Misplaced panic over AI progress
Breaking down what METR’s latest “time horizon” graph does and does not show

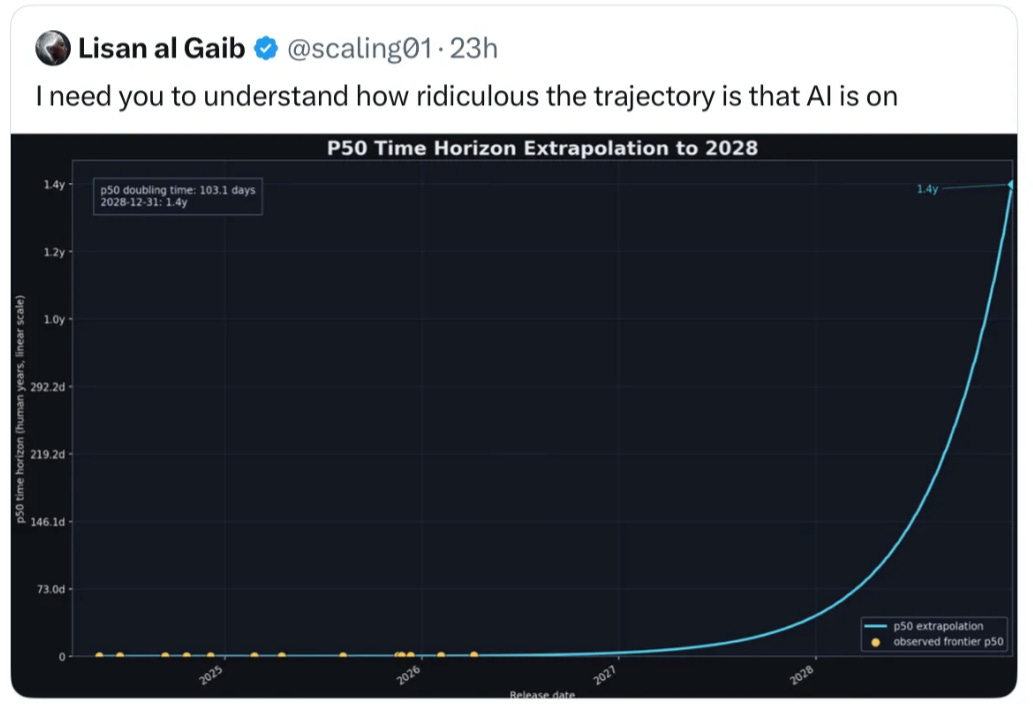
A couple days ago METR, a think tank that evaluates AI, dropped its latest graph, and the Twitterverse quickly became overwhelmed with panic, including a pile of tweets like these (and the one above):
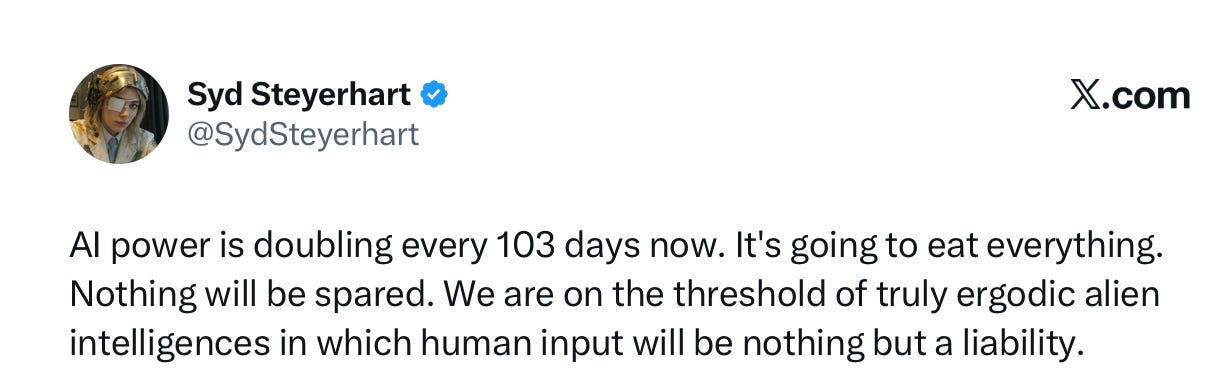
and
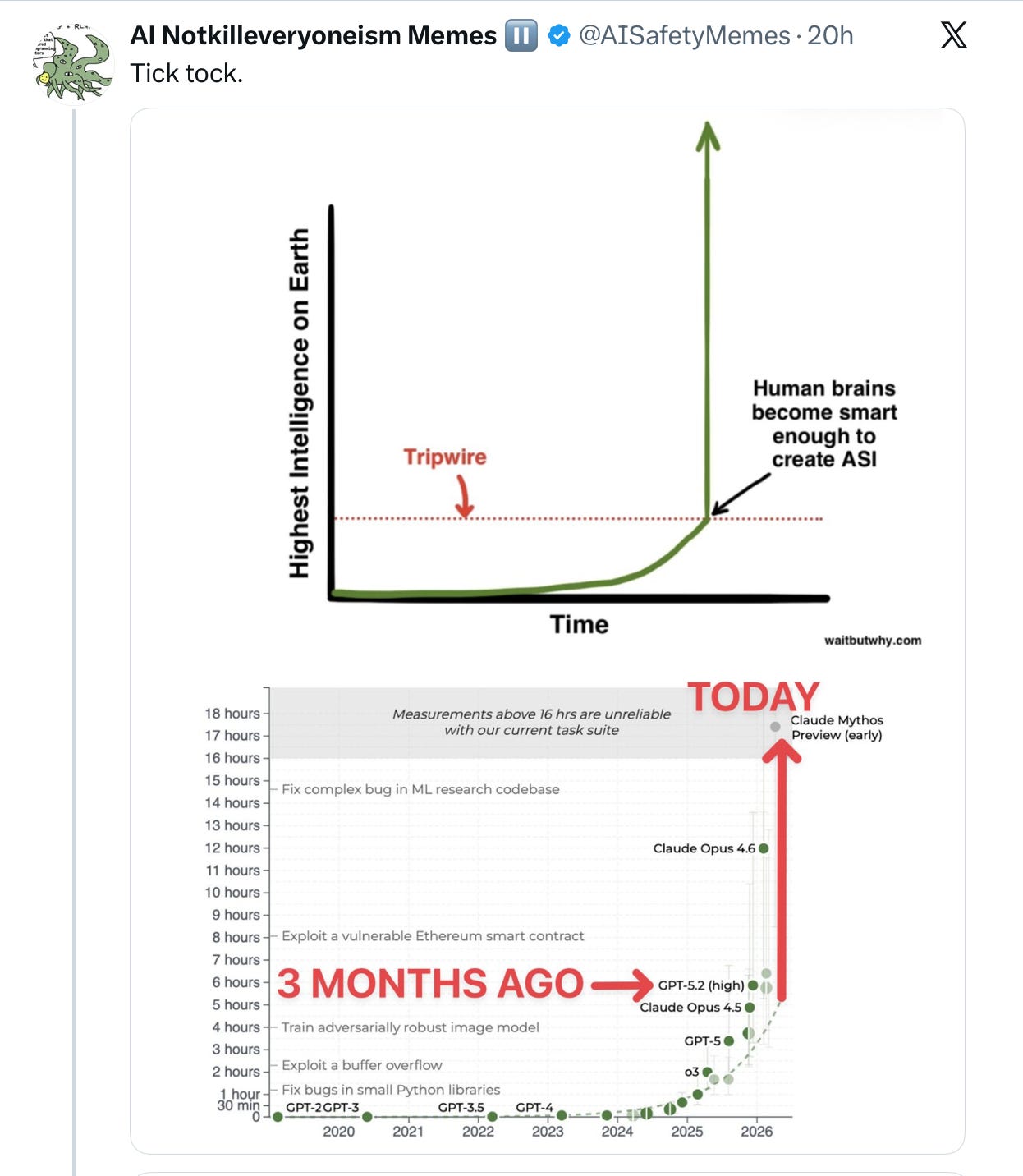
All were triggered by METR’s latest edition of their famous “time horizon” graph:


Even the usually sober forecaster Peter Wildeford worried that Mythos had “broken” the graph, meaning that we could no longer measure the limits of AI capabilities:
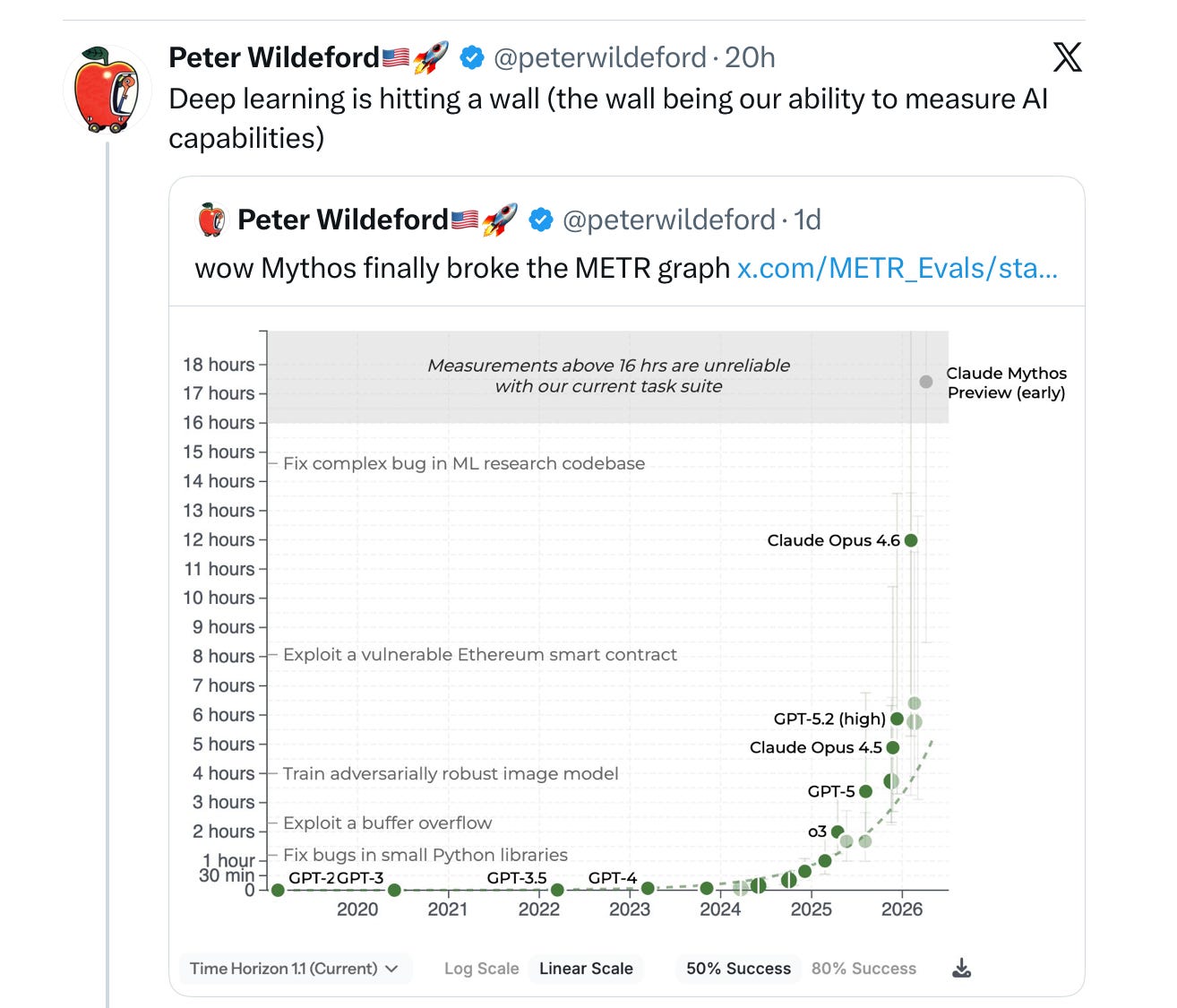
Hold on. Let’s take a deep breath.
(And let’s ignore the fact that “Deep learning is hitting a wall” was an essay about the limits of pure scaling, rather than what Wildeford is discussing.)
What the METR “time horizon” graph is measuring – with two important asterisks that I will get to — is the length (measured in time) of software development tasks that frontier models can complete, normed against human software engineers.
It used to be that the best “frontier models” could “succeed” at tasks that would occupy humans for a minute, then they could “succeed” at two minute task, then four, then eight etc; it’s up to sixteen hours now (but wait for the asterisks).
The implication is that systems are steadily getting better and better, at tasks that are more and more complex.
As Ernest Davis and I discussed a year ago, there are a bunch of problems with how the task is conceived and implemented, but for now let’s just stipulate for the sake of argument that the graph has been carefully made.
Here’s some context:
Claude Code is a real advance; Mythos probably builds on some of what is learned there. But…
If you read METR’s tweet about their graph carefully, it is about achieving *50%* success. Not 100 or 99 or even 90. (There is an 80% version, and it looks less ominous; it is the same general shape, but much lower overall performance.)
For exactly that reason, Wildeford’s concern about Mythos “breaking the graph” is a red herring. He’s saying that Mythos basically solves all the tasks that METR had prepared for the benchmark. And I don’t doubt that that’s true. But it’s only true at the arbitrary 50% success level. There is plenty of headroom left on the current METR set of tasks if you simply demand 80% success, even more headroom if you demand 95% success. (It’s also stacking the deck to only look at jobs that take a day or two, when the real job of a software engineer may involve overseeing projects that take months or years.)
More broadly, the key problem with GenAI has been reliability; a graph that demands only 50% success does not address reliable performance. At all.
The graph pertains only to software-development tasks. Not general intelligence.
It certainly doesn’t tell you that Mythos can do *most* things that humans can do in 16 hours, let alone do them reliably. (Example, watch a two-hour Hollywood movie that nobody has seen before and sensibly discuss key plot points.)
Importantly, the graph doesn’t show you *how* the improvements have been made. As noted in my newsletter, a lot of the advance in recent months is likely from the incorporation of symbolic tools (like code interpreters, verification, and harnesses) rather than from model scaling per se. (Incidentally, this is yet another vindication of neurosymbolic AI – not proof that LLMs themselves can be perpetually scaled. Nor a proof that another trillion dollars will indefinitely continue the trends shown in the graph.)
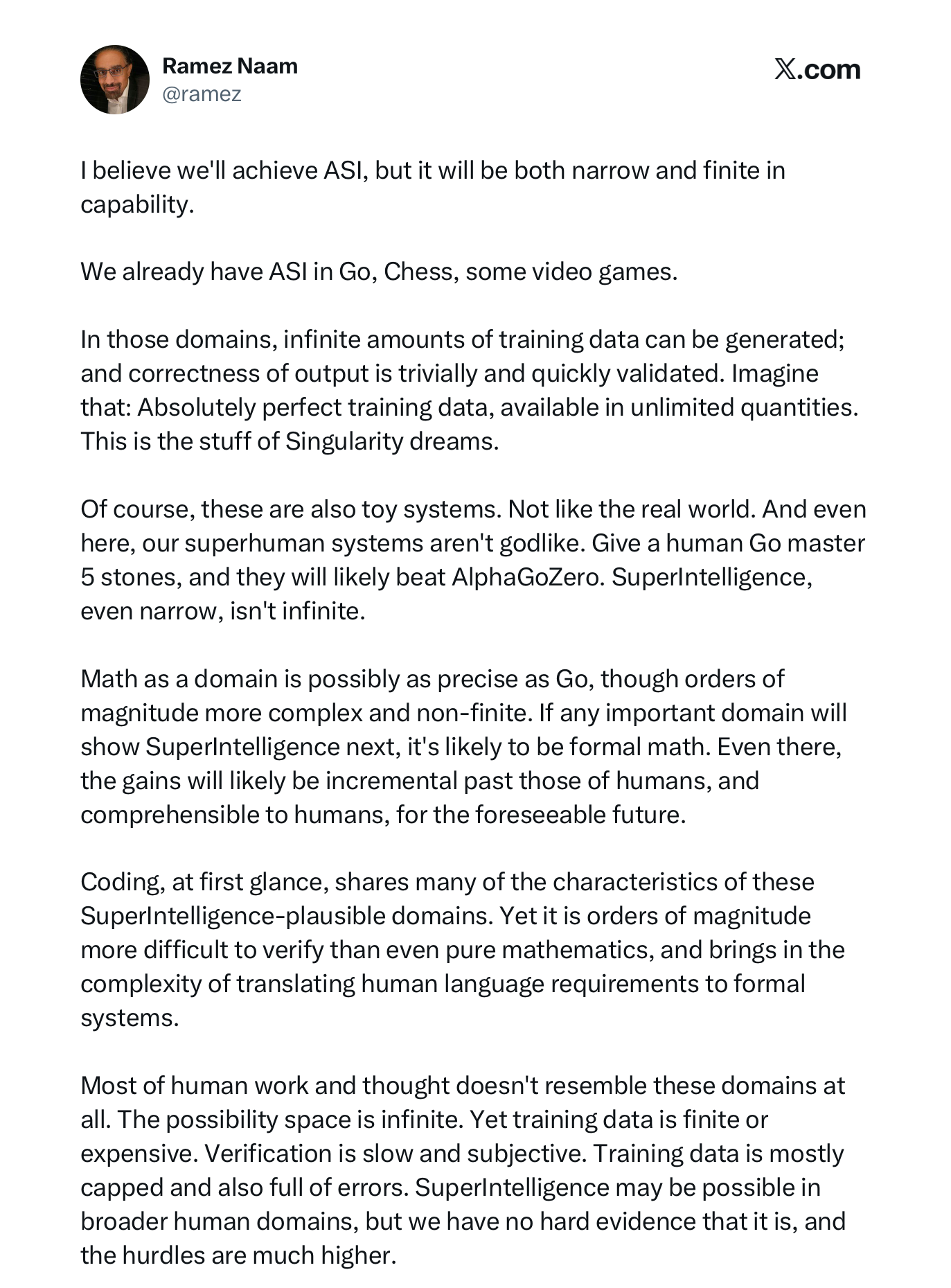
Per a graph that Ramez Naam showed a month ago, Mythos is not actually far off trend on the ECI benchmark, which is a broader measure.
 Ramez Naam@ramezAnthropic's Mythos does not appear to show any acceleration of ECI. After normalizing Anthropic's internal ECI with @EpochAIResearch 's public ECI, it's clear that the two metrics are extremely close, and that Mythos is pretty much on trend, just slightly above GPT 5.4. /1
Ramez Naam@ramezAnthropic's Mythos does not appear to show any acceleration of ECI. After normalizing Anthropic's internal ECI with @EpochAIResearch 's public ECI, it's clear that the two metrics are extremely close, and that Mythos is pretty much on trend, just slightly above GPT 5.4. /1 6:30 PM · Apr 8, 2026 · 409K Views40 Replies · 101 Reposts · 917 Likes
6:30 PM · Apr 8, 2026 · 409K Views40 Replies · 101 Reposts · 917 Likes

Bottom line: Mythos is awfully good at coding relative to its predecessors, but 50% is a low bar, and (a) we don’t have data at 95% or 99% success, we don’t know that the curves will keep going, and (b) we don’t have evidence that Mythos is actually an important step towards broad superintelligence.
Instead, its techniques likely work best with things like coding and math, where formal verification (good old symbolic AI for the win!) can straightforwardly apply.
Ramez Naam was sharp on this point, too, yesterday:
§
Here’s an even wilder extrapolation from a few days ago, about money rather than task performance:
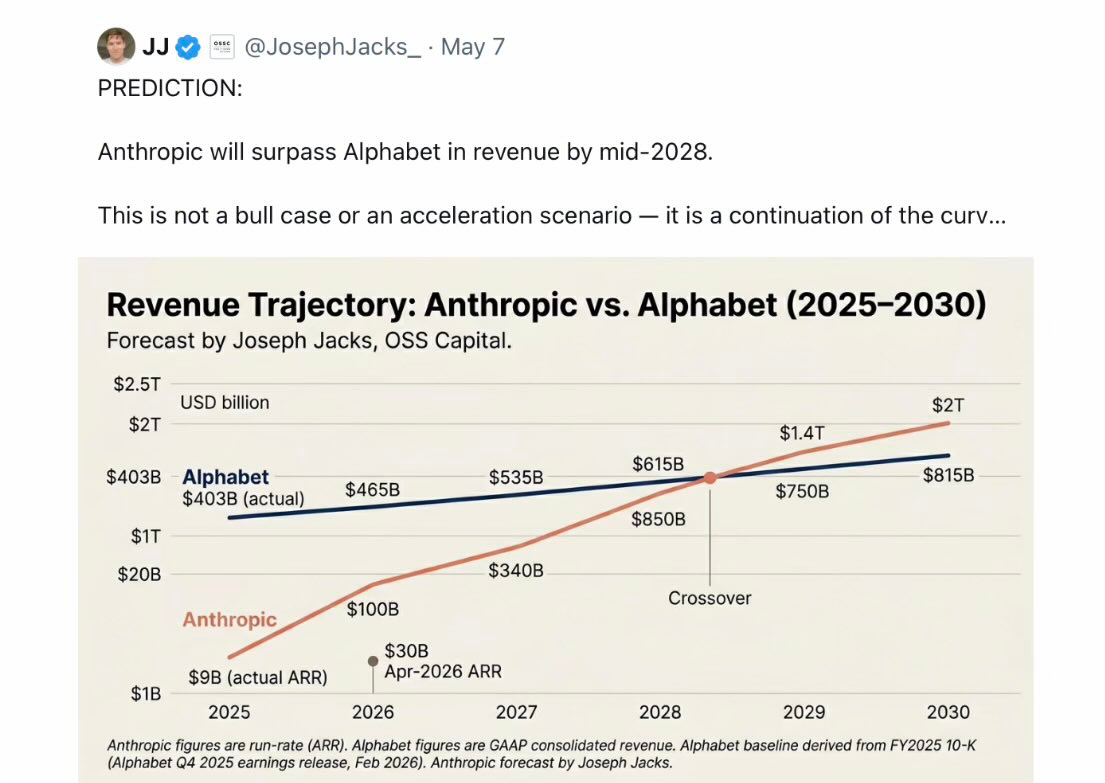
To anticipate that Anthropic will have $2T revenue in 2030 is a perfect example of what I have often called the trillion pound baby fallacy: Just because a baby doubles in weight in its first four months doesn’t mean it will continue to doubling every few months til he goes away to college.
§
Over and over I saw variants on the trillion pound baby fallacy yesterday with the METR graph, with people assuming that processes that initially doubled would continue unimpaired, indefinitely. Very few exponential processes do.
Babies don’t keep doubling forever, and nor will AI progress. We might hit resource constraints (energy, chips etc); “benchmarkmaxxing” (teaching to the test, which hears means building tools that focus around software design) may have limits; formal verification techinques may hit limits in less formal problems; some types of challanges (e.g., reasoning accurately with respect to world models, reducing hallucinations etc) may simply not be amenable to current approaches; and so on.
We can be absolutely sure that the task length “time horizon” for AI is not going to keep doubling until “time horizons will be 580 times the age of the universe” as Lisan al-Ghaib joked.
And most importantly, solving (some aspects of) software design is not open-ended intelligence. AI is definitely getting better at some things, but there is no reason to think that it is close to fully general yet.
My strong intuition is that Mythos will be under 20% and perhaps under 10% on the Remote Labor Index (a benchmark of percent of online tasks a bot can do), and with no meaningful improvement on doing physical jobs — which means the number of actual full human jobs that can be entirely replaced will remain small, at least for now.
In short, there is no need (yet?) to panic.
The 50% versus reliability distinction is the most important methodological point in this piece and it maps directly onto something I keep seeing in practice with teams deploying these tools.
A system that succeeds at 16-hour tasks 50% of the time is simultaneously two completley different products depending on who's using it and how. In a research setting where a human checks the output before anything ships, 50% success is genuinely transformative. You run the agent, review the result, keep the wins and discard the rest. Most developers using Claude Code right now work exactly this way and its why the product feels revolutionary to them even though the raw success rate would terrify an enterprise buyer.
In a production deployment where the output goes directly to a customer, 50% is a disaster. The reliability threshold for autonomous commercial use is somewhere between 95% and 99.9% depending on the domain and the METR graph doesnt tell you anything about how fast that gap is closing because it only measures the 50% line. The gap between 50% and 99% is where the entire "are we close to AGI" debate actually lives and I think thats the single most useful framing anyone can take from this piece.
The log-scale point needs to be said louder. Linear progress on a log scale looks exponential and the visual design of that graph is doing enormous persuasive work that the underlying data doesnt support. Plot the same improvements on a linear y-axis and you get steady incremental gains, impressive but not the hockey stick that triggered the panic.
Your observation about symbolic tools is the one that will age best though. If a big chunk of the improvement comes from models learning to use search and code execution tools rather than from the neural network getting fundamentally smarter then the progress curve hits a ceiling wherever tool integration saturates. And once it does the bottleneck shifts back to core reasoning which is exactly where the limitations youve been documenting for years reassert themselves. Both readings of this graph are probaly correct simultaneously and the honest response is somewhere between the panic and the dismissal.
I think the mistake is treating “task duration” as if it were a clean proxy for autonomy. A 16-hour software task can still be strangely narrow. Most real work is not like that: the hard part is not just doing longer chains of steps. It is knowing which problem matters, when the stated problem is wrong, which constraints are political rather than technical, when to stop, when to escalate, and what kind of mistake the organization can actually tolerate.
That is why I find the “longer tasks = imminent autonomy” framing misleading.