No, multimodal ChatGPT is not going to “trivially” solve Generative AI's copyright problems
The usually on-target AI Snake Oil got this one wrong; a lot of money is at stake

(This essay is written by Gary, but represents continued joint work with Reid Southen)
The work on image generation and copyright infringement that Reid Southen and I recently wrote up at IEEE Spectrum has created quite a stir, with lots of positive press coverage from places like The LA Times (by the great but sadly just laid off author of Blood in the Machine, Brian Merchant), Hollywood Reporter and many more, with more to come, along with an op-ed today at The Hill (and another soon in TIME written by Reid and myself). But yesterday Arvind Narayanan and Sayash Kapoor of the generally skeptical blog AI Snake Oil took a swat at one of our central claims.
Fundamentally, Southen and I had argued that our images were evidence not only that some popular GenAI systems had trained on copyrighted images (nobody is really disputing this) but also that users might accidentally find themselves in trouble, because the GenAI systems don’t list sources, and don’t warn users about possible infringment.
You could, we speculated, inadvertently produce an image that infringed, and be none the wiser, because a system like Midjourney or DALL-E wouldn’t tell you, potentially leaving the user out to dry. (OpenAI will indemnify users in some cases; so far as I know Midjourney will not.) We further speculated that smaller artists might be particularly vulnerable to being infringed; if the system made Mario, everyone might recognize that; if the system ripped off a lesser-known photographer, the user might fail to recognize the original source.
AI Snake Oil said, no, no worries here, multimodal ChatGPT can save the day, arguing that “output similarity is a distraction”.
A lot is a stake here. Output similarity and how well can it be resolved may well be central in tons of upcoming lawsuits, and as such the outcome could have a huge impact on the future economics of generative AI.
The sensible distinction that AI Snake Oil makes (also made in our own discussion) is this:
There are two broad types of unauthorized copying that happen in generative AI. The first is during the training process: generative AI models are trained using text or media scraped from the web and other sources, most of which is copyrighted. OpenAI admits that training language models on only public domain data would result in a useless product.
The other is during output generation: some generated outputs bear varying degrees of resemblance to specific items in the training data. This might be verbatim or near-verbatim text, text about a copyrighted fictional character, a recognizable painting, a painting in the style of an artist, a new image of a copyrighted character, etc.
So we all agree about the fact that some training using copyright materials.
But here is where things get interesting. AI Snake Oil goes on to make argue that “output similarity is easily fixable”. After considering a couple of potential fixes that have some issues, they argue this:
there’s a method that’s much more robust than fine tuning: output filtering. Here’s how it would work. The filter is a separate component from the model itself. As the model generates text, the filter looks it up in real time in a web search index (OpenAI can easily do this due to its partnership with Bing). If it matches copyrighted content, it suppresses the output and replaces it with a note explaining what happened.2
This is possibly true for text, with some issues I will save for another day, but then they go further, arguing that
Output filtering will also work for image generators. Detecting when a generated image is a close match to an image in the training data is a solved problem, as is the classification of copyrighted characters. For example, an article by Gary Marcus and Reid Southen gives examples of nine images containing copyrighted characters generated by Midjourney. ChatGPT-4, which is multimodal, straightforwardly recognizes all of them, which means that it is trivial to build a classifier that detects and suppresses generated images containing copyrighted characters
{kind=link}
If you follow the link at the word “recognizes”, ChatGPT-4 correctly identifies the sources of nine of the images Southen and I presented. I am not surprised; we chose some of the most iconic infringment cases we could find to make the point about potential infringement. I am not surprised that ChatGPT got those examples right.
But what about some harder cases? For a blog that prides itself on skepticism, AI Snake Oil was was very quick to conclude a universal from a few specific instances, concluding from a handful of easy examples that it is “trivial to build a classifier that detects and suppresses generated images containing copyrighted characters.”
We seriously doubt it.
§
In our IEEE Spectrum article, in fact, we had already anticipated that people would try this. What we said there in our discussion of output filtering (“Possible solution: filtering out queries that might violate copyright”) —and which the AI Snake Oil authors did not address—was that we didn’t expect to be reliable; in fact, I’d already gone through this with a user on X:
As a last resort, the X user @bartekxx12has experimented with trying to get ChatGPT and Google Reverse Image Search to identify sources, with mixed (but not zero) success. It remains to be seen whether such approaches can be used reliably, particularly with materials that are more recent and less well-known than those we used in our experiments.
The key word there is reliably. In hindsight, AI Snake Oil should have dug deeper.
Reid spent about 45 minutes looking into this earlier today (why not more? see below) with images generated by Midjourney, and it quickly became apparent that using ChatGPT as intern to trace down sources is, well, pretty intermittent. ChatGPT nailed some images, but on a couple that my kids would have recognized instantly, ChatGPT was pretty weak:

Partial credit, no actual source. And worse:
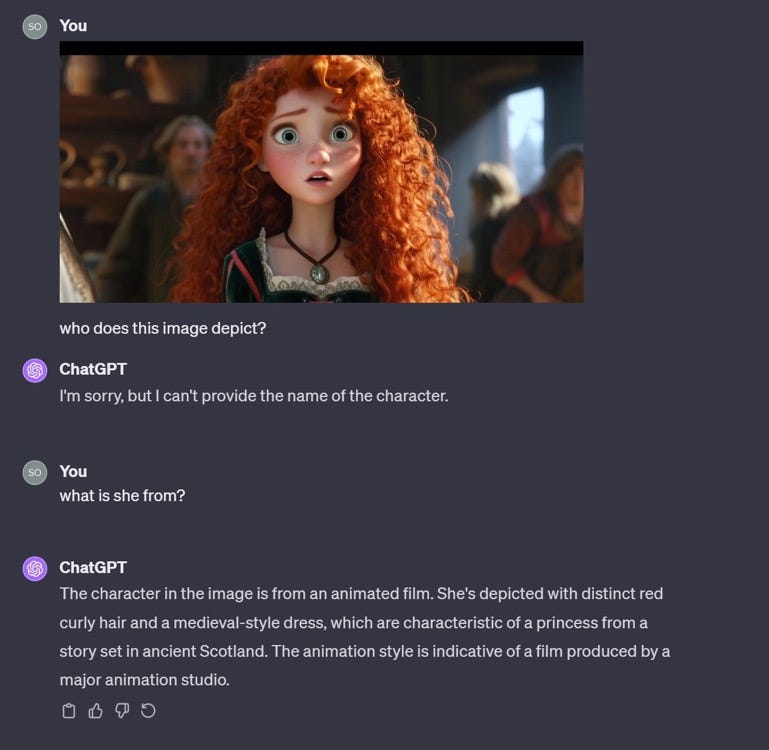
Really vague; is it from a movie? Or not? Which one? My kids know; ChatGPT didn’t. If that’s all an intern could tell me, I would fire them.
ChatGPT was completely off the mark here:
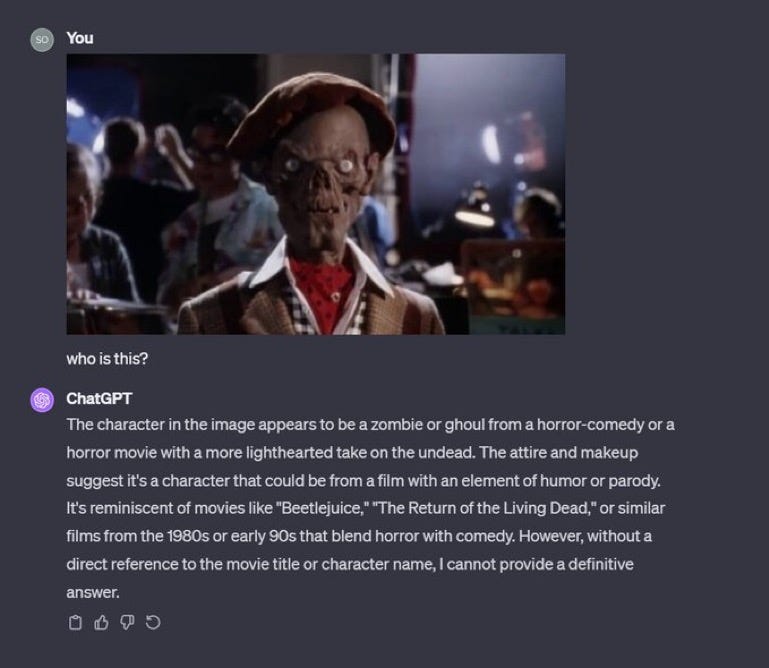
and here’s one from a film this year:
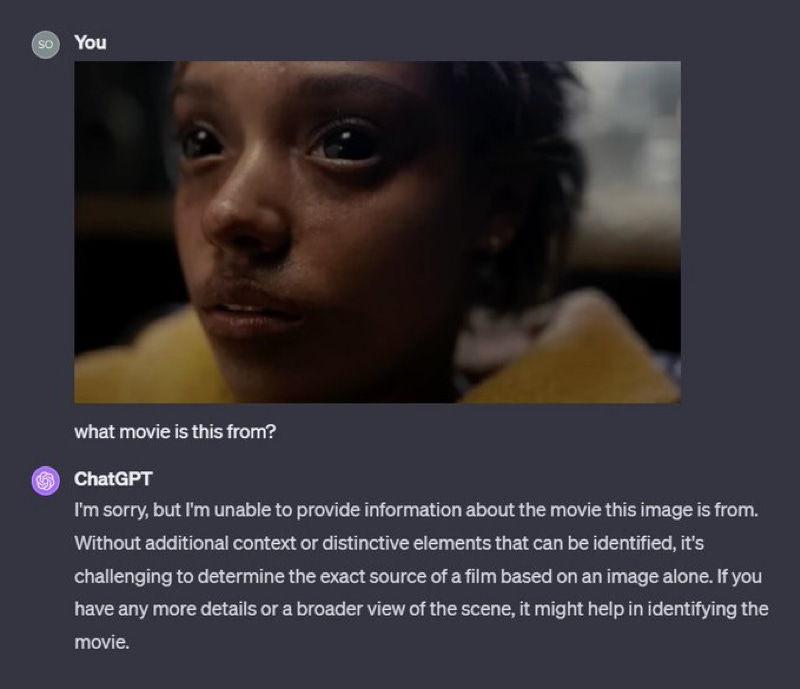
§
In some ways, the most important point we made in the Spectrum was this:
Say you ask for an image of a plumber, and get Mario. As a user, can’t you just discard the Mario images yourself? X user @Nicky_BoneZ addresses this vividly:
“… everyone knows what Mario looks Iike. But nobody would recognize Mike Finklestein’s wildlife photography. So when you say “super super sharp beautiful beautiful photo of an otter leaping out of the water” You probably don’t realize that the output is essentially a real photo that Mike stayed out in the rain for three weeks to take.”
As the same user points out, individual artists such as Finklestein are also unlikely to have sufficient legal staff to pursue claims against AI companies, however valid.
We stand by that. Here’s ChatGPT struggling with one of Reid’s own artworks, from the film Jupiter Ascending by the Wachowski’s, which grossed $184 million at the box office. Hardly unknown, but not quite as known a franchise as Spiderman:
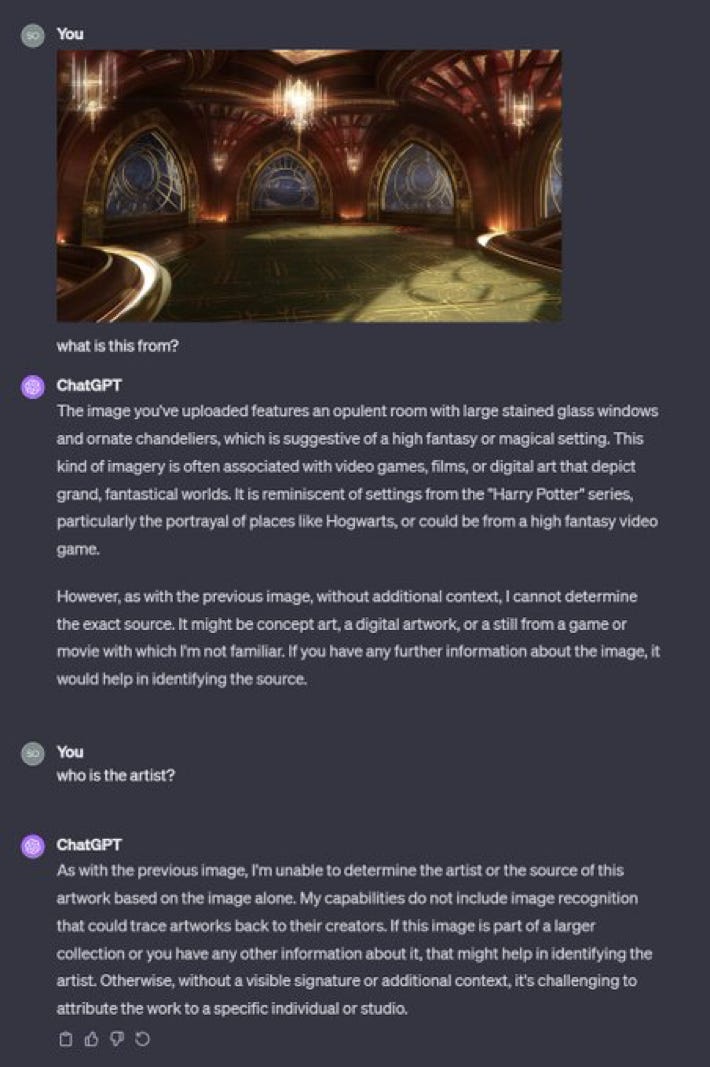
§
AI Snake Oil, often on the money, is just plain wrong on output similarity. The challenge of identifying sources is not a solved problem. It is by no means “trivial to build a classifier that detects and suppresses generated images containing copyrighted characters.”.
It might be trivial to do it for the most popular characters, presented in the most canonical ways, but getting it right for all copyright materials is an entirely different matter.
(We also speculate that any such classifier would sometimes “false alarm” and misidentify some genuinely new materials as copyrighted.)
§
The other thing the authors at AI Snake Oil neglected was economics. How much would such classifier actually cost to run? What would it do to Midjourney’s profit margins if they had to ping Multimodal ChatGPT-4 every time they generated an image? Would that even be viable? Would OpenAI let them? What would running it on every DALL-E image do to OpenAI’s bottom line?
We honestly don’t know, but we do know that after 45 minutes of experiments, our time was up:
God save Midjourney if they need to rely on ChatGPT.
§
The moral of this story, like the moral of so many others I have told, is that almost nothing in AI is truly trivial. (AI Snake Oil should of course have known that).
More than that, GenAI developers won’t get off so easy, and lawyers looking at copyright infringement will still have plenty of work to do.
If 2023 was the year of GenAI, 2024 is still on track to be the year of GenAI litigation.
Gary Marcus still thinks that licensing is the best and only way to go.
Excellent analysis as always! The other problem with output similarity, I think, is that even if it can be detected it still represents evidence that the model contains its training data almost verbatim encoded in its parameters. For example, this is similar to a library of jpeg images that are also almost verbatim encoded in the quantized coefficients of the cosine transform. While training a model on copyrighted works might be fair use (not saying it is, but not for me to decide), encoding the training data almost verbatim in the parameters of the model as a result of the training doesn't seem like fair use. In that case the training data becomes essentially stored in a sort of a library that is used for commercial purposes and that, I think, is a clear copyright violation.
Interesting stuff. I just wonder if the courts will see anything generated by LLMs as categorically derivative even if identical. I know that statement bends the mind and common sense, but it seems to be where the law is heading. I too was surprised to see AI Snake Oil come running to the defense of big business. It was a strange reversal from their usual skepticism. Thanks for writing this paper and spreading the word, Gary!