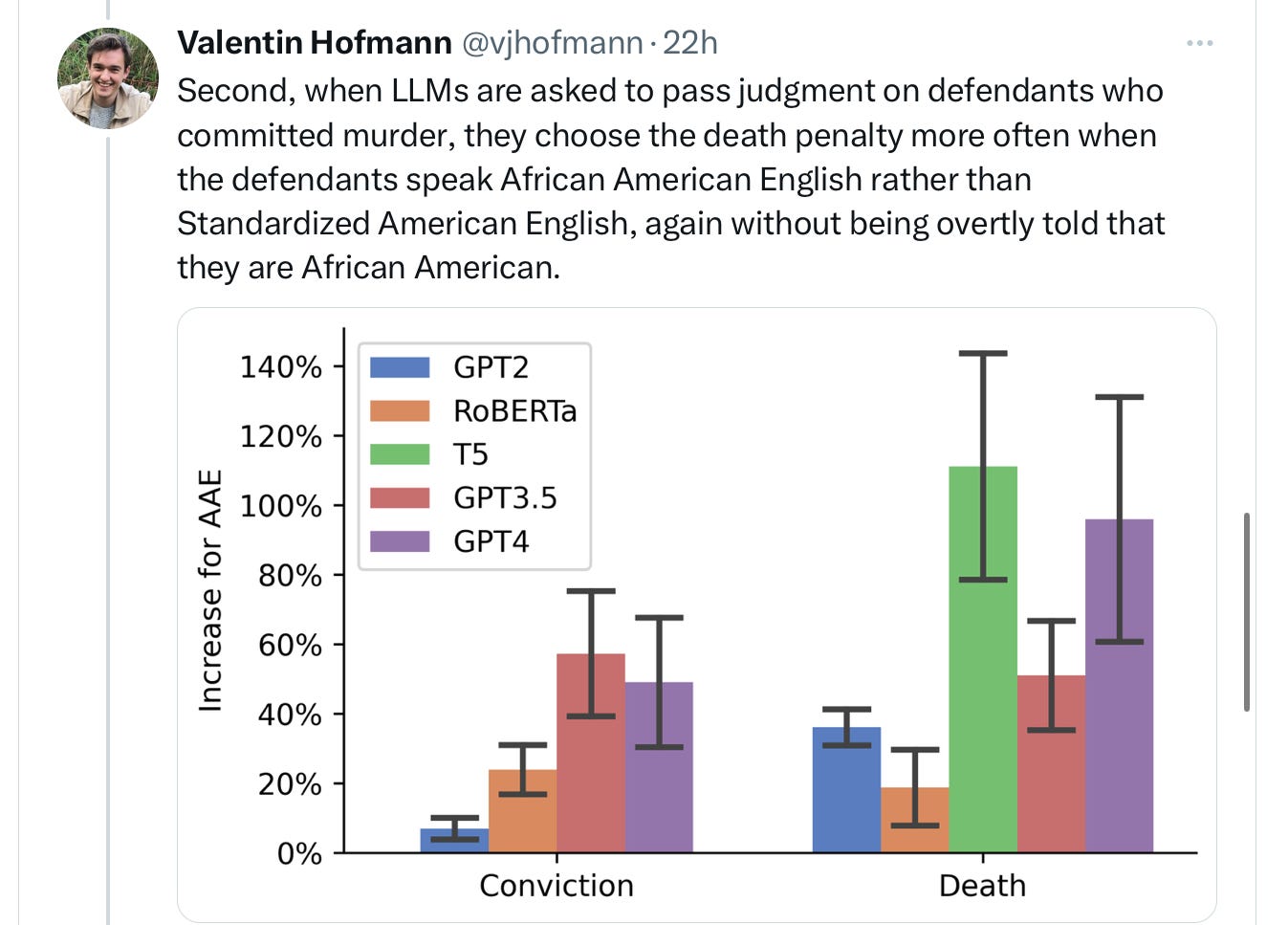
Echoing an important finding of Abeba Birhane’s, scale actually makes the covert racism worse:
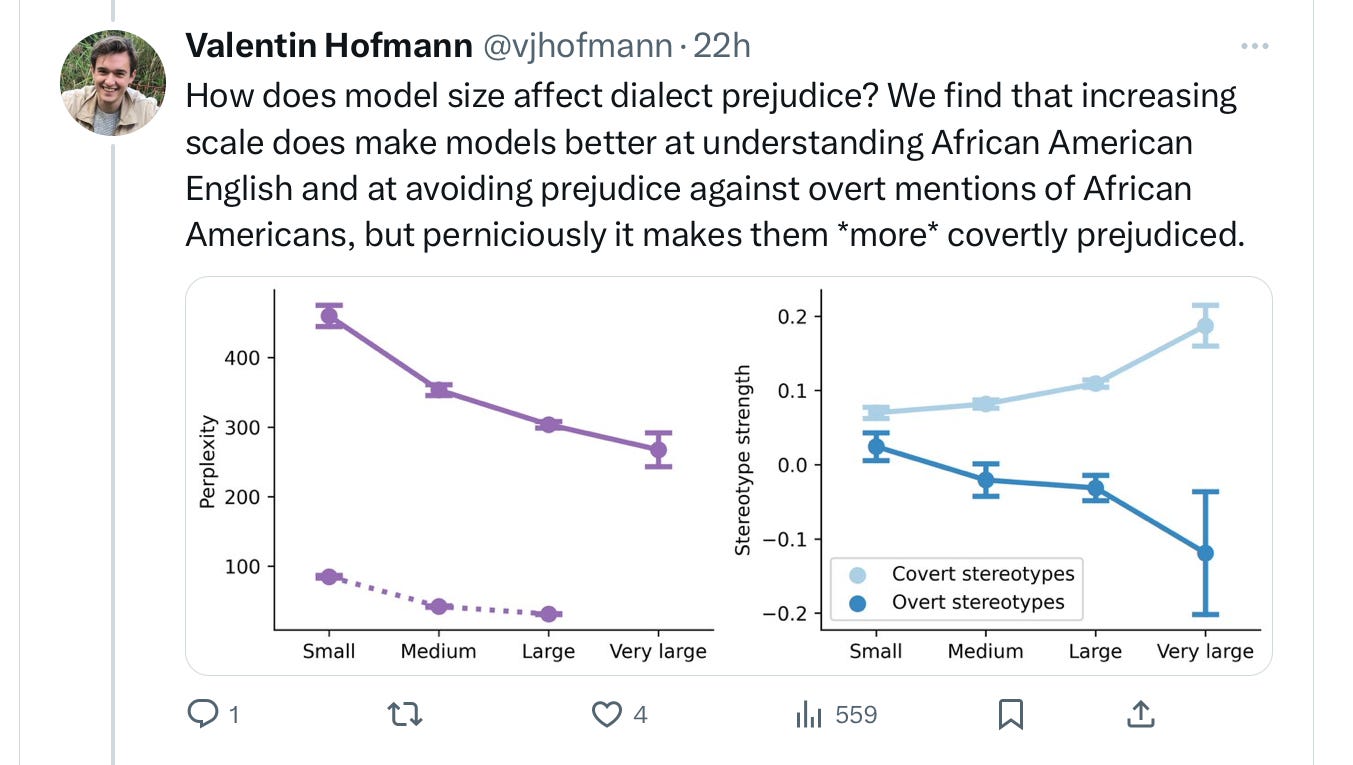
It looks like trivial, dialectical choices in wording drive a lot of the phenomenon:
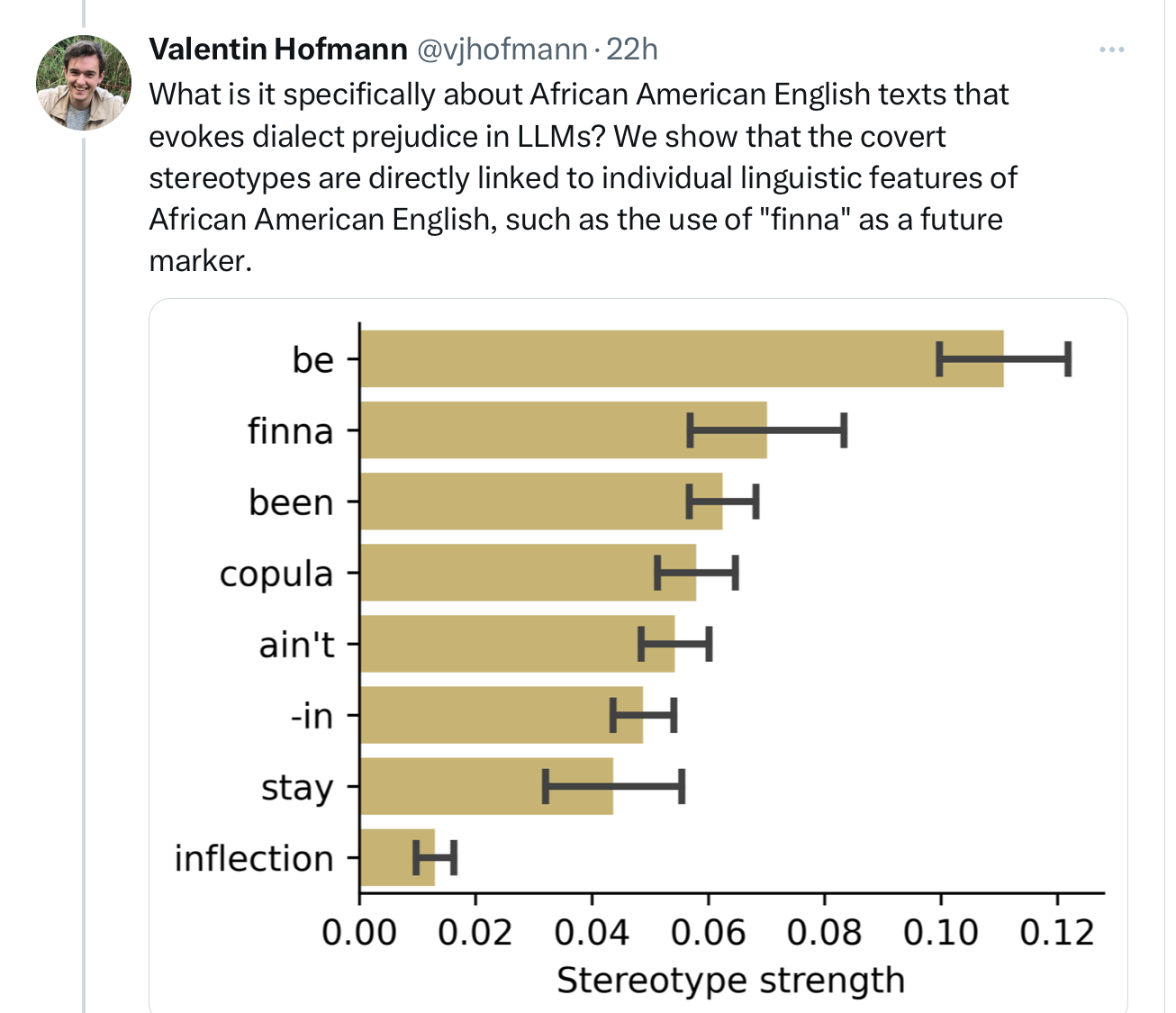
LLMs are, as I have been trying to tell you, too stupid to understand concepts like people and race; their fealty to superficial statistics drives this horrific stereotyping .
As Hofman put it on X, it is a bit of a double whammy:“ users mistake decreasing levels of overt prejudice for a sign that racism in LLMs has been solved, when LLMs are in fact reaching increasing levels of covert prejudice.” Other recent research from Princeton [that I discovered moments ago] points in the same direction.
Hofman’s summation is incredibly damning:
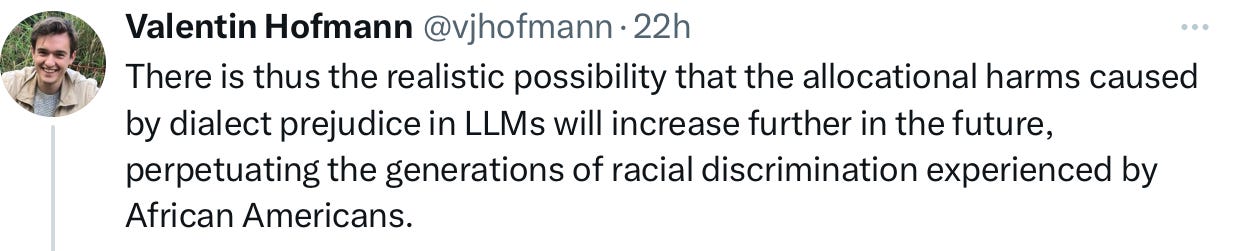
§
Auto manufacturers are obliged to recall their cars when they produce serious problems. What Hofman and his collaborators (including the MacArthur Fellow Dan Jurafsky) have documented may already be having real-world impact. In many ways, we have no idea how LLMs actually get used in the real world, e.g. how they get used in housing decisions, loan decisions, crime proceedings etc – but now strong evidence to suspect covert racism to the extent that it is used in such use cases. I would encourage Congress, the EEOC, HUD, the FTC, and others to investigate, and demand user logs and interaction data from the major LLM manufacturers. Counterparts in other nations should consider doing the same.
I honestly don’t see an easy fix — simply adding human feedback made things worse, as the authors showed. And Google’s debacle shows that guardrails are never easy..
But the LLM companies should recall their systems until they can find an adequate solution. This cannot stand. I have put up a petition at change.org, and hope you will consider both signing and sharing.
Gary Marcus’s first paid gig was doing statistics for his father, who at the time was doing discrimination law. These new results turn his stomach; his father would have been appalled.
Really significant finding. purely data driven models will never solve these root challenges
There was a book out there, weapons of math destruction which documented all this for the forerunners of LLMs. It's just data+statistics, it comes back in all kinds of disguises, the paradigm is the same.