How New are Yann LeCun’s “New” Ideas?
spoiler alert: not very

At 62, the celebrated deep learning pioneer Yann LeCun, NYU professor, winner of the Turing Award, and Chief AI Scientist at Meta, is on a mission to reposition himself, not just as a deep learning pioneer, but as that guy with new ideas about how to move past deep learning. He (or perhaps MetaAI’s PR department) has talked both Technology Review and ZDNet into laudatory profiles, the former entitled Yann LeCun has a bold new vision for the future of AI. Just since the beginning of June, LeCun has also posted a widely-discussed manifesto, and a review of my own work [which differs in some important respects from his] staking out his own position on the important question of symbol-manipulation. But how much of what he is saying is really new?
When I read the ZDNet interview, which was published yesterday, I was astounded. And not in a good way. Nearly everything LeCun said, I had said earlier, some almost word for word—most of it in a 2018 paper called Deep Learning: A Critical Appraisal that LeCun had pilloried at the time as “mostly wrong”.
Here are seven examples; as we shall see, this is but one instance of a larger problem.
LeCun, 2022: Today's AI approaches will never lead to true intelligence (reported in the headline, not a verbatim quote); Marcus, 2018: “deep learning must be supplemented by other techniques if we are to reach artificial general intelligence.”
LeCun, 2022: [Current Deep learning models] “may be a component of a future intelligent system, but I think it's missing essential pieces."; “I think they're necessary but not sufficient,"; Marcus 2018: “Despite all of the problems I have sketched, I don’t think that we need to abandon deep learning. Rather, we need to reconceptualize it: not as a universal solvent, but simply as one tool among many, a power screwdriver in a world in which we also need hammers, wrenches, and pliers, not to mentions chisels and drills, voltmeters, logic probes, and oscilloscopes.”
LeCun, 2022: Reinforcement learning will also never be enough for intelligence; Marcus, 2018: “ it is misleading to credit deep reinforcement learning with inducing concept[s] ”
LeCun, 2022: “We're not to the point where our intelligent machines have as much common sense as a cat," observes Lecun. "So, why don't we start there?" Marcus, 2022: “Where else should we look [beyond deep learning]? … A second focal point might be on common sense knowledge”
LeCun, 2022: “I think AI systems need to be able to reason,"; Marcus 2018: “Problems that have less to do with categorization and more to do with commonsense reasoning essentially lie outside the scope of what deep learning is appropriate for, and so far as I can tell, deep learning has little to offer such problems.”
LeCun, 2022: "You have to take a step back and say, Okay, we built this ladder, but we want to go to the moon, and there's no way this ladder is going to get us there”: Marcus, in The New Yorker in 2012: “To paraphrase an old parable, [with deep learning] Hinton has built a better ladder; but a better ladder doesn’t necessarily get you to the moon.”
Nobody has ever reprised my own arguments more closely than LeCun did yesterday, much less without attribution.
I won’t accuse LeCun of plagiarism, because I think he probably reached these conclusions honestly, after recognizing the failures of current architectures. What I foresaw, he has finally recognized for himself. At some level this is a tremendous victory for me - to have someone so eminent move to a position that I staked out, long ago.
§
But there is more to the story to than that. A lot more.
To begin with, LeCun is determined to never be seen as echoing anything I have ever said. Since he very publicly criticized my earlier paper, we know he is aware of it. The degreee to which LeCun failed to share any credit—an absolute violation of academic etiquette (we’ve both been professors since the ‘90s, though I retired early)—is striking.
More than that, to make sure nobody gave me any credit, he took a gratuitious, and completely dishonest potshot at me, in the same interview, alleging, quite falsely “Gary Marcus is not an AI person, by the way, he is a psychologist. He has never contributed anything to AI. He's done really good work in experimental psychology but he's never written a peer-reviewed paper on AI”— which is simply false. In reality, I have published extensively in AI, some in peer-reviewed journals, some not. My most important AI paper, which did experimental work on neural networks, foresaw in 1998 the challenges of distribution shift and outliers that are preoccupying Yoshua Bengio and others now. In the last decade, I have published peer-reviewed AI articles on topics such as common sense, reasoning from incomplete information, and limits of simulation and automatic reasoning, many with the NYU computer scientist Ernest Davis, who happens to be in LeCun’s department. Perhaps my most influential AI work of all happens not to have been a journal article, but a 2001 book The Algebraic Mind (which MIT Press sent out for peer review). Nearly every bit of what LeCun told ZDNet was foreseen there; two leaders in the fast-growing field of neurosymbolic AI have said that they see The Algebraic Mind as vital to their approach. What LeCun really means is that he hasn’t read any of it; the idea that it isn’t influential is laughable.
LeCun’s claim was egregious enough that others have come to my defense; ZDNet posted an immediate correction, and as I was drafting this, Miguel Solano, CEO of Vmind.AI wrote this, backing me up:

Henning Schwabe was even more pointed, building on remarks from Dagmar Monett:


Graduate students sometimes play fast and loose with credit to build themselves up; Harold Bloom once wrote a book about what he called The Anxiety of Influence. Until this year I had never seen anything like this in someone of LeCun’s stature.
But this year I have seen it from him, over and over.
§
Each of LeCun’s recent papers and essays has, in its own way, exhibited the same denial of the past.
One essay involved the long standing question of symbol-manipulation. Since I already responded at length in Noema, I will summarize only briefly here. LeCun spent part of his career bashing symbols; his collaborator Geoff Hinton even more so, Their jointly written 2015 review of deep learning ends by saying that they “new paradigms are needed to replace rule-based manipulation of symbolic expressions.”
Nowadays LeCun is endorsing symbol-manipulation (an idea I did not invent but have been defending for 30 years), and acting as if nobody said otherwise—a dispatch from Orwell’s Ministry of Truth. As I put it in Noema, when LeCun and Browning wrote “everyone working in [Deep Learning] agrees that symbolic manipulation is a necessary feature for creating human-like AI,” they are walking back decades of history. Even Stanford AI Professor Christopher Manning (often closer in his views to LeCun then me) was shocked:

When I pointed all this out at length, LeCun’s only response to my lengthy, detailed analysis article, which was fact-checked by Noema, was, well, lame. In lieu of responding, he retweeted a vague, contentless rejoinder written by his co-author:


Not one specific objection to anything that I said in my scathing rebuttal.
§
Another of LeCun’s recent essays involved the important question of whether large language models are really on the right track to general intelligence, and whether one can really learn enough from language alone. LeCun and his collaborator Browning make a strong case that language input alone (which is the kind of thing that GPT-3 is trained on) is not enough, writing an essay called AI And The Limits Of Language arguing that “A system trained on language alone will never approximate human intelligence, even if trained from now until the heat death of the universe.”
But here again there’s a lack of credit. Here for example is something I wrote about the same question in February 2020 in an arXiv artcle called The Next Decade in AI:
Waiting for cognitive models and reasoning to magically emerge from larger and larger [language] training corpora is like waiting for a miracle…
— almost exactly what LeCun and Browning concluded.
But, no, we are not done.
§
The key question is what we as field should do about the fact that you can’t really solve AI from large language models alone. Here was my prescription in January 2020:
A system like GPT-2, for instance, does what it does, for better and for worse, without any explicit (in the sense of directly represented and readily shared) common sense knowledge, without any explicit reasoning, and without any explicit cognitive models of the world it that tries to discuss.
and in February 2020
Every moment spent on improving massive models of word-level prediction… might be better spent on developing techniques for deriving, updating, and reasoning over cognitive models.
Sound familiar? Incorporating cognitive models is what LeCun was pitching to ZDnet yesterday, and in many ways the heart of LeCun’s summer manifesto.
When I first made this point in 2019, guess who publicly bullied me for saying it? That’s right, Yann LeCun.
I wrote:






which is a different way of saying that the problem with large language models is a lack of cognitive models.
At that time, LeCun accused me of fighting a rear-guard battle:

Now that he seen the light, he has forgotten that it ever happened. I saw the critical need for cognitive models first; he attacked me; now he claims it as his own.
§
Now here’s the thing: I have a right to be pissed, but I am not alone.
Deep learning pioneer Jürgen Schmidhuber, author of the commercially ubiquitous LSTM neural network, arguably has even more right to be pissed, as he recently made clear on Twitter and in a lengthy manuscript:

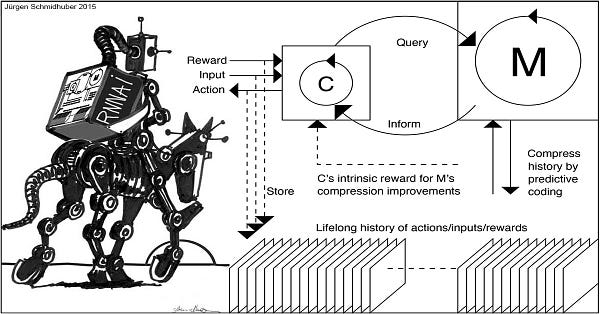
“Rehashes but doesn’t cite”—that’s polite peer reviewer-ese for “a lot less original than it pretends to be”.
A large part of LeCun’s new manifesto is a well-motivated call for incorporating a “configurable predictive world model” into deep learning. I’ve been calling for that for a little while, but Schmidhuber deserves more credit, because he had actually been trying to implement that in the forerunners to deep learning the 1990s, and LeCun scarcely gave his team’s work the time of day.
§
By now some of the Twitterverse is on to LeCun. When LeCun’s manifesto come out, German computational neuroscientist and AI researcher Patrick Krauss tweeted, sarcastically


This morning, the mononymous Lathropa was even more pointed. As is well known throughout the field, LeCun has taken numerous digs on the title of a widely-read essay I wrote for Nautilus in March 2022, called Deep Learning Is Hitting A Wall.
So, what is he really trying to say now, a few months later?

I have so much trouble seeing what’s really new in LeCun’s recent flurry that I asked him yesterday on Twitter to explain.
So far he hasn’t answered.
If it's not working, try something different. That's the hallmark of intelligence, eh?
What exactly is novel about doubting how statistical models (aka, deep learning/ML) can never really replicate the underlying system its modeling? It's well known in the math, physics, and philosophy communities that statistical models will never fully replicate an analytical model of the system no matter the various linear algebra structures and optimizations you add (in fact, statistical modeling and numerical computation were always considered "easy" fields relative to theory). Find, you converge to some local minimum that minimizes some error function or metric for a large input, you've still just produced a really good statistical model and not discovered the formal model.
Sorry, your statistical models are finding the extrema of some abstract problem space and just because you improve the finding of these local extrema doesn't mean you've reproduced the analytical form of the problem space your model is attempting to "learn".