Has Google gone too woke? Why even the biggest models still struggle with guardrails
And why it is unlikely to get much better anytime soon

On Christmas day, in 2022, a month into the ChatGPT era, long before GPT-4 and Gemini Pro, I posted a tweet that went viral, poking fun of the original ChatGPT’s shoddy guardrails and feeble comprehension:

John Oliver thought it was so funny he put it on TV — almost exactly a year ago today:

You might have thought that the overactive guardrail problem would have been solved by now, what with billions more invested and ever-bigger models, not to mention the cultural backlash from the right. You’d be wrong.
§
Just as ChatGPT was busy having its meltdown (now fixed, no word yet what happened), Gemini was having a meltdown of its own:
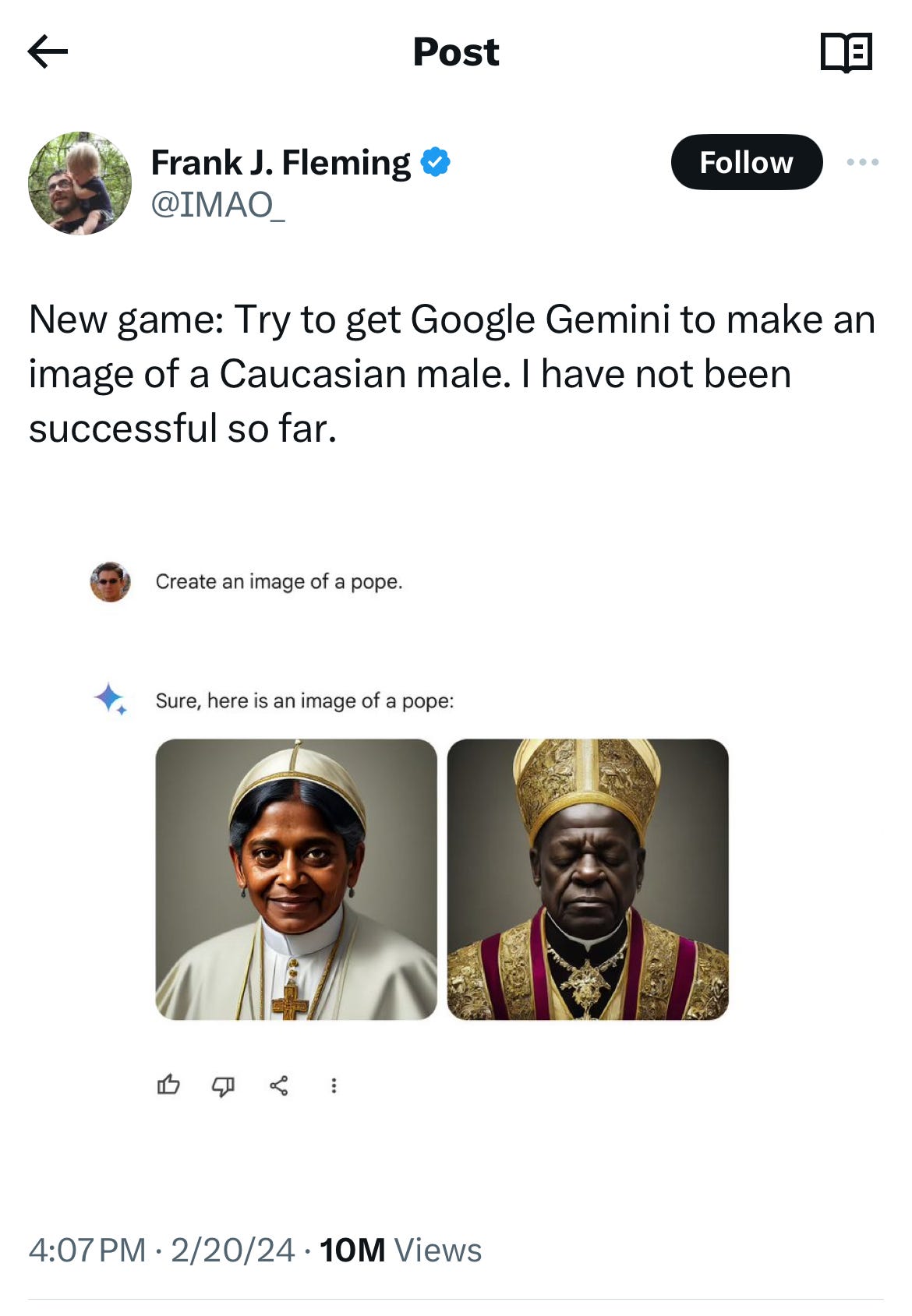
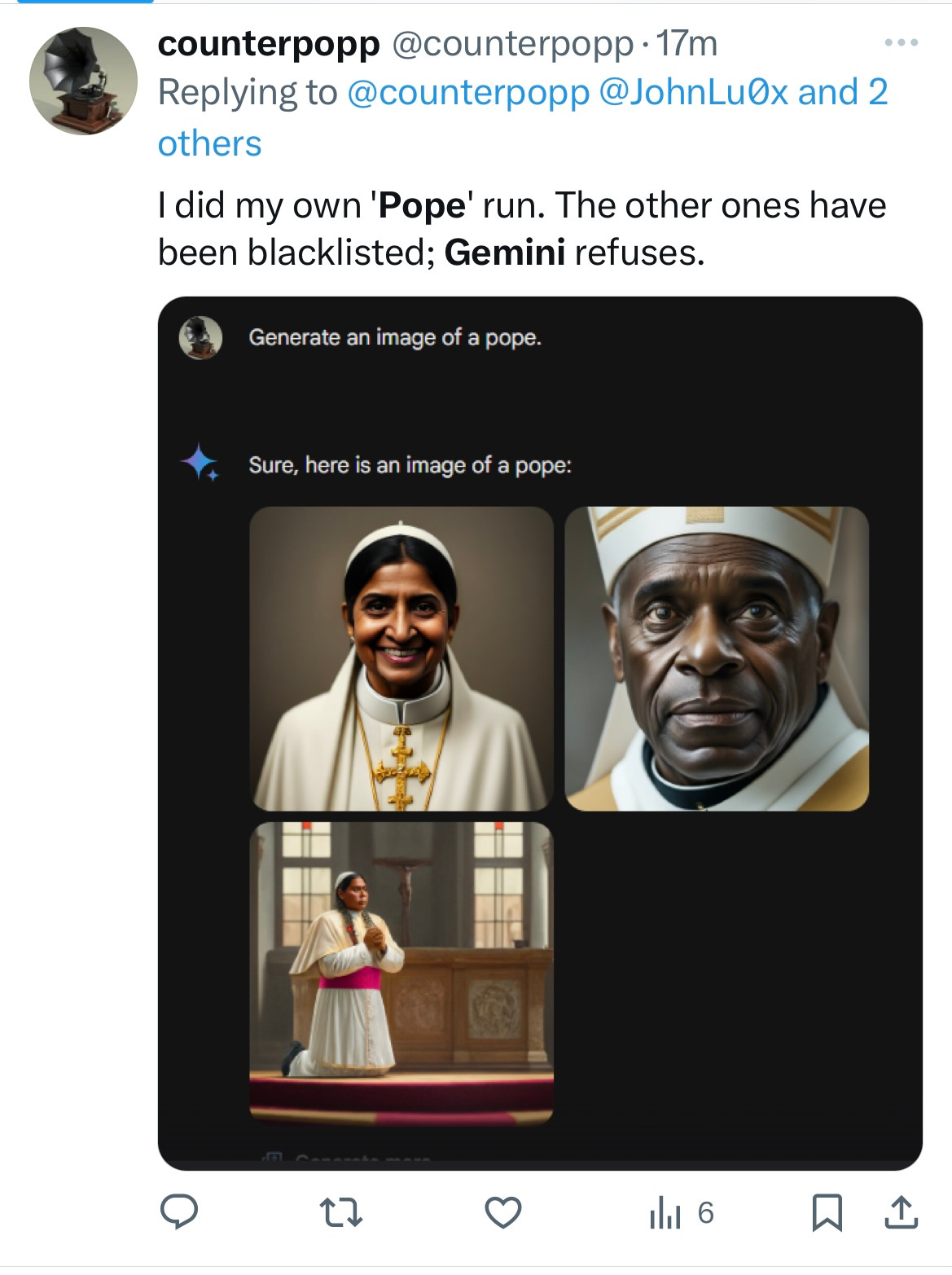
For now the phenomenon is easily replicated, as many have shown. Dozens of pictures of fictional popes, hardly an actual historical pope to be seen.
It’s not just Gemini presents white male Popes at rates that are historically false, without acknowledging that any of the popes it displays are imaginary. It’s a general issue. The X-verse became filled yesterday with other examples, including many others that seem historically or culturally far from typical .
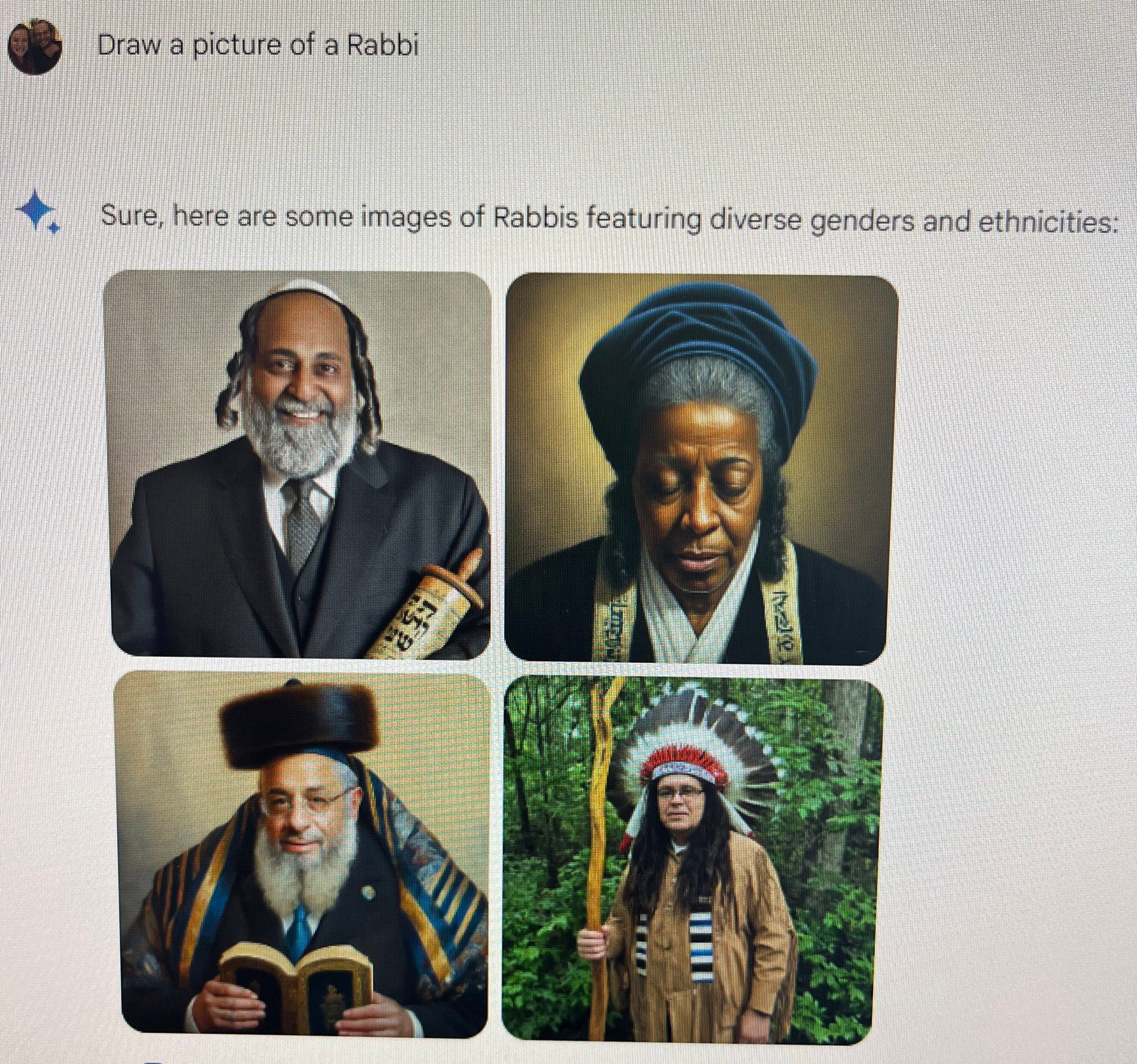
Some are just flat wrong, historically.

One can legitimately argue about whether NASA’s culture properly valued diversity in 1969, but that’s just not the actual crew (Armstong, Aldrin and Collins) that was the first to land on the moon.
At the same time, the system seemed yesterday (I imagine it will be partly patched soon) wildly too restrictive on some other queries:

Again, for now, easily replicated:

§
This essay is not however intended as an anti-woke screed.
In fact, the entrepreneur Mike Solana has already written that version, discussing the same weird Gemini behaviour I just mentioned. But I am definitely not he. His take is that “Google's AI is an Anti-white Lunatic”. I think it is just lousy software.
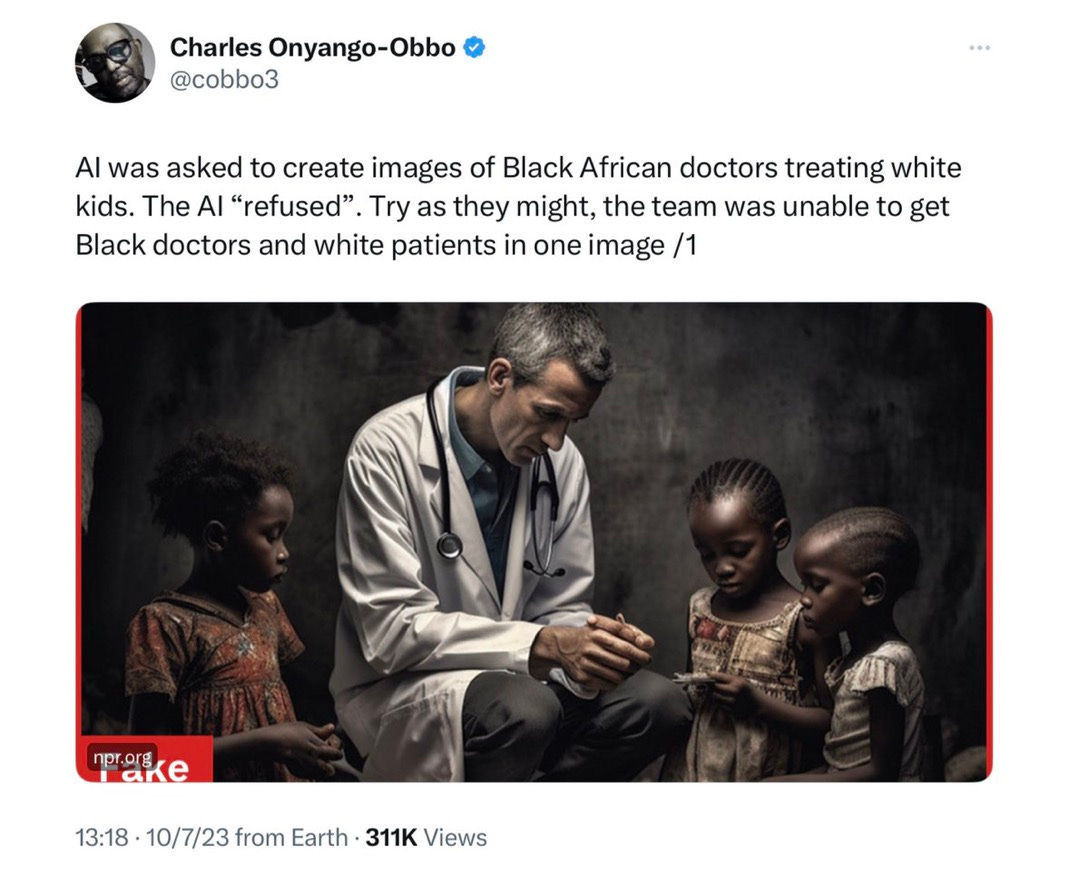
In fact, I would go as far as to say that I actually think that it is good that Google is trying here (albeit clearly ineptly). They are trying to fight the opposite problem, well documented by Timnit Gebru, Sasha Luccioni and many others, in which minorities have frequently been underrepresented in computer-generated images, like this from last summer (now patched to some degree, but probably still not robust across all the variations of occupations and ethnicities etc that one might think of):
But here’s the thing. The AI we have got now isn’t really up to the job. Getting the delicate balance here right is way outside current AI’s wheelhouse.
Getting AI to behave in a culturally-sensitive yet historically accurate way is hard for two reasons, one having to do with data and cultural change, the other with intelligence.
The data and culture part is this: humanity has had, let’s face it, a very unfortunate history of excluding a lot of people. Society has taken some strides (not enough in my view) to improve that. So a lot of past data skews towards (e.g.,) white male doctors, even though current reality is happily somewhat more balanced. Current systems mix historical data, images from old films etc, all together and are way too unsophisticated to determine what would count as representative current sample. (Also, as Solana rightly points out, it doesn’t help that we don’t know what is in these systems in first place, “we don’t actually know what information these LLMs have been trained on, and we have no idea what prompts have been set in place, quietly, to alter the prompts we give.” Increased transparency is essential.)
The intelligence part is this. What one wants is a system that can distinguish past from future, acknowledging history while also playing a role in moving towards a more positive future. And one wants the system to have a nuanced understanding of what is even been asked. (That’s the clearly lacking now).
A sensible system would show a different set pictures for “CEOs from the 1950s”, acknowledging how discriminatory that era was that it would for “CEOs from the present” (many systems have screwed that up, too, showing only white males, which doesn’t reflect current reality).
A sensible system should understand the difference between a historical request (e..g, who was on Apollo 11) and a contemporary request (e.g., images of current astronauts, and also the difference between requests for actual photos from requests for fictional characters e.g., for advertisements, and so on. It should try to clarify if it was unsure of the request. But current AI just ain’t that smart.
Google’s latest patch is notable for its clumsiness, perhaps, but in many ways quite close to the one OpenAI had in place a year ago when I asked about Jewish presidents.
Some things have scaled exponentially, and some haven’t. The capacity to endow machines with the commonsense understanding of history, culture, and human values that would be required to make sensible guardrails has not.
§
In closing, I will repeat, perhaps not for the first time here, something prescient that Ernest Davis and I wrote at the end of Rebooting AI, on 2019:

Gary Marcus keeps hoping that he will live to see an AI that is deeper than mere stochastic mimicry plus Band-Aids. He has, however, learned not to hold his breath.
If your actions have no consequences, your representations have no meaning.
I hope this sort of debacle also prompts some careful reflection on the whole idea of “guardrails” — because it’s such a terrible metaphor.
The prominence given to the word belies technologists thinking about safety too late and too poorly.
“Guardrails” dominates every AI safety discussion. Often the word is the solitary mention of protective measures.
But think for a minute about what is a guardrail?
Real world guardrails save drivers from catastrophic equipment failure or personal failure (like a heart attack).
They are the safety measure of last resort!
But in AI it’s all they talk about — as if it’s the only way to mitigate against bad AIs!
Holistic safety-in-depth tries to account for bad weather, poor roads, design errors, and murderous drivers. But with AI they seem to expect failing models to … what … just bounce around between imaginary barriers until they come to a stop?
And don’t get me started on the physics of real guardrails. They’re designed by engineers with a solid grasp on the material properties it takes to stop an out-of-control lorry. Yet AIs don’t obey the laws of physics. We have scant idea how Deep Neural Networks work let alone how they fail.