
Is ChatGPT Really a “Code Red” for Google Search?
Is ChatGPT Really a “Code Red” for Google Search?
Maybe not

Last week, The New York Times said ChatGPT is a “code red” for Google. A zillion people on Twitter have echoed the same sentiment, like George Hotz, the one-time Elon Musk adversary who was hired by Twitter to fix search, only to quit 5 weeks later:


And sure enough, companies like perplexity.ai, neeva.com and you.com are already test-piloting systems that merge traditional search with large language models (a la ChatGPT). Even good friends of mine are trying it. An eminent author friend just wrote to me:
I broke down and got a ChatGPT account yesterday, and have been using it for two purposes. I’ve begun work on a new book …. and thought I’d use it instead of Google as a way smarter search engine for references that aren’t easily specified in text strings (e.g., “What was the opinion poll that showed that a majority of Americans feel that they constantly have to watch what they say?”). The other is just to fill in the holes in my aging memory (e.g., “What was the name of a British comedy film about orthodox Jews in the early 2000s?”)
Can ChatGPT really do all that? Should Google be quaking in its boots?
§
Well maybe. But I’m not sure. On December first, I judged that the first round to Google:

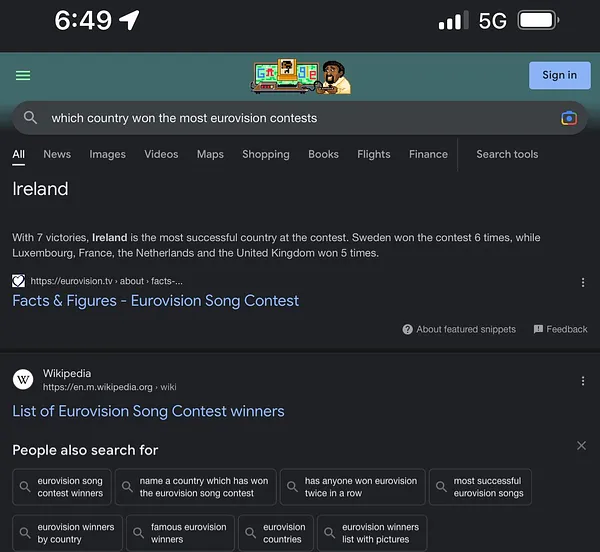


Today it’s time for Round 2; that was almost a month ago, almost an eternity in AI hype. How about now, at the end of December?
Turns out my author friend wasn’t too pleased either:
To my disappointment, it’s been perfectly useless – zero usable hits, though a lot of PC boilerplate about how you should never generalize about groups of people and that people have to be respected for what they say and believe. It’s just been two days, but I wonder if the shallowness of understanding that you’ve repeated[ly] discovered will be a true handicap in its most legitimate use, namely as a more conceptual and semantic search engine
To be fair large language models aren’t inherently ultra-PC. ChatGPT is; MetaAI’s Galactica most certainly wasn’t, writing essays on the alleged benefits of antisemitism and so on, which lead to its abrupt removal by Meta AI. Rather, it’s the guardrails that OpenAI added with ChatGPT screens out many of the most offensive responses that LLMs might otherwise produce.
The trouble is, those guardrails don’t come for free; the system is still shallow; ChatGPT doesn’t really know what it is it is guarding against; it mostly seems instead to be just looking for keywords, which is why it is prone to generating nonsense like this:

I like to call this sort of nonsense discomprehension: mindless answers that show that the systems has no clue what it is that is talking about.
§
There’s another problem, too, arguably even bigger concern in the context of search engines: hallucination. When ChatGPT (which was not deliberately designed to be a search engine) barfed on my friend’s queries, I tried submitting them to YouChat, which (unlike ChatGPT) has been explicitly tailored to search. Once again, the result was fluent prose, and once again, hallucination ruled:
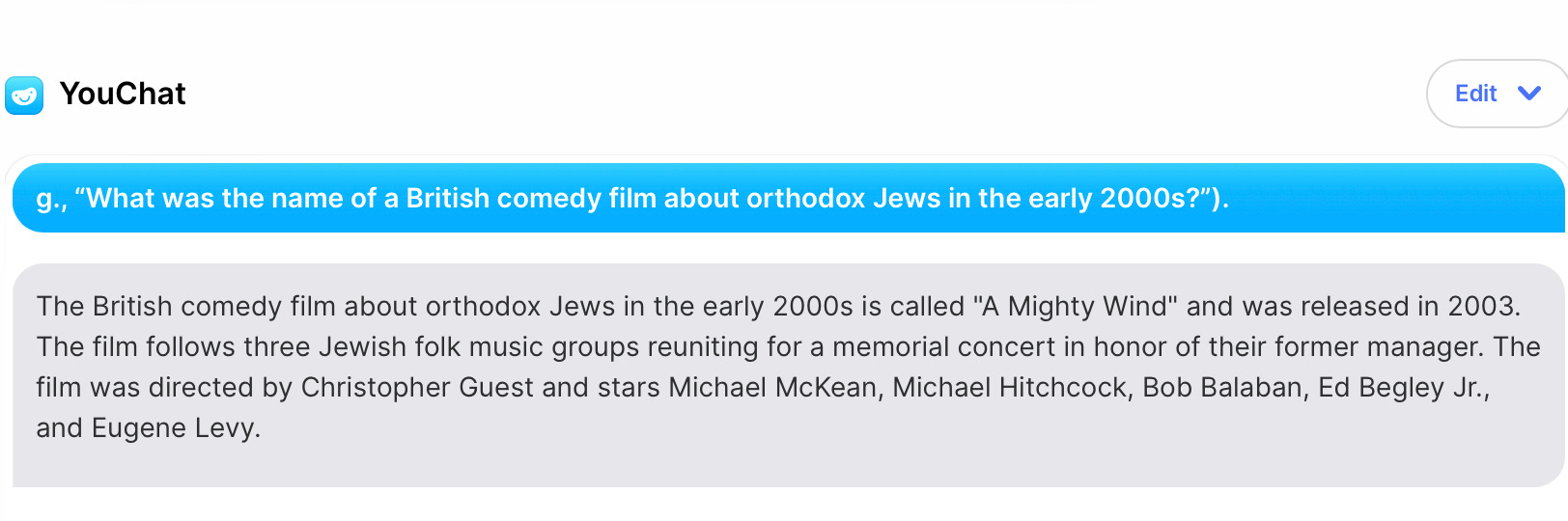
Sounds perfectly plausible. But A Mighty Wind is not about orthodox Jews, and it’s not a British comedy. (And where the hell is Harry Shearer?) We get a bunch of true stuff (Christopher Guest really did direct, the year really was 2003) mashed together with some other stuff that doesn’t belong. I think it’s fair to say it’s not the film my writer friend was looking for.
What good is a search engine that makes stuff up?
Here’s my friend’s other query:
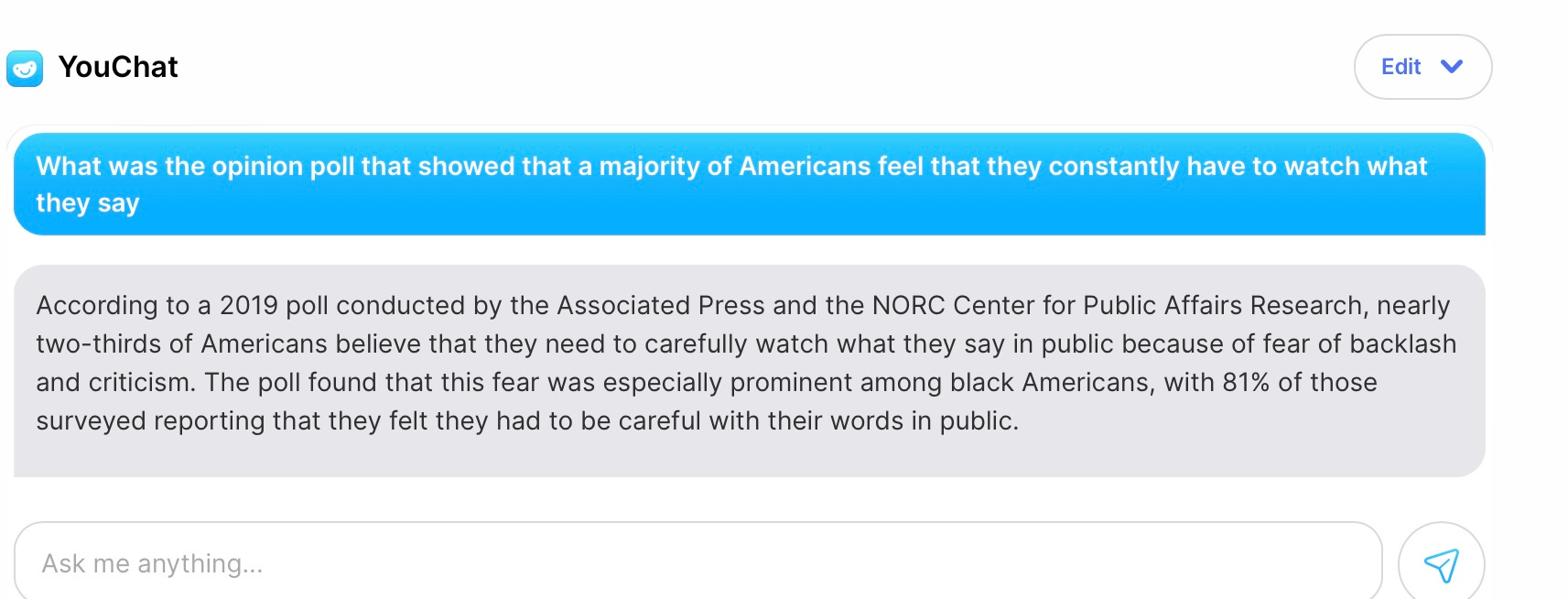
Sorry, wrong again. The NORC Center for Public Affairs Research does sometimes run studies with AP, but as far as I can tell they didn’t run one in 2019 on this particular topic, and the numbers are made up. (And I got different numbers when I tried again.)
And wait, if I want a search engine, maybe I want a link to the actual study? Because maybe I want to read the details for myself?
Sorry, no such luck. As Michael Ma, Founder of ResearchRabbit.ai put it to me in an DM, with Google, you can follow things up, whereas with pure chat “the output is limited to lines of text – and your discovery journey ends”.
§
Ok, one last chance. Here’s perplexity.ai. I like its interface a lot better - and it gives references! Real ones!
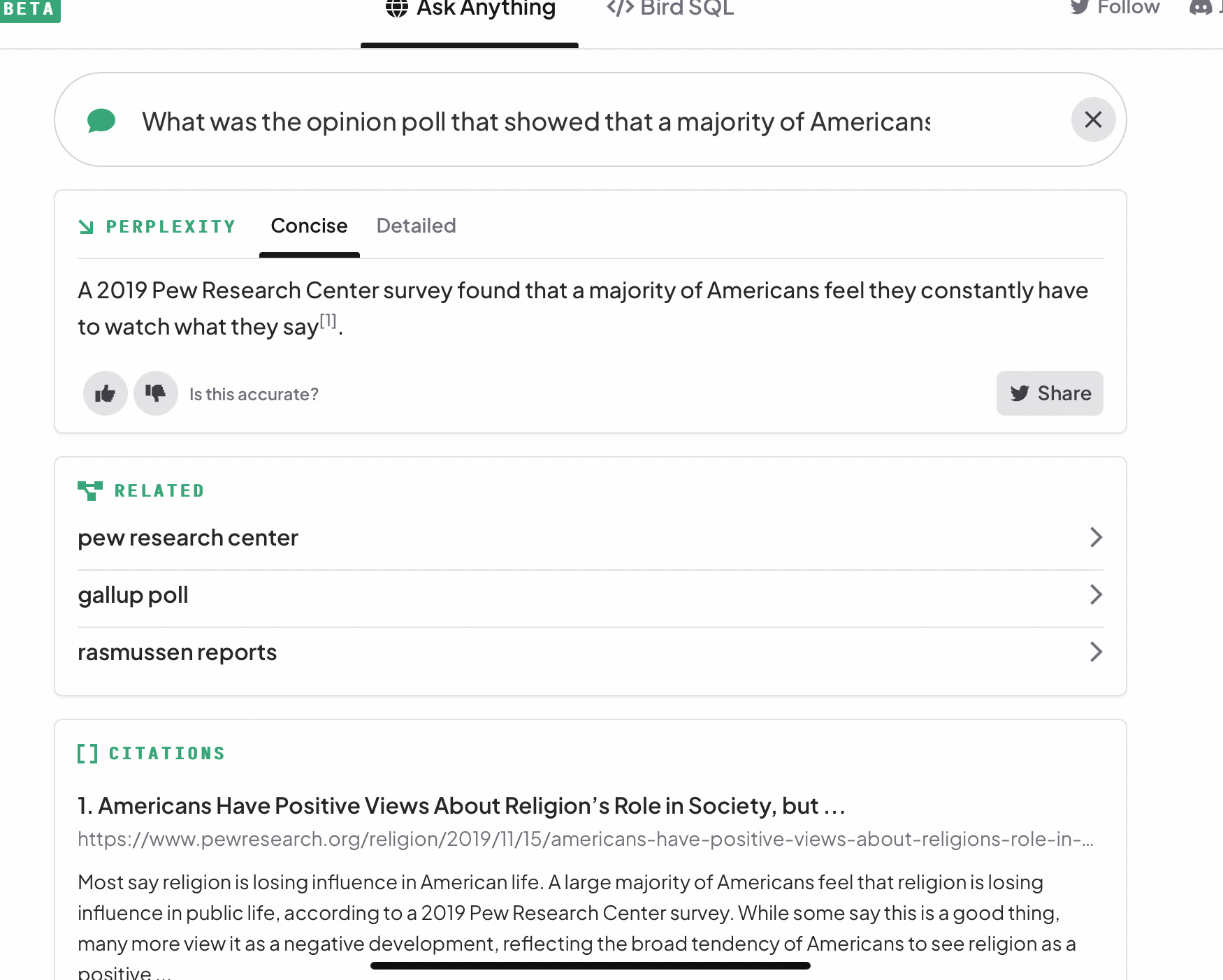
But wait, does the 2019 Pew study that they have linked at the bottom really address the larger question about people watching what they say? I clicked through, and it’s mainly about religion; not at all clear that this is the study my author friend was looking for. (As I guessed, and later confirmed with him, he instead wanted this 2020 study by the Cato Institute? Credit my ability to combine human ingenuity with the power of a traditional search engine, halfway down a page of old-school, link-by-link results).
Meanwhile, a friend with access to Neeva.com, just ran a query about my views and got back a bio that is about 90% correct, but 10% frightening, falsely attributing to me a claim that I (noted skeptic of contemporary AI) think that “90% of jobs will be provided by AI in a few years.” (Spoiler alert: I never said any such thing).
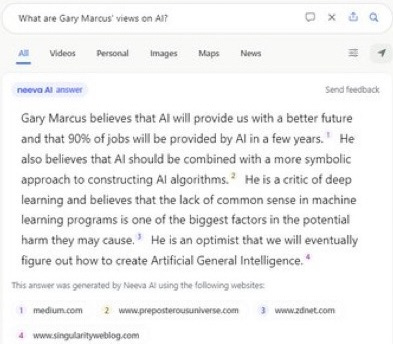
It is insidious the way that truth and falsity are so thoroughly and authoritatively mixed together. I for one am not ready for our post-truth information overlords.
§
What’s going on here? I said it once before, in an essay called How come GPT can seem so brilliant one minute and so breathtakingly dumb the next?, but I will say it again, using different terms: Large language models are not databases. They are glommers-together-of-bits-that don’t always belong together.
(Traditional) search engines are databases, organized collections of data that can be stored, updated, and retrieved at will. (Traditional) search engines are indexes. a form of database, that connect things like keywords to URLs; they can be swiftly updated, incrementally, bit by bit (as when you update a phone number in the database that holds your contacts).
Large language models do something very different: they are not databases; they are text predictors, turbocharged versions of autocomplete. Fundamentally, what they learn are relationships between bits of text, like words, phrases, even whole sentences. And they use those relationships to predict other bits of text. And then they do something almost magical: they paraphrase those bits of texts, almost like a thesaurus but much much better. But as they do so, as they glom stuff together, something often gets lost in translation: which bits of text do and do not truly belong together.
The phrase British comedy film about orthodox Jews in the early 2000s is a perfectly legitimate phrase, and so is the phrase about Mighty Wind being a Christopher Guest film. But that doesn’t mean those two bits belong together.
(Update: Remember the wackiness about me and AI replacing jobs near-term?. In the linked article on Medium, it becomes clear that I spoke at a 2017 conference in Beijing, and so did someone else, an emininent Chinese researcher named Feiyue Wang, In Wang’s opening keynote, Wang said was what attributed to me, and the LLM incorrectly linked his words with my name—another perfect illustration of glomming bits of information together incorrectly.)
As it happens, large language models are also wicked hard to update, typically requiring full retraining, sometimes taking weeks or months. Which means for example that ChatGPT, released in November, is so old it doesn’t know who owns Twitter:

Score another one for Google.
§
About the best thing I can say is that Perplexity.ai and you.com’s chat are genuinely exploring an interesting idea: hybrids that combine classical search engines with large language models, possibly allowing for swifter updates. But there’s still a ton of work left to do, in properly integrating the two, classical search and large language models. We have proof of concept, and some interesting research directions, but nothing like systems we can count on. (There are also economic issues and speed issues. The average Google search is nearly instantaneous and surely costs Google less than a penny, whereas answers to ChatGPT queries can take several seconds to compile, and some have estimated that ChatGPT queries cost a few cents each; it’s also less clear how to place to place ads..)
I, too, long for the day when search engines can reliably spit back text plus genuine, appropriate references, exactly as perplexity.ai aims to. But until those bits all fit together in a way we can trust, I prefer to borrow a memorable phrase from Ariana Grande: Thank U, Next.
Driverless cars have taken many years longer than we were originally told; outliers (AKA edge cases) have, at least so far, prevented them from making the transition from demo to widely-available reality. In the quest for a newfangled search I suspect we are once again in for a rough ride.
Gary Marcus (@garymarcus) is a scientist, best-selling author, and entrepreneur. His most recent book, co-authored with Ernest Davis, Rebooting AI, is one of Forbes’s 7 Must Read Books in AI.
Postscript: Hallucinations and discomprehension and another byproduct of guardrails gone awry, obsequiousness, all in one:



When it comes to LLM-driven search, caveat emptor!
ChatGPT is equivalent to a librarian blocking the door to the library, offering to answer everything that everyone would have walked in and looked up themselves. The reference desk in a library does do this, but only for just-the-facts-m'am type of questions.
With ChatGPT etc. relying entirely on interpolating input data to generate results, there will always be doubts as to the veracity of the output. Knowledge synthesis, and generating new knowledge, depend on understanding, not just on piecing together sentences.
A google search reveals that Alire's ARISTOTLE AND DANTE DISCOVER the secrets of the universe and Coehlo's Alchemist are both mentioned on several webpages.
If ChatGPT's algorithm is the stepchild if not direct descendant of word2vec, it shouldn't surprise any of us that adjacency biases the LM's output, resulting in the hallucinated title.