LLMs don’t do formal reasoning - and that is a HUGE problem
Important new study from Apple

A superb new article on LLMs from six AI researchers at Apple who were brave enough to challenge the dominant paradigm has just come out.
Everyone actively working with AI should read it, or at least this terrific X thread by senior author, Mehrdad Farajtabar, that summarizes what they observed. One key passage:
“we found no evidence of formal reasoning in language models …. Their behavior is better explained by sophisticated pattern matching—so fragile, in fact, that changing names can alter results by ~10%!”
One particularly damning result was a new task the Apple team developed, called GSM-NoOp

§
This kind of flaw, in which reasoning fails in light of distracting material, is not new. Robin Jia Percy Liang of Stanford ran a similar study, with similar results, back in 2017 (which Ernest Davis and I quoted in Rebooting AI, in 2019:

§
𝗧𝗵𝗲𝗿𝗲 𝗶𝘀 𝗷𝘂𝘀𝘁 𝗻𝗼 𝘄𝗮𝘆 𝗰𝗮𝗻 𝘆𝗼𝘂 𝗯𝘂𝗶𝗹𝗱 𝗿𝗲𝗹𝗶𝗮𝗯𝗹𝗲 𝗮𝗴𝗲𝗻𝘁𝘀 𝗼𝗻 𝘁𝗵𝗶𝘀 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻, where changing a word or two in irrelevant ways or adding a few bit of irrelevant info can give you a different answer.
§
Another manifestation of the lack of sufficiently abstract, formal reasoning in LLMs is the way in which performance often fall apart as problems are made bigger. This comes from a recent analysis of GPT o1 by Subbarao Kambhapati’s team:
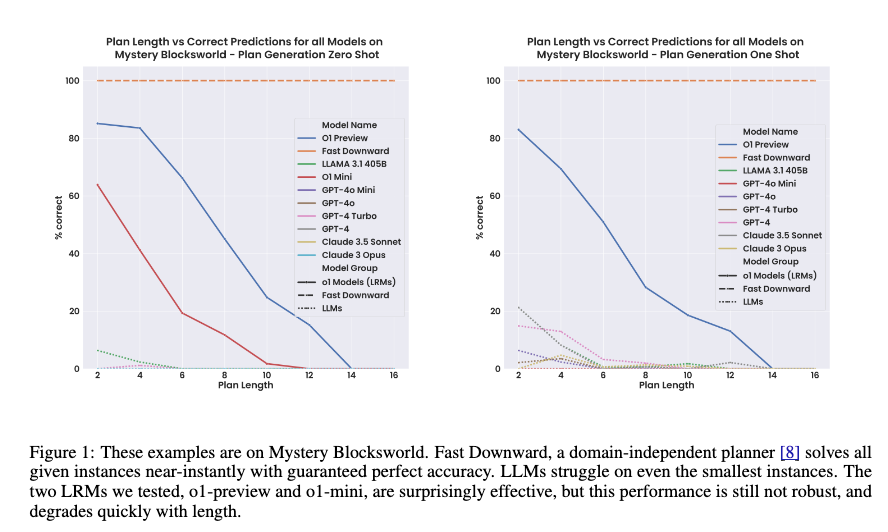
Performance is ok on small problems, but quickly tails off.
§
We can see the same thing on integer arithmetic. Fall off on increasingly large multiplication problems has repeatedly been observed, both in older models and newer models. (Compare with a calculator which would be at 100%.)
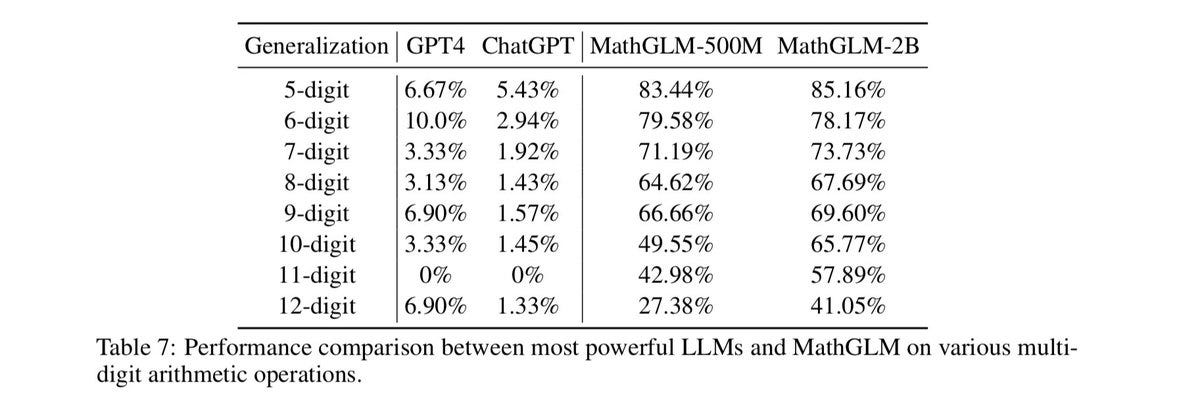
Even o1 suffers from this:
§
Failure to follow the rules of chess is another continuing failure of formal reasoning:
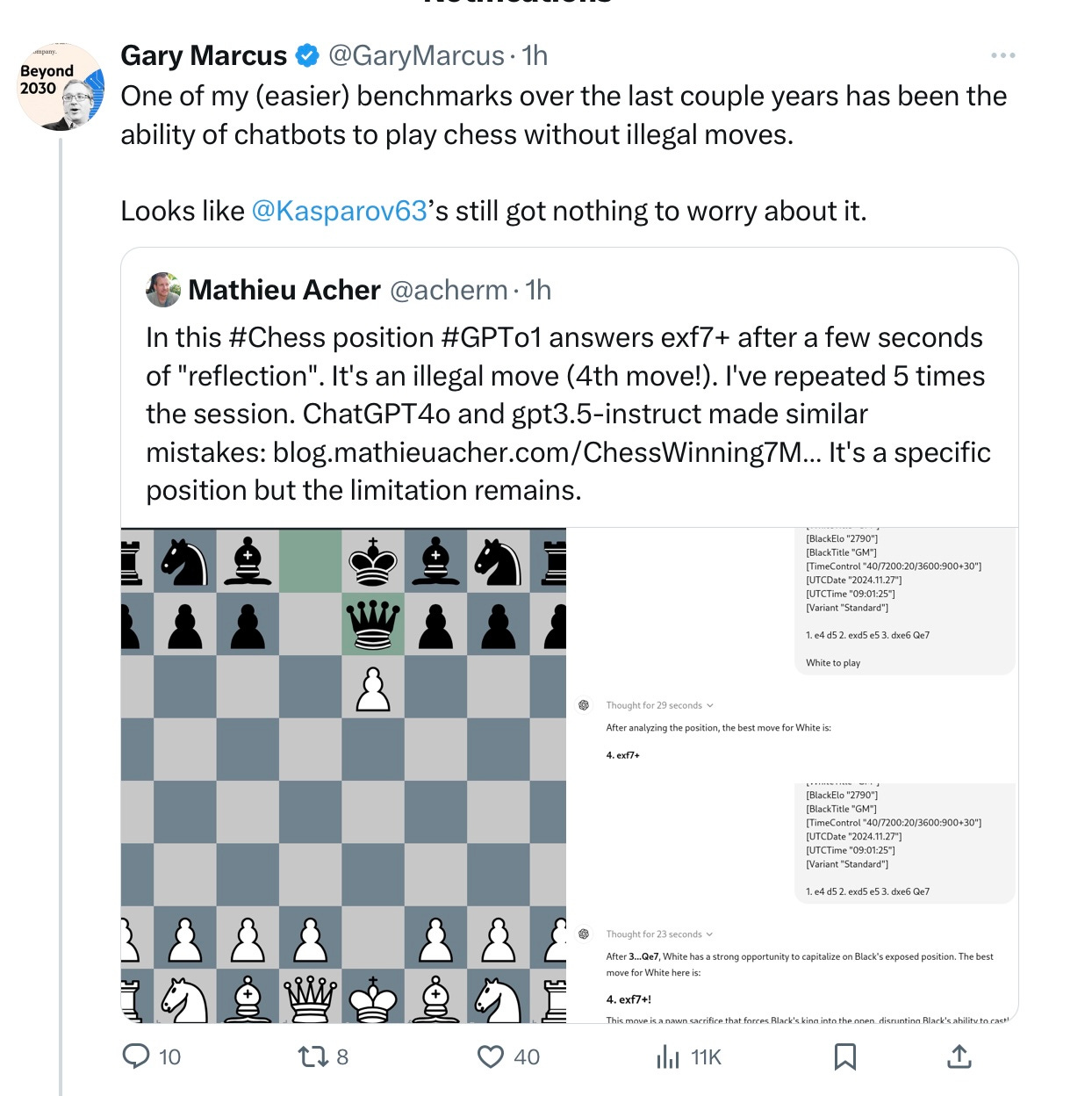
§
Elon Musk’s putative robotaxis are likely to suffer from a similar affliction: they may well work safely for the most common situations, but are also likely struggle to reason abstractly enough in some circumstances. (We are, however, unlikely ever to get systematic data on this, since the company isn’t transparent about what it has done or what the results are.)
§
The refuge of the LLM fan is always to write off any individual error. The patterns we see here, in the new Apple study, and the other recent work on math and planning (which fits with many previous studies), and even the anecdotal data on chess, are too broad and systematic for that.
§
The inability of standard neural network architectures to reliably extrapolate — and reason formally — has been the central theme of my own work back to 1998 and 2001, and has been a theme in all of my challenges to deep learning, going back to 2012, and LLMs in 2019.
I strongly believe the current results are robust. After a quarter century of “real soon now” promissory notes I would want a lot more than hand-waving to be convinced than at an LLM-compatible solution is in reach.
What I argued in 2001, in The Algebraic Mind, still holds: symbol manipulation, in which some knowledge is represented truly abstractly in terms of variables and operations over those variables, much as we see in algebra and traditional computer programming, must be part of the mix. Neurosymbolic AI — combining such machinery with neural networks – is likely a necessary condition for going forward.
Gary Marcus is the author of The Algebraic Mind, a 2001 MIT Press Book that foresaw the Achilles’ Heel of current models. In his most recent book, Taming Silicon Valley (also MIT Press), in Chapter 17, he discusses the need for alternative research strategies.
And yet. I see people increasingly finding that LLMs and other genAI are useful in ways that don't require reasoning. Summarize this article; advise me on how to make its tone more cheerful; give me ideas for a new product line; teach me the basics of Python; combine my plans with the images in these paintings so I can think differently about the building I'm designing. In these situations (all recently encountered by me, ie real uses, not hypotheticals), people are getting a lot out of supercharged pattern-matching. They aren't asking for impeccable reasoning ability, and so they aren't being disappointed.
These are "knowledge-work" settings in which the occasional error is not fatal. So, no quarrel with the larger point that we shouldn't ignore the absence of real reasoning in these systems. But it is also important to recognize that they're being found useful "as is." Which complicates the project of explaining that they shouldn't be given the keys to everything society needs done.
This is always a huge frustration for me. Even within groups that actually use AI more, and even engineers, I hear them talking about “reasoning”.
But we know and have known how LLMs work—and some of the results are super impressive! But they are fancy auto-completes that simulate having the ability to think, and those of us that use and actually build some of them should know—it’s a bunch of matrix multiplication to learn associations.
I respect the idea of emergent properties and this paper does a good job addressing it, but it’s just incredibly frustrating to hear people being loose with language who should know better. Including OpenAI with their new models.
Thanks for sharing the paper. Not that it’s surprising but great to see some formal work on it.