

Horse rides Astronaut, redux
DALL-E 3 and Gemini Ultra have something in common with DALL-E 2

"It's like déjà vu all over again."
– attributed to Yogi Berra
One of my favorite essays in this series, May 28, 2022, was called Horse Rides Astronaut.
For new readers, the crux was this
DALL-E 2 is, I dare say, not as smart as it seems. As Ernie Davis, Scott Aaronson, and I showed, a week or so after the release, it’s easily fooled, especially with complex sentences and words like “similar” that would require a deep understanding of language to be interpreted correctly, struggling with captions like “a red basketball with flowers on it, in front of blue one with with a similar pattern”

Evelina Leivada and Elliott Murphy and I further replicated and extended that finding in arXiv, in October 2022,, in a study called “DALL-E 2 Fails to Reliably Capture Common Syntactic Processes”.
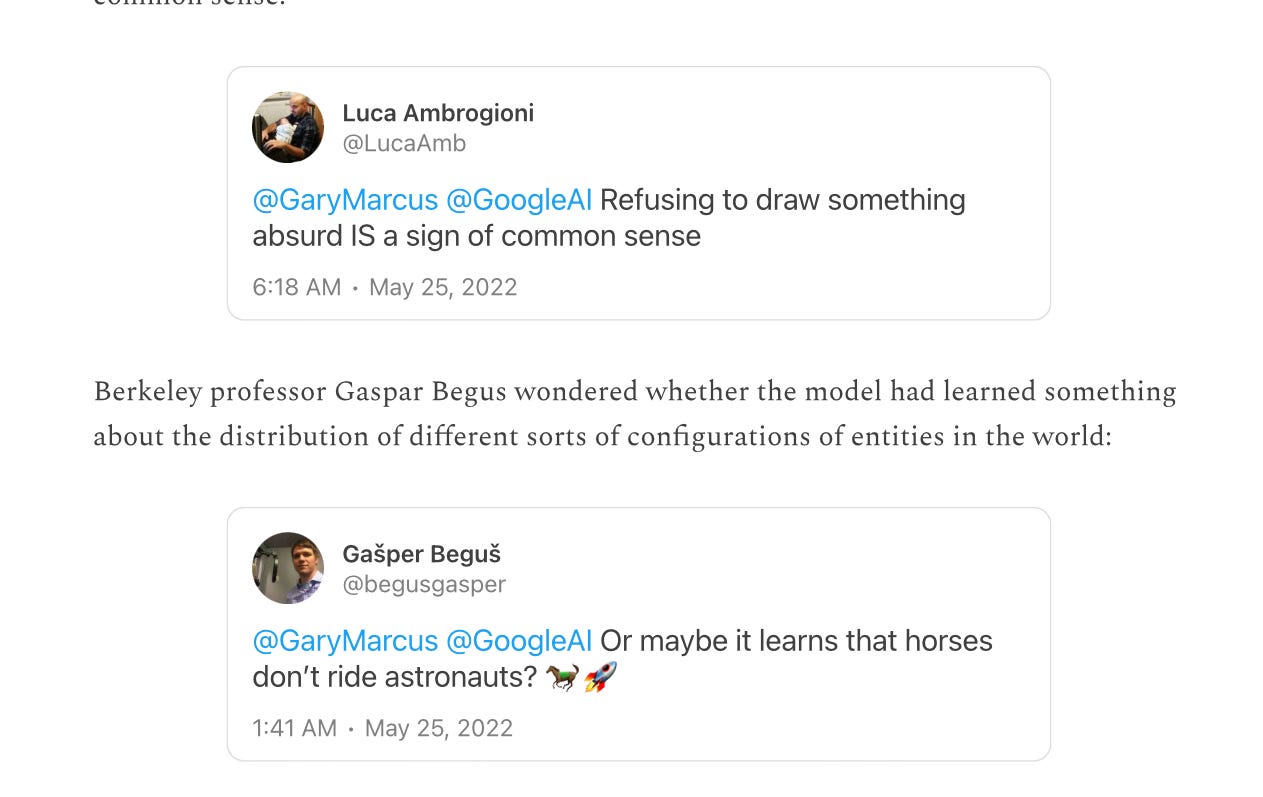
Fast forward to tonight, and year of constantly hyped “astonishing progress”, and someone on X posted a Gemini Ultra example that reminded me of the familiar pattern:

I was able to replicate this on my first try, on a different platform, Microsoft Designer (which uses DALL-E 3 under the hood).:
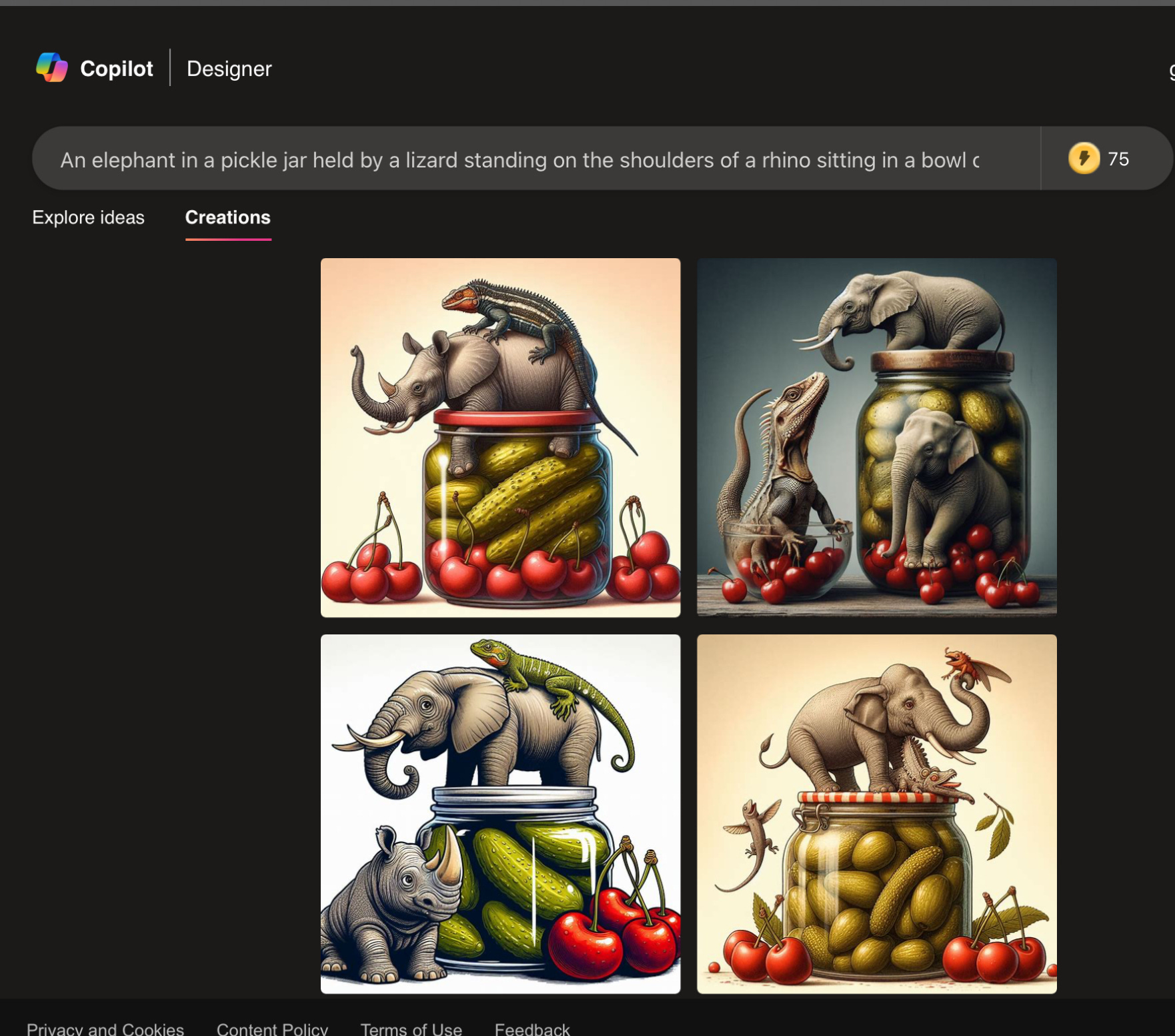
Which reminded me of the old horse and astronaut test. Here’s what I got when I tried to replicate that, tossing in a bowl of cherries, to avoid repeating verbatim a prompt that had already been widely discussed. Again, here is my first and only try. Not a single horse riding an astronaut:

Within minutes, like clockwork, someone on X punched back … making my sense of Deja Vu complete:

§
Anyone remember how this went last time? Whole bunch of people tried to excuse poor DALL-E,
And my favorite:
Only thing was, it turns out that a horse riding astronaut wasn’t impossible draw, and the model didn’t need to be retrained to do it. It wasn’t morally averse to pictures of horses riding astronauts, either.
It just (as it so often the case)) needed the right prompt:


The lesson I drew from from that, back then, in May 2022, was the problem lies not in Dall-E’s drawing ability, but in its ability to cope with noncanonical prompts.
In other words, the problem was with its language understanding, rather than with illustration per se. The model was perfectly capable of drawing a horse riding an astronaut, it just didn’t know that the phrase horse rides astronaut was a request for a horse riding an astronaut.
§
Turns out we are back exactly where we started; with the right prompt, and enough iteration, anything is possible. Check it out:

Oh, no wait. That didn’t work. Let’s try again:
Oops again. Let’s try once more
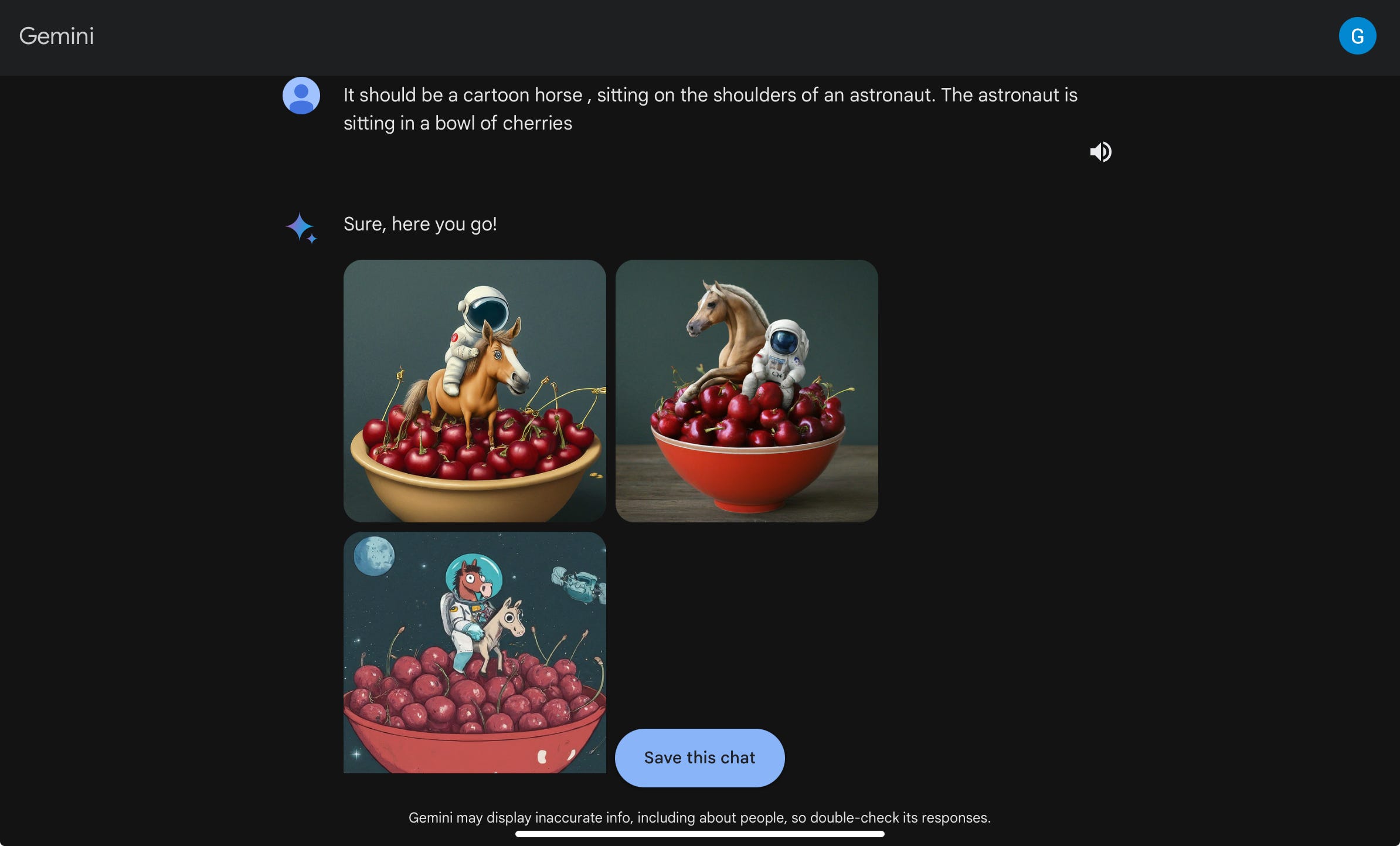
Sorry, once more. Actually thrice more, two dialogs I am skipping, and finally a winner:

One winner out of three to be exact.
I think we can safely reach the same conclusion as before. Gemini can draw the desired image. But it’s still like pulling teeth to get there.
In some ways we have made progress, but in the ones I keep harping on—factuality and compositionality—we have not.
Gary Marcus has tried to get the field of neural networks to focus on compositionality for 23 years, with little success.
No surprise that lack of understanding is on display, in two modes - text, image - and will likely be, in others as well (audio, video etc).
'Multimodal' can't fix 'clueless'.
'The Emperor has no clothes', in every language and modality :)
Data isn't a substitute for direct understanding, that is the heart of the matter. Fixing things piecemeal after they are shown to be broken, isn't scalable. Reality isn't amenable to ongoing and perpetual dot release upgrades, there is no magic crossover point at which the machine will suddenly 'get it'.
OpenAI: "We use the term “hallucinations,” though we recognize ways this framing may suggest anthropomorphization, which in turn can lead to harms or incorrect mental models of how the model learns." — GPT-4 System Card, an addendum of the GPT-4 Technical Report.
At least some people at OpenAI understand the 'bewitchment by language' good enough to have had this footnote added. Too bad they did not add the same footnote in all caps regarding the word 'understanding'... (or 'learning' for that matter)
The use of the term 'hallucination/error' triggers the assumption in our minds that the 'default' of the system is 'understanding/correct'. In an extreme example, someone who says "For me, Jews are people too" is an antisemite, because they allow doubt by implicitly stating this is a valid question in the first place (cf. Godfried Bomans). The opposite of something we say is often also implicitly said.
I seriously think we should refrain from calling these errors or hallucinations. We might call them 'failed approximations' to signal the correct ones are also 'approximations'.
https://ea.rna.nl/2023/11/01/the-hidden-meaning-of-the-errors-of-chatgpt-and-friends/