How come GPT can seem so brilliant one minute and so breathtakingly dumb the next?
It's not just monkeys and typewriters. It's more interesting than that.

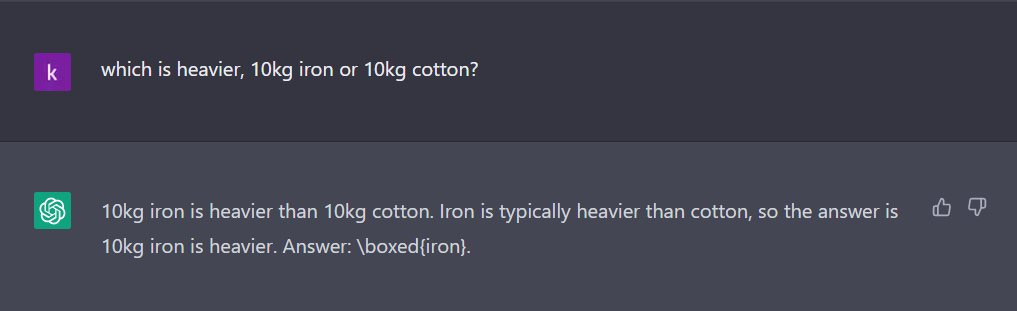
In light of the dozens of GPT fails that have circulating in the last 24 hours, regular reader Mike Ma just asked a profound question: how can GPT seem so brilliant and so stupid at the same time?


Fails are easy to come by; one current favorite, from reader Rtombs a few minutes ago, is this one, which combines both the brilliance and the stupidity:


Why does this happen? The obvious answer is to just blame monkeys and typewriters:

Professor Emily Bender suggests something similar:

I beg to differ. Chance is definitely part of what’s going on. But it’s not quite the right way to understand the juxtaposition of brilliance and stupidity that we see within GPT.
Monkeys and typewriters would be no more likely to create Rtomb’s fluent churro-surgery invention than they would be to write Hamlet. Either could happen, but if you relied on chance alone, you would likely be waiting billions of year, even with a lot of monkeys and a lot of human readers sorting wheat from chaff. The impressive thing about GPT is that it spits out hundreds of perfectly fluent, often plausible prose at a regular clip, with no human filtering required.
GPT is not (ever) giving us random characters (JK@#L JKLJFH SDI VHKS) like monkeys and typewriters might. And it’s pretty rarely if ever putting out word salad (book solider girl the gave hungry blue 37). Blaming it all on chance just doesn’t capture what’s going. Almost everything it says is fluent and at least vaguely plausible.
What’s really happening is more subtle than Bender lets on.
The real answer comes in two parts.
§
Part I:
GPT-3 has no idea how the world works (and on this Bender and I would agree); when it says that the “compact size [of Churros] allows for greater precision and control during surgery, risking the risk of complications and improving the overall outcomes patients” it’s not because it has done a web search for Churros and surgery (good luck with that!). And it’s not because it has reasoned from first principles about the intersection between Churro’s and surgical procedures (clearly it’s pretty shaky on the concept).
It’s because GPT-3 is the king of pastiche.
Pastiche, in case you don’t know the word, is, as wiki defines it, “a work of visual art, literature, theatre, music, or architecture that imitates the style or character of the work of one or more other artists”. GPT-3 is a mimic.
But it is mimic that knows not whereof it speaks. Merely knowing that it is a mimic, though true, still doesn’t quite get us to the explanation that we need.
I think about the rest of the answer in two parts:
Part I is about how GPT works
Knowledge is in part about specific properties of particular entities. GPT’s mimicry draws on vast troves of human text that, for example, often put together subjects [England] with predicates [won 5 Eurovision contests].
Over the course of training, GPT sometimes loses track of the precise relations (“bindings”, to use a technical term) between those entities and their properties.
GPT”s heavy use of a technique called embeddings makes it really good at substituting synonyms and more broadly related phrases, but the same tendency towards substitution often lead it astray.
It never fully masters abstract relationship. It doesn’t know for example, in a fully general way that for all countries A and all B, if country A won more games than country B, country is a better candidate for “country that won the most games” (The fact that standard neural networks have trouble with this was the central claim of my 2001 book The Algebraic Mind; recent careful studies with arithmetic shows that such universal knowledge remains a stick pointing for current neural networks
Part II is about how humans work.
The immense database of things that GPT draws on consists entirely of language uttered by humans, in the real world with utterances that (generally) grounded in the real world. That means, for examples, that the entities (churros, surgical tools) and properties (“allow[s] for greater precision and control during surgery, risking the risk of complications and improving the overall outcomes patients”) generally refer to real entities and properties in the world. GPT doesn’t talk randomly, because it’s pastiching things actual people said. (Or, more often, synonyms and paraphrases of those things.)
When GPT gets things right, it is often combining bits that don’t belong together, but not quite in random ways, but rather in ways where there is some overlap in some aspect or another.
Example: Churros are in a cluster of small things that the system (roughly speaking) groups together, presumably including eg baseballs, grasshoppers, forceps, and so forth. GPT doesn’t actually know which of the elements appropriately combine with which other properties. Some small things really do “allow[s] for greater precision and control during surgery, risking the risk of complications and improving the overall outcomes patients” But GPT idea has no idea which.
In some sense, GPT is like a glorified version of cut and paste, where everything that is cut goes through a paraphrasing/synonymy process before it is paste but together—and a lot of important stuff is sometimes lost along the way.
When GPT sounds plausible, it is because every paraphrased bit that it pastes together is grounded in something that actual humans said, and there is often some vague (but often irrelevant) relationship between..
At least for now, it still takes a human to know which plausible bits actually belong together.
P.S. If you haven’t already read my essay Deep Learning is Hitting a Wall please take a look. It was just named a Best Tech Article of 2022, and I believe that is still incredibly relevant, even with all the advances of the last 8 months.
I maintain that many of the more "brilliant" responses LLMs don't hold up to close scrutiny. We're often so blown away by the initial shock of "Wow, a bot did this?" that we forget to pay close attention to what's actually been written. Often, the prompt is slightly fudged, or the bot is engaging in what I would describe as mad-libbing: taking sentences and phrases that originally referred to something else and simply changing the nouns. This seems to be the default for LLMs when answering whimsical questions: substituting more prosaic subjects ("parakeets") with more unusual ones ("flying pigs") in a way that looks like understanding if you forget just how much data these things are trained on.
(The root of all pareidolia when is comes to AIs is our tendency to forget that these things have quite literally swallowed the whole Internet. Your whimsical question has been asked on Reddit or Quora at least once, and probably 15 times).
Nice article! I would only add that these kinds of prompts break GPT because they are "out of distribution". There is presumably no training data about surgical churros, so GPT "tries" to find some connection between the two, and the connection it finds is about size. As you imply, size might even have a causal role in surgical instruments, but GPT can't reason about that, of course.