GPT-4’s successes, and GPT-4’s failures
How GPT-4 fits into the larger tapestry of the quest for artificial general intelligence

GPT-4 is amazing, and GPT-4 is a failure.
GPT is legitimately amazing. It can see (though we don’t have a lot of details on that yet); it does astonishingly well on a whole bunch of standardized tests, like LSATs, GREs, and SATs. It has also already been adopted in a bunch of commercial systems (e.g., Khan Academy).
But it is a failure, too, because
It doesn’t actually solve any of the core problems of truthfulness and reliability that I laid out in my infamous March 2022 essay Deep Learning is Hitting a Wall. Alignment is still shaky; you still wouldn’t be able to use it reliably to guide robots or scientific discovery, the kinds of things that made me excited about A(G)I in the first place. Outliers remain a problem, too.
The limit section in some ways reads like a reprise of that March 2022 paper. And the article doesn’t offer authoritative solutions to any of those earlier problems. In their own words:

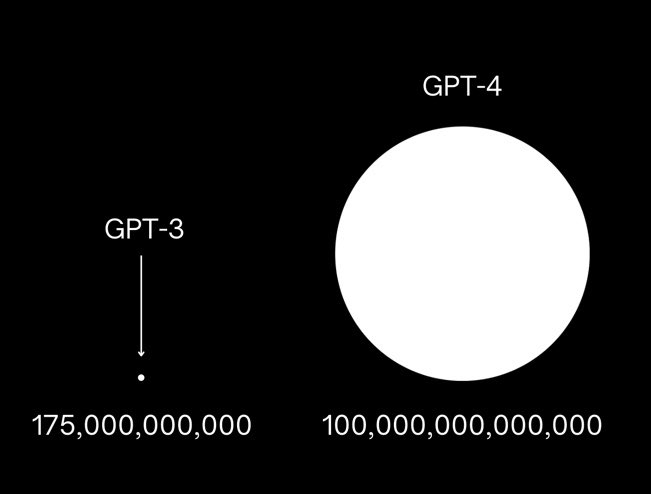
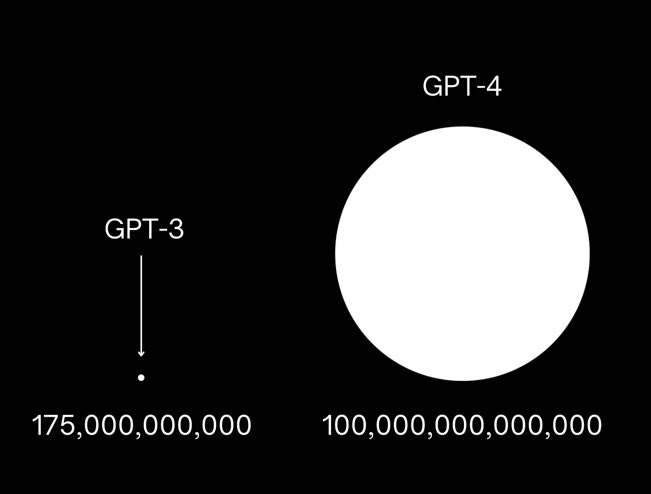
Massive scaling has not thus far lead to revolution. Although GPT-4 is clearly better than GPT-3 and 3.5, it is not so far as I can tell, qualitatively better, only quantitatively better; as noted above, the limits remain more or less the same. The quantitative improvements may (or may not) have considerable commercial implications in particular domains, but it’s not the massive win for the scaling hypotheses that memes like this had forecast.
GPT-4 is not thus far a solution to making Chat-style search work. On its own, it still requires frequent, massive retraining to be current with the news; GPT 3.5 knew nothing of 2022; GPT-4 seems to know little of 2023. And when GPT-4 is integrated in Bing (which incorporates current search results), hallucination remains rampant, e.g., in this example from last week when Bing apparently was already quietly using GPT-4 in the background.
It is a step backwards for science, because it sets a new precedent for pretending to be scientific while revealing absolutely nothing. We don’t know how big it is; we don’t know what the architecture is, we don’t know how much energy was used; we don’t how many processors were used; we don’t know what it was trained on etc.

![This report focuses on the capabilities, limitations, and safety properties of GPT-4. GPT-4 is a
Transformer-style model [33] pre-trained to predict the next token in a document, using both publicly
available data (such as internet data) and data licensed from third-party providers. The model was
then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34]. Given both
the competitive landscape and the safety implications of large-scale models like GPT-4, this report
contains no further details about the architecture (including model size), hardware, training compute,
dataset construction, training method, or similar.
We are committed to independent auditing of our technologies, and shared some initial steps and
ideas in this area in the system card accompanying this release.2 We plan to make further technical
details available to additional third parties who can advise us on how to weigh the competitive and
safety considerations above against the scientific value of fur](https://substackcdn.com/image/fetch/$s_!rweU!,w_600,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fpbs.substack.com%2Fmedia%2FFrMlVuNXsBsvq75.jpg)
Because of all that, we don’t know what explains its success, and we don’t know how to predict its failures:




All of this (a) makes me more convinced that LeCun is right that GPT-4 is an off-ramp to AGI (his riff on hitting a wall?), and (b) it puts all of us in an extremely poor position to predict what GPT-4 consequences will be for society, if we have no idea of what is in the training set and no way of anticipating which problems it will work on and which it will not. One more giant step for hype, but not necessarily a giant step for science, AGI, or humanity.
Gary Marcus (@garymarcus), scientist, bestselling author, and entrepreneur, is a skeptic about current AI but genuinely wants to see the best AI possible for the world—and still holds a tiny bit of optimism. Sign up to his Substack (free!), and listen to him on Ezra Klein. His most recent book, co-authored with Ernest Davis, Rebooting AI, is one of Forbes’s 7 Must Read Books in AI. Watch for his new podcast, Humans versus Machines, this Spring.
Seems like AI development is becoming more about passing standard tests than tackling the hard problems of intelligence.
Hacks that create a hypeable and sellable product are what's favoured.
If I had any artistic ability at all, I’d draw the following to try to help people understand the progress that’s been made here:
GPT-3 a blind folded person throwing a single dart at a dartboard
GPT-4 a blind folded person throwing two handfuls of darts at a dartboard