David beats Go-liath
Apparently “superhuman” intelligence, even in limited domains, isn’t always what you think

In March 2016, to much fanfare, AlphaGo beat Go world champion Lee Sedol, convincingly, in a 5 game match, 4 to 1. Computers have only gotten faster since then; one might have thought that the matter was settled. And of course computers have only gotten faster ever since.
And then … something unexpected happened, just reported in the Financial Times:


And the human that won wasn’t even a professional Go player, let along a World Champion, just a strong amateur named Kellin Pelrine. And the match wasn’t even close; Pelrine beat a top AI system 14 games to 1, in a 15 match series. Almost seven years to the day after AlphaGo beat Sedol.
As shocking as that might initially seem, we should not to be totally surprised. Seven years of AI has taught us that deep learning is unpredictable, and not always human like. “Adversarial attacks” like these have shown remarkable weakness, time and again, repeatedly establishing that what deep learning systems do just isn’t the same as what people do:
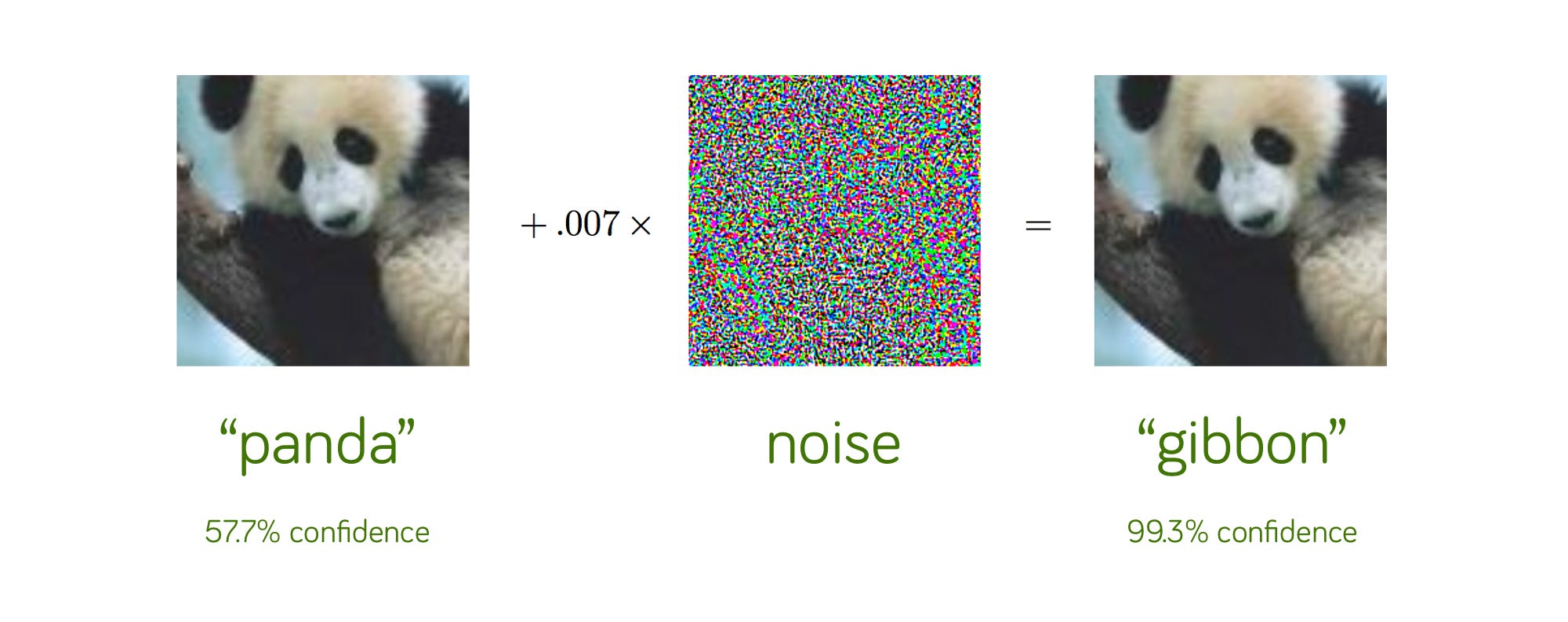
Partly for that reason, I always wondered whether AlphaGo really and deeply understood Go, or whether it was relying in part on massive data without true depth. In particular I wondered how well it would generalize to weird styles of play outside its training set, to the kind of edge cases that have plagued driverless cars and chatbots.
Late last year, a Berkeley PhD student, Adam Gleave, working with the eminent Berkeley computer scientist Stuart Russell, discovered a specific way to fake out two of the better Go programs:

As Gleave explains
Even more strikingly, the out-of-the-box strategy beat KataGo, but it didn’t make for a good strategy against a strong human:

In a DM in November, Gleave told me “We first came up with a hand-constructed adversarial board state that KataGo totally misevaluated, which convinced us that it has some major blindspots. After that finding an attack wasn't that hard.”
§
The just-reported showdown shows that Gleave’s strategy was no fluke; he was able to teach it to Pellrine (a Go-playing co-author on the paper), and Pellrine carried it to the finish line.
Pellrine’s victory is a profound reminder that no matter how good deep-learning-driven AI looks when it is trained on an immense amount of data, we can never be sure that systems of this sort really can extend what they know to novel circumstances. We see the same problem, of course, with the many challenges that have stymied the driverless car industry, and the batshit crazy errors we have been seeing with chatbots in the last week.
All of these stumbles together serve as a poignant reminder that “deep learning” is still (just) a technical term describing a number of layers in a neural network, and not a technique that at all entails conceptual depth.
As Stuart Russell put it, speaking to the Financial Times, the Go victory shows that “ once again we’ve been far too hasty to ascribe superhuman levels of intelligence to machines”.
Amen.
Gary Marcus (@garymarcus), scientist, bestselling author, and entrepreneur, is a skeptic about current AI but genuinely wants to see the best AI possible for the world—and still holds a tiny bit of optimism. Sign up to his Substack (free!), and listen to him on Ezra Klein. His most recent book, co-authored with Ernest Davis, Rebooting AI, is one of Forbes’s 7 Must Read Books in AI. Watch for his new podcast in the Spring.
Wow. This is music to my ears because it agrees with what I've been saying for many years.
The brittleness of deep neural nets is not unlike that of the rule-based expert systems of the last century. If either of these systems is presented with a new situation (or even a slight variation of a previously learned situation) for which there is no existing rule or representation, the system will fail catastrophically. Adversarial patterns (edge cases) remain a big problem for DL. They are the flies in the DL ointment. Deep neural nets should be seen as expert systems on steroids.
The only way to get around the curse of dimensionality is to generalize. Unfortunately, DL only optimizes, the opposite of generalization. That's too bad.
Thank you for another interesting, informative and insightful article.
Again, what a beautiful example. I don't think such a trick to get outside of a ('deep') ML 'trained comfort zone' would work against more classical chess engines (like Deep Blue — which by the way also has some (less serious, probably) issues). But this is really beautiful.