
Elegant and powerful new result that seriously undermines large language models
Elegant and powerful new result that seriously undermines large language models

Wowed by a new paper I just read and wish I had thought to write myself.
Lukas Berglund and others, led by Owain Evans, asked a simple, powerful, elegant question: can LLMs trained on A is B infer automatically that B is A?
The shocking (yet, in historical context, see below, unsurprising) answer is no:

On made-up facts, in a first experiment, the model was at zero percent correct, on celebrities, in a second experiment, performance was still dismal.
Can we really say we are close to AGI, when the training set must contain billions of examples of symmetrical relationships, many closely related to these, and the system still stumbles on such an elementary relationship?
Here’s the paper; well-worth reading:

§
What the otherwise fabulous paper failed to note in its initial version is that the history on this one is really, really deep.
To begin with, this kind of failure actually goes back to my own 2001 book Algebraic Mind, which focused extensively on the failure of earlier multilayer neural networks to freely generalize universal relationships, and which gave principled reasons to anticipate such failures from these architectures. None of what I raised then has really been adequately addressed in the intervening decades. The core problem, as I pointed out then, is that in many real world problems, you can never fully cover the space of possible examples, and in a broad class of heavily-data-driven systems like LLMs that lack explicit variables and operations over variables, you are out of luck when you try to extrapolate beyond that space of training examples. Was true then, still true now.
But what’s really mind-blowing here is not just that the paper vindicates a lot of what I have been saying, but the specific example was literally at the center of one of the first modern critiques of neural networks, even earlier: Fodor and Pylyshyn, 1988, published in Cognition. Much of Fodor and Pylyshyn’s critique hovers around the systematicity of thought, with this passage I paste in below (and several others) directly anticipating the new paper. If you really understand the world, you should be able to understand a in relation to b, and b in relation to a; we expect even nonverbal cognitive creatures to be able to do that:

Forty one years later, neural networks (at least of the popular variety) still struggle with this. They still remain pointillistic masses of blurry memory, never as systematic as reasoning machines ought to be.
§
What I mean by pointillistic is that what they answer very much depends on the precise details of what is asked and on what happens to be in the training set. In a DM, Evans gave me this illuminating comparison. GPT-4 tends to gets questions like this correct, as noted in the paper

even though it can answer these
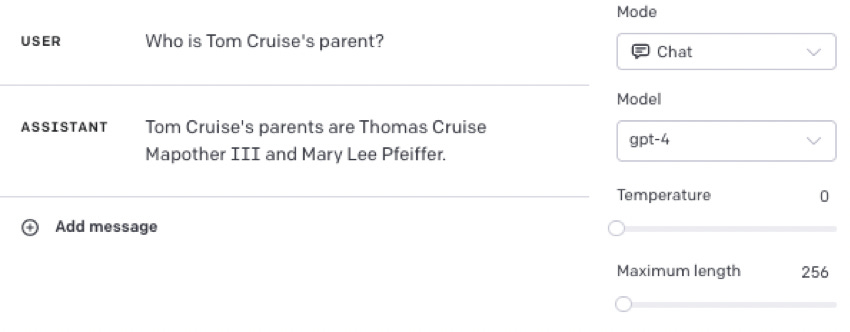
yet it can get these

As Evans summarized, models that have memorized "Tom Cruise's parent is Mary Lee Pfeiffer" in training, fail to generalize to the question "Who is Mary Lee Pfeiffer the parent of?". But if the memorized fact is included in the prompt, models succeed.
It’s nice that it can get the latter, matching a template, but problematic that they can’t take an abstraction that they superficially get in one context and generalize it another; you shouldn’t have to ask it that way to get the answer you need.1
§
My sense of déjà vu shot through the roof when I wrote to Evans to congratulate him on the result, saying I would write it up here in this Suvtack. Evans wrote “Great. I'm excited to get more eyes on this result. Some people were very surprised and thought that models couldn't have such a basic limitation.”
What struck me about people’s refusal to believe his result is that in 1998 I had a very closely-related result and very similar reaction. Neural networks of the day had a great deal of trouble generalizing identity. But I couldn’t get anyone to listen. Most people simply didn’t believe me; almost none appreciated the significance of the result. One researcher (in a peer review) accused me of a “terrorist attack on connectionism [neural networks]”; it was two decades before the central point of my result – distribution shift - became widely recognized as a central problem.
The will to believe in neural networks is frequently so strong that counterevidence is often dismissed or ignored, for much too long. I hope that won’t happen on this one.
§
In math, when one make a conjecture, a simple counterexample suffices. If I say all odd numbers are prime, 1, 3, 5, and 7 may count in my favor, but at 9 the game is over.
In neural network discussion, people are often impressed by successes, and pay far too little regard to what failures are trying to tell them. This symmetry fail is mighty big, a mighty persistent error that has endured for decades. It’s such a clear, sharp failure in reasoning it tempts me to simply stop thinking and writing about large language models altogether. If, after training on virtually the entire internet, you know Tom is Mary Lee‘s son, but can’t figure out without special prompting that Mary Lee therefore is Tom’s mother, you have no business running all the world’s software.
It’s just a matter before people start to realize that we need some genuinely new ideas in the field, either new mechanisms (perhaps neurosymbolic2), or different approaches altogether.
Gary Marcus’s most important work remains his 2001 book, The Algebraic Mind, which anticipates current issues with hallucination, distribution shift, generalization, factuality and compositionality, all still central to the field.
It’s tempting to look for cases where humans also have retrieval failures, but I would not want a calculator to answer 999.252 x 13.1 slower and less accurately than 100.000 x 13 just because a human would. Computers should be expected to make optimal use of information given, regardless of human limitations.
Bing uses some neurosymbolic supplementation to pure LLM’s, with some benefit on these type of problems, where there are known facts, but it is not yet clear how general the benefit is, and I would expect it to have trouble on the made-up facts that were used in Experiment 1.
"The will to believe in neural networks is frequently so strong that counterevidence is often dismissed or ignored, for much too long."
So true.
It is extra strong during hypes, such as the current 'GPT-fever', but it is actually a necessary basic function of human intelligence to have stable convictions and there are good reasons for this (mostly energy-efficiency and speed). But the same effect leads to people ending up in rabbit holes and conspiracy theories through confirmation bias. Such people are not crazy, they are ... human.
Human intelligence (such as that role that existing convictions play on our capacity to make observations and reasoning) is a far more interesting subject than artificial intelligence when discussing artificial intelligence :-). See https://ea.rna.nl/2022/10/24/on-the-psychology-of-architecture-and-the-architecture-of-psychology/ where this is discussed against the background of convictions and attempts to change convictions when advising (business leaders, politicians, etc.) on tech facts.
I do think "if the memorized fact is included in the prompt, models succeed" is unintentionally misleading (the misleading nature of many descriptions is part of my talk in London on Oct 10). In this case: No 'facts' are retained/memorised in LLMs, neither through pre-training, nor through fine-tuning, not even in a prompt/reply sequence. None. So the finding you bring up is not surprising at all. It is extremely to be expected.
"All facts presented by Generative AI — even those that are true — are fictitious. All logic and math is estimated … poorly." — Proposed disclaimer for LLMs, modelled after South Park (also from that upcoming talk). Prompt engineering, plugins, and even the non-LLM safety are all signs that we have to work around the fact that LLMs have no 'understanding' whatsoever (for any reasonable value of 'understanding'). Syntactically, they are near-perfect 'stochastically parrots', semantically, they are 'stochastically constrained hallucinators'.
Q: is 450 90% of 500?
ChatGPT: No, 450 is not 90% of 500. To calculate 90% of 500, you can multiply 500 by 0.90 (which represents 90% as a decimal):
500 * 0.90 = 450
So, 90% of 500 is indeed 450. My initial response was incorrect, and I apologize for any confusion.