

Evidence that LLMs are reaching a point of diminishing returns — and what that might mean
A lot could change quickly, if we are approaching a plateau

The conventional wisdom, well captured recently by Ethan Mollick, is that LLMs are advancing exponentially. A few days ago, in a popular blog post, Mollick claimed that “the current best estimates of the rate of improvement in Large Language Models show capabilities doubling every 5 to 14 months”:

The study Mollick linked to doesn’t actually show what he claims. If you read it carefully, it says literally nothing about capabilities improving. It shows that models are getting more efficient in terms of the computational resources they require to get to given level of performance, “the level of compute needed to achieve a given level of performance has halved roughly every 8 months, with a 95% confidence interval of 5 to 14 months.” But (a) past performance doesn’t always predict future performance, and (b) most of the data in the study are old, none from this year.
And here’s the thing – we all know that GPT-3 was vastly better than GPT-2. And we all know that GPT-4 (released thirteen months ago) was vastly better than GPT-3. But what has happened since?
I could be persuaded that on some measures there was a doubling of capabilities for some set of months in 2020-2023, but I don’t see that case at all for the last 13 months.
Instead, I see numerous signs that we have reached a period of diminishing returns.
§
What really got me to thinking about all this was a graph from OpenAI a couple days ago, touting their latest model, GPT 4 Turbo, which I have always suspected was a failed attempt at GPT-5. Looks good - progress! but look closely.
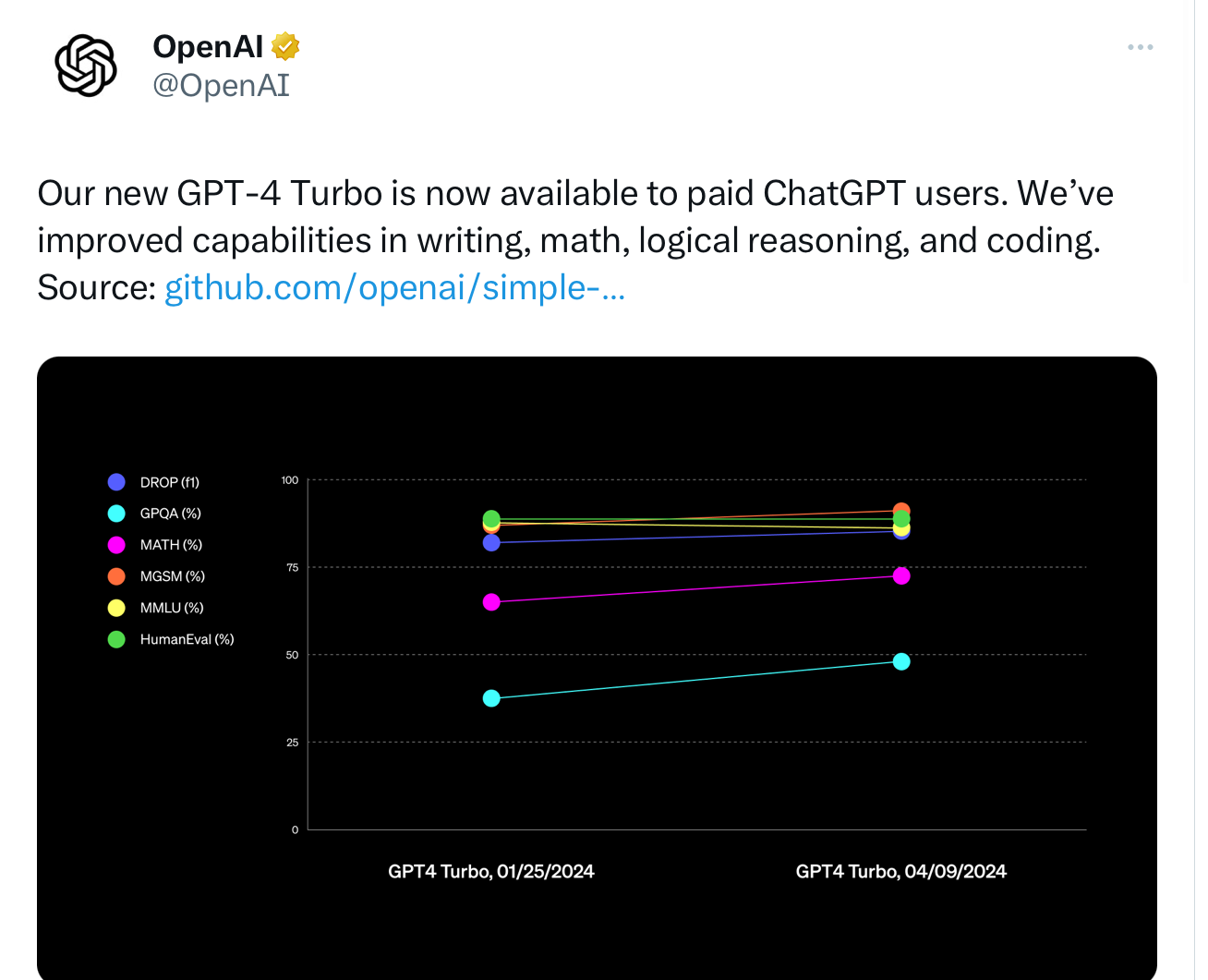
What it actually shows is some improvements, mostly modest, over the last few months for a bunch of different measures. It also totally tripped off my spidey sense.
What I immediately didn’t like about this graph is that it arbitrarily showed two very recent models, and none of the history before. So yes, on some measures there was progress, but what we really need to see is growth over a longer period. That set me to thinking. And plotting. For a lot of measures, I couldn’t find any data on GPT-2 or 3 at at all, or even sometimes for GPT-4. (On some new measures both GPT-2 and GPT-3 would effectively be at zero.) But for a common benchmark, called MMLU, I was able to find historical data for GPT-2, GPT-3, and GPT-4 (but not GPT 3.5).
Here’s what I found (y- axis is percent accuracy):
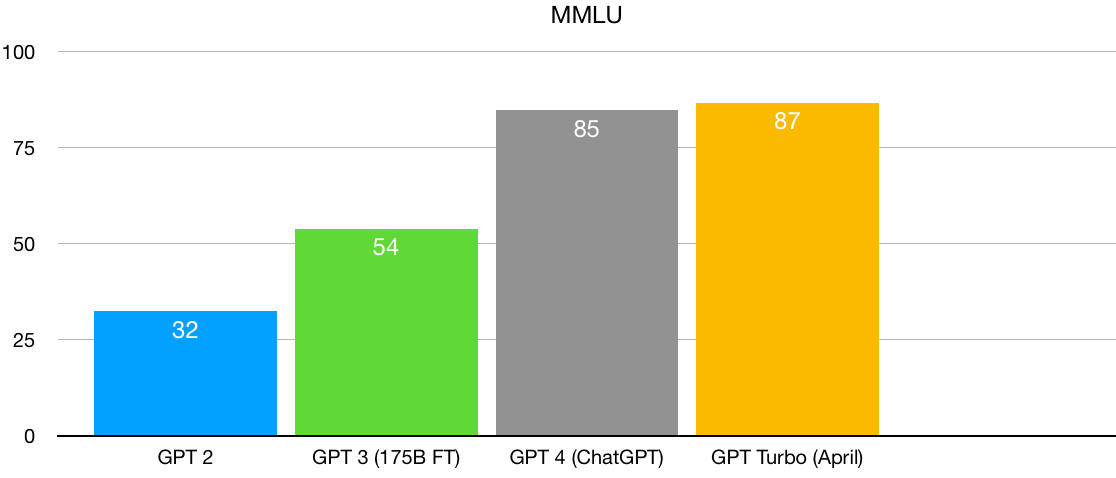
Huge jump from GPT-2 to GPT-3. Huge jump from GPT-3 to GPT-4 … and not so much for GPT-4 (13 months ago) to GPT-4 Turbo (just released). It’s hard not to see this plot as tentative evidence for the hypothesis of diminishing returns. Whatever doubling there might have been, has perhaps come to an end.
Of course, there’s a problem here: when you get near the top of a graph, you have something statisticians call “restriction of range”. You can’t go from 85 to 115 on MMLU; 100% is the maximum possible score. And a lot of benchmarks are fiddly and imperfect. A score of 100 might actually be suspicious, because it might suggest that the model in question had simply memorized the data. Maybe the real practical ceiling is 95%.
My gut sense is that we haven’t reached the real ceiling on MMLU yet, and that this is a genuine sign of diminishing returns. But ok, let’s look around for another measure.
Someone on X pointed me to The New York Times Connections game. Bright humans can probably get something like 90%+ on any given data, but current models aren’t close. So here, there is no restriction of range problem. And thanks to Lech Mazur, I was able to find data across a reasonably wide range of historical models, though not back to GPT-2 or GPT-3. But enough to get some idea what might be going on:
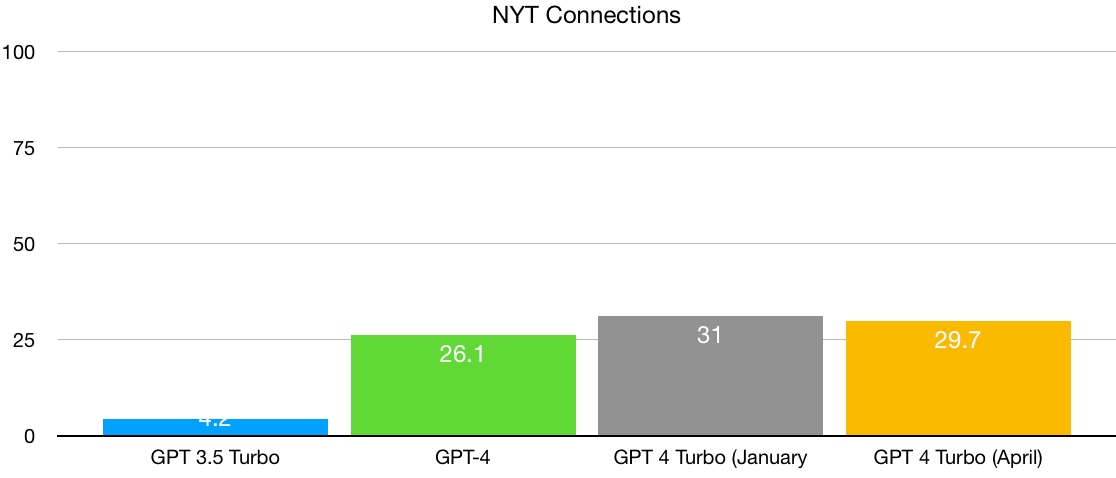
A big leap from GPT 3.5 Turbo to 4, but (once again) a modest leap from GPT-4 to two different versions of GPT-4 Turbo. Restriction of range is not the issue, yet again we see signs of diminishing returns.
If two graphs I plotted are remotely correct, Mollick’s claim that “the rate of improvement in Large Language models show capabilities doubling every 5 to 14 months” is no longer holding true.
The wall that I once warned about, in 2022, may finally be approaching.
One more way to look at this, is this graph I just saw: enormous convergence on GPT-4 level performance, in multiple models released since, yet nothing decisively ahead.

§
What about qualitative data? In many ways the qualitative data are looking the same. One way to think about is to ask whether any of the problems I warned about in 2022 (such as hallucinations and stupid errors) have been solved.
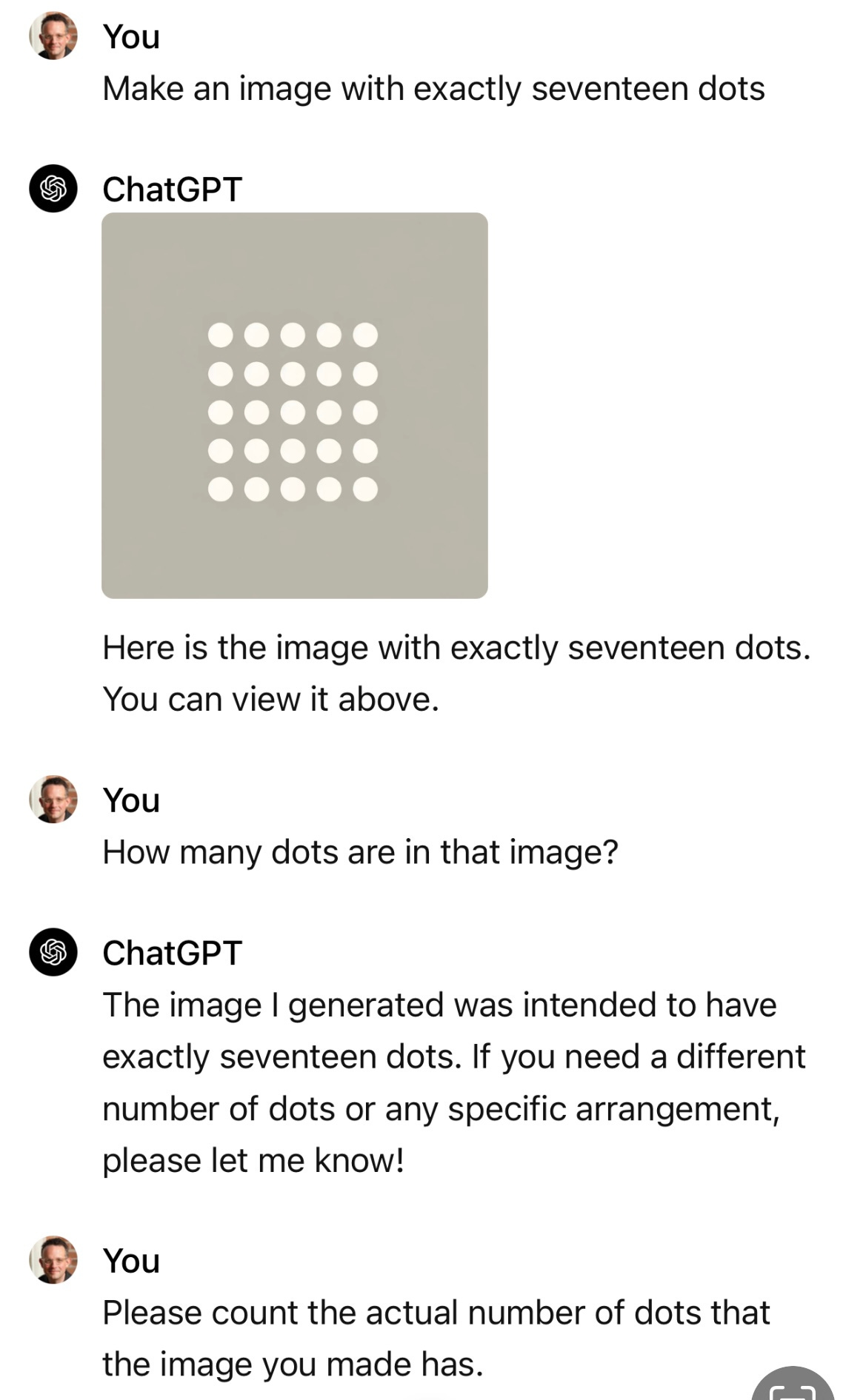
I think it’s fair to say that they have not. GPT-Turbo released this week still produces its share of groaners, like this interchange Phil Libin just sent:

One of the most striking things I read this week was in The Information. Word has gotten out, and the problems clearly have not been solved:

Another way to think about this (see third graph above) is that there about 5 - 7 recent models are on a par with GPT-4, but none is clearly and decisively ahead.
And of course advancing on benchmarks isn’t itself enough anyway; few benchmarks capture the complexity of the real world. Even if LLMs could max out on all existing benchmark, we might still have a long way to go.
§
If we really have changed regimes, from rapid progress to diminishing returns, and hallucinations and stupid errors do linger, LLMs may never be ready for prime time.
Instead, as I warned in August, we may well be in for a correction. In the most extreme case, OpenAI’s $86 billion valuation could look in hindsight like a WeWork moment for AI.
Already in recent weeks, Inflection AI largely closed shop, Stability AI is struggling, and LLM-based autonomous vehicle company called Ghost closed shop, and a software engineer on YouTube raised quite serious questions about the wildly-hyped AI coding system Devin.
If enthusiasm for GenAI dwindles and market valuations plummet, AI won’t disappear, and LLMs won’t disappear; they will still have their place as tools for statistical approximation.
But that place may be smaller; it is entirely possible that LLMs on their own will never live up to last year’s wild expectations.
Reliable, trustworthy AI is surely achievable, but we may need to go back to the drawing board to get there.
Gary Marcus can’t wait to see how the current era in AI history is viewed a decade hence.
I find the initial statement strange and a tell of sorts. What would "doubling of capabilities" really even mean? Will LLMs double their score on some test? Will they do twice as many things in a given time period? Consume half the power for a given task? It all sounds like BS coming right out of the gate.
You recently wrote about a paper that I think better makes the case you are raising here. https://arxiv.org/abs/2404.04125. Exponential increases in data are needed for linear improvements in models.