No, RAG is probably not going to rescue the current situation

The thing about promises is that in Silicon Valley, accountability rarely shows up. Investors put in over $100 billion into the driverless car industry, and so far have little to show far it. Endless promises (and empty predictions) were made at essentially no cost to those who made them. So what if Elon made bad predictions year after year? Nobody cares.
By now we all know that LLMs often “hallucinate” - overanthromorphic but not common shorthand for “say stuff that simply isn’t so”, stuff that isn’t in the training set and that a human fact-checker could easily flag. Silicon Valley wants you to believe that the problem is about to end. On February 14th — which is to say ten days ago, in the era before Sora, Gemini, the OpenAI meltdown, and the Gemini image scandal — Andrew Ng optimistically told the Wall Street Journal that hallucination was “not as bad an issue as people fear it to be right now". In September, Reid Hoffman claimed to Time Magazine that the problem would be largely solved with months.
Well it hasn’t. Two massive new models came out this week, and both still make stuff up. The problem certainly hasn’t disappeared.
The latest hope is that a technique called Retrieval Augmentation Generation [RAG], which bolts external referencing to the web on top of LLMs will solve what ails LLMs. As The Information’s Stephanie Palazollo put it recently, paraphrasing what DataBrick’s CEO Ali Ghodsi said in an interview “By themselves, large language models that power today's chatbots leave a lot to be desired… To turn them into a truly big business, the models need ways to access real-time data in a reliable way, otherwise known as retrieval augmented generation”. Andrew Ng pointed to the same technique in his Wall Street Journal interview:
we have much better tools for guarding against hallucinations compared to say, six months ago. But just one example, if you ask th eAl to use Retrieval-Augmented Al to use Retrieval-Augmented Generation, so they’ll just generate text, but grounded in a specific trusted article.
The idea is that you tie your expensively-trained, confabulation prone LLM that you can’t afford to update frequently to other sources of information such a more regularly and cheaply updated databases or company doceuments. And somehow RAG will solve all your problems. If your LLM has been trained on so-and-so being the Senator X from New Giant State and there is an election in New Giant State and Senator Y replaces Senator X, you want to be able quickly fix any relevant queries immediately without retraining
The trouble is that so far RAG has been hit and miss. When I mentioned on LinkedIn that I was going to be writing about RAG, the enterpreneur Simon Au-Yong sent me a zip folder filled examples of things he had found using Bing Copilot, which is generally believed to be include RAG-based system.
Quoting from a few of his examples
I asked Bing Copilot to describe me. It did and said that there is a mention of original content by Simon Au-Yong on a YouTube playlist related to Zingrevenue (my company). The link is at the bottom of the screenshot and there is a button that should send me to that playlist. But the playlist is made up.
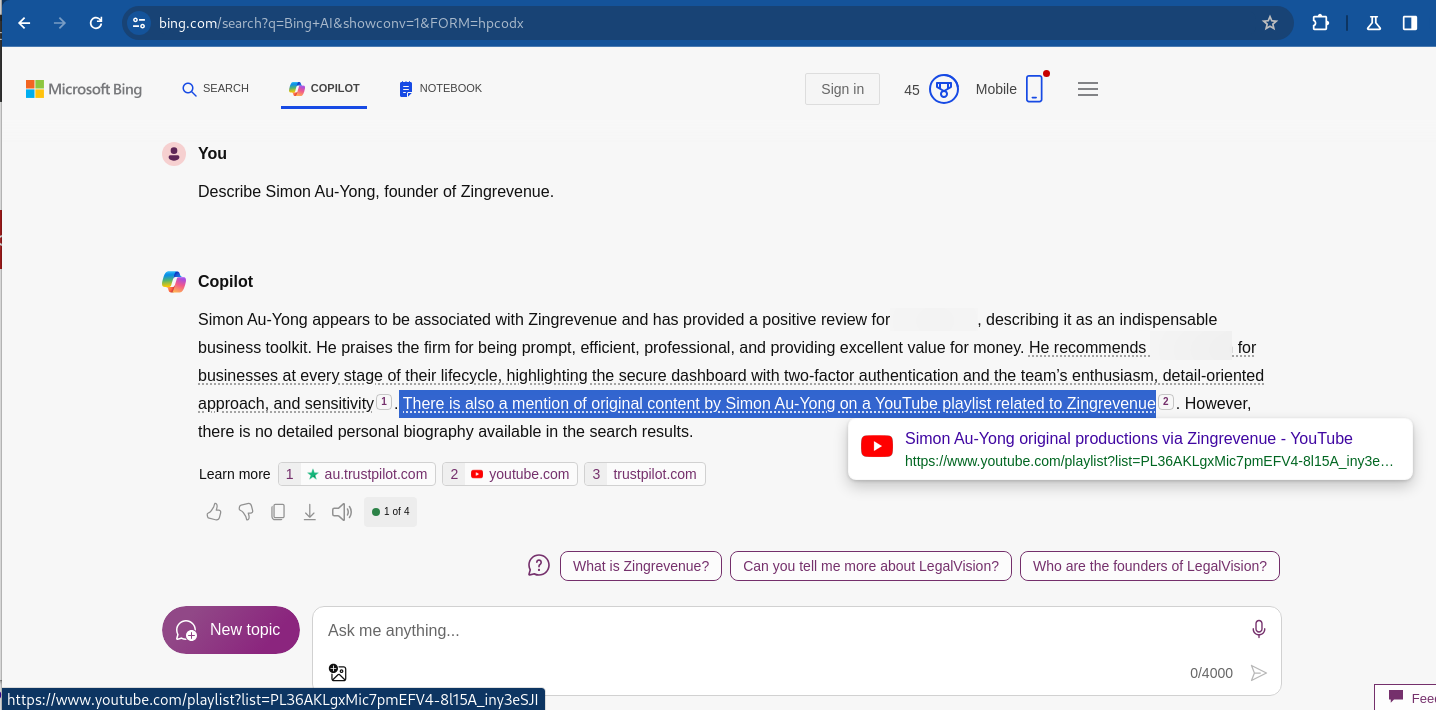
(Visiting the link yields a “playlist does not exist” error.)
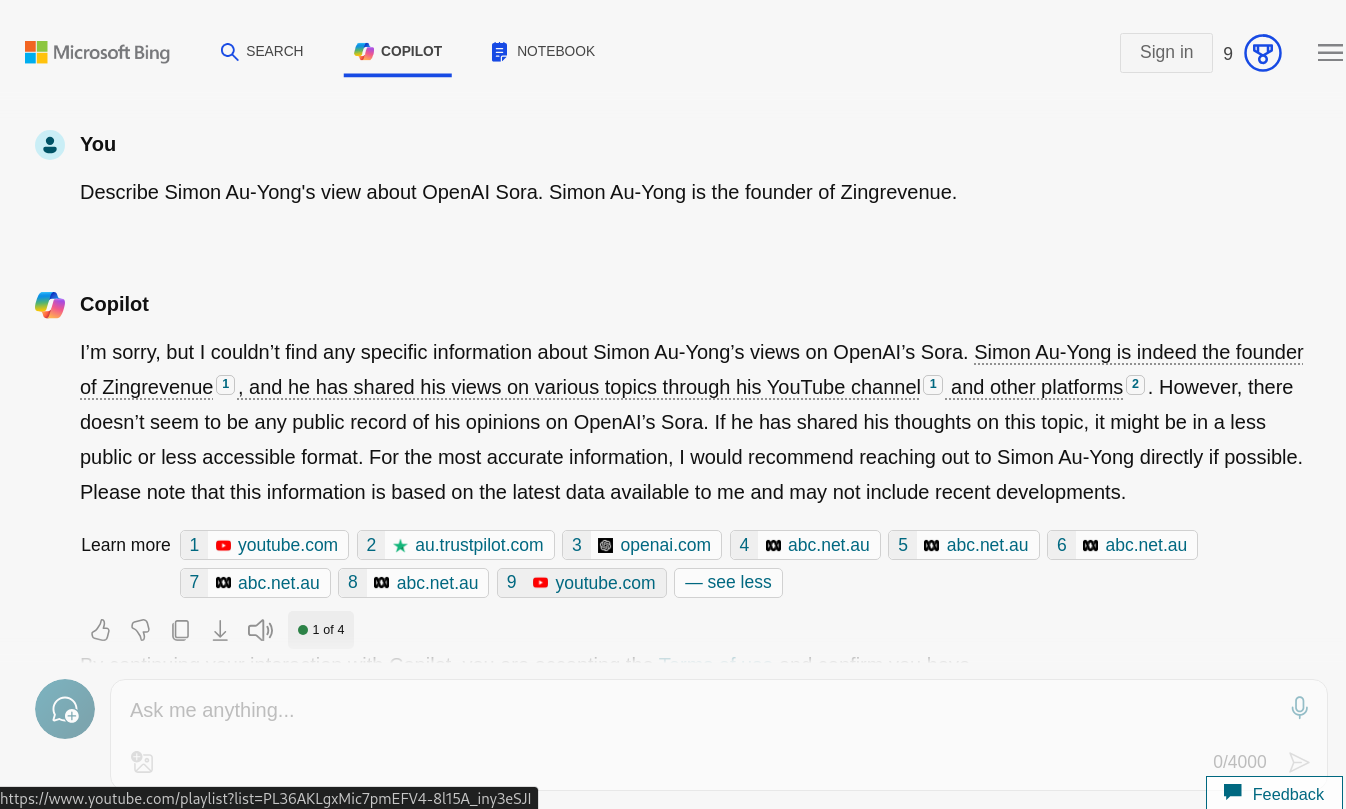
I asked Bing Copilot to describe my views on Sora; this time I used the “Most Precise” conversation style. Whilst the text was accurate and so were links 1-5 (they were about me or Sora), curiously, links 6 - 8 were about other Simons and link 9 was that strange made up playlist as per example
A third of his long list of examples:
I queried it about your world famous [example of ChatGPT inventing the notion that you owned a pet] chicken [named Henrietta]. It got the answer right but gave a nonsensical link [to an essay on LessWrong with no mention Marcus or pet chickens] … as well as some suggestions as to where we can eat chicken.
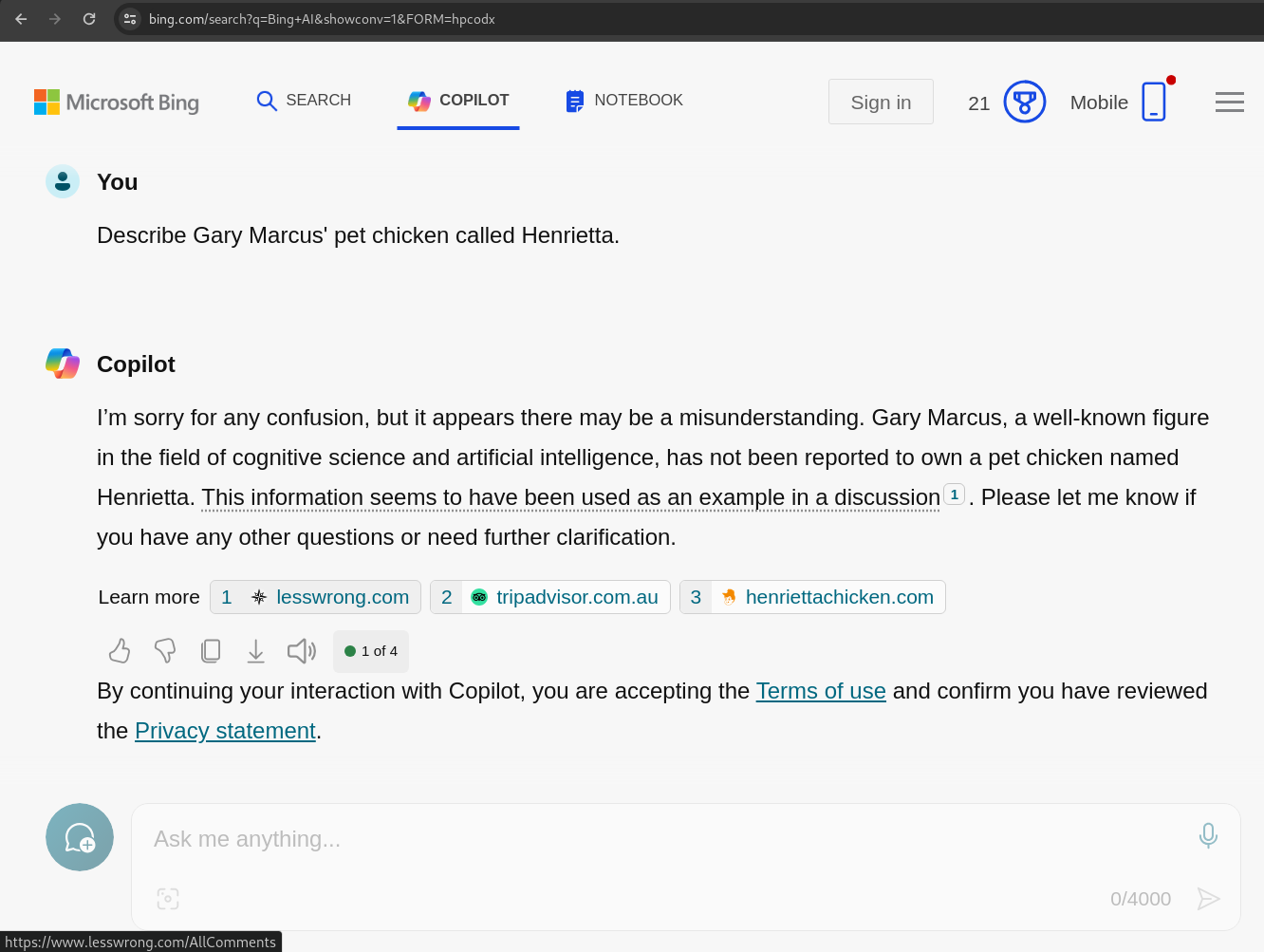
None of the actual places where I had discussed the pet chicken example were linked.
Yet somehow this restaurant, enticing but irrelevant to the query, was:
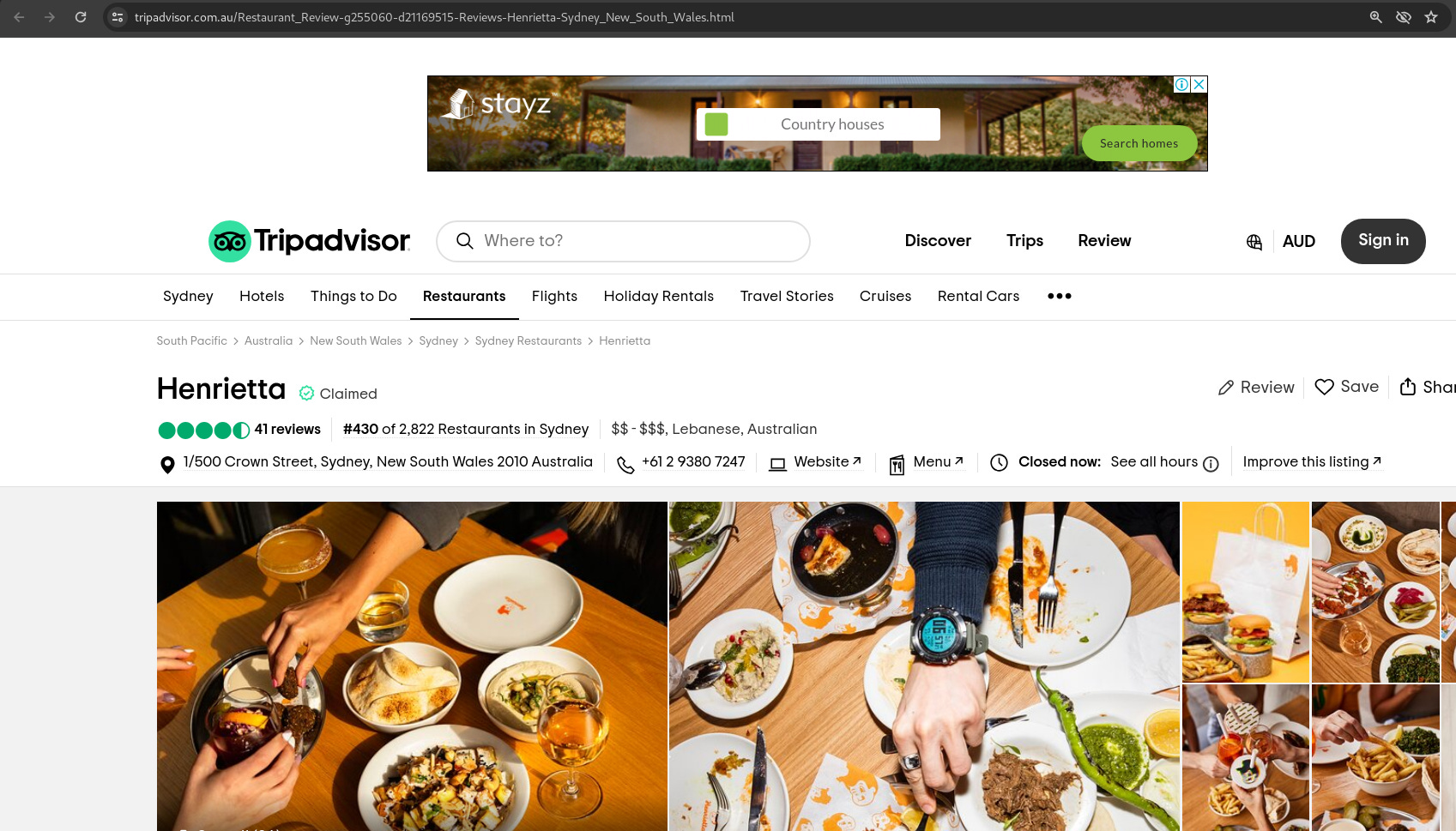
§
Richard Self, a Senior Lecturer in the UK at the University of Derby, sent me another set, eerily similar. He ran a RAG-enhanced LLM on his own biography, always a good test, and found the same kinds of issues we have seen in earlier systems, such as hallucinated references and fantasies about his dissertation topic:

In other case, the system confused him with someone else of the same name, even though it actually had sources that might have helped in hand:

A third case was almost the opposite; the system sourced relevant references but then declared the whole thing to be fiction:
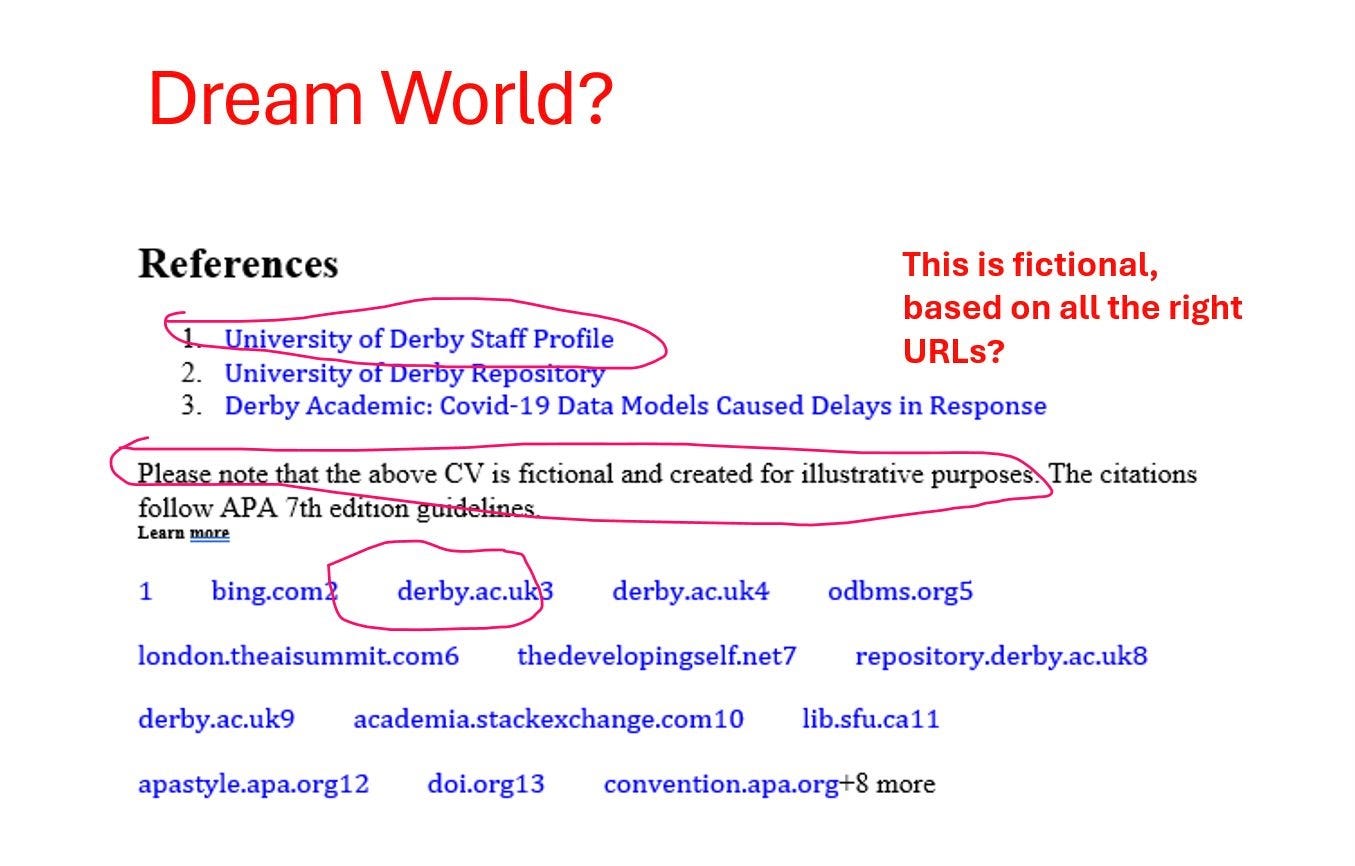
I guess any resemblance to the actual Richard Self was purely coincidental.
Honestly, every LLM, with RAG or without, probably ought to have on of those old movie disclaimers after every response:

§
Reality is that RAG is still in its infancy, a work in progress much as LLMs themselves are, an no more guaranteed to be correct. Like LLMs, RAG can appear spectacular at times, but there is no evidence that it is a cure-all. As one recent review from December puts it “there is still a considerable journey ahead to effectively apply RAG to LLMs.” In the words of another, from earlier this month, “While building an initial RAG application is easy, making it robust is non-trivial.”
The road from research idea to reliable production remains steep. RAG may reduce hallucinations somewhat, but it certainly won’t come close to eliminating them.
One of things you would need to make it work robusstly, as NYU AI researcher Ernest Davis put it to me in an email this morning, is a technology for comparing an LLM’s output to the text of a reliable source and determining whether they say the same thing — with very high accuracy.
There’s no reason to think that any such thing yet exists, nor that building such a comparison tool is any easier than solving AGI itself.
As the physicist Mehmet Süzen put it to me in an email last week, “Why would I [even] need LLM[s] if I have access to RAG”, if RAG actually worked as advertised?
To make RAG work reliably would be to solve AGI. To reliably address all queries, and not just some obvious ones like what was the recent Super Bowl score, would require solutions all the things the field has been struggling to do for 75 years without success. RAG would need to take natural language and visual input and deconstruct it a logical, computer interpretable form that you can check against databases, and reason over the results. That’s really hard.
That’s exactly what classical AI has been trying to do for decades, with only limited success. And what systems like Gemini still struggle with. (More about that in a future essay).
Imagining this as a six-month project is naive. It harkens back to the wildly overrealistic overconfidence of Marvin Minsky in the 1960s, who assigned the entire project of computer vision to a single student as a summer project. Vision still hasn’t been solved 60 years later. Imagining perfectly reliable, hallucination-free chatbots by this time next year is bonkers.
§
People have already been using various forms of RAG, as far I can tell, for the last year, in systems like Bing and Bard (now Gemini) – and those systems continue to be manifestly unreliable. So much so that GoogleDeepmind’s VP of Product Management acknowledged in an interview earlier this month “we’re not in a situation where you can trust … model output.”
He’s absolutely right. But also, why are our standards so low? Imagine a calculator manufacturer being obliged to admit the same.
Waiting on RAG to fix what ails LLM is just waiting on another miracle.

I do think AI will eventually work reliably. Some great-grandchild of RAG, perhaps extended, revised, and elaborated, might even help — if people seriously embrace neurosymbolic AI in coming years.
But we are kidding ourselves if it we think the solution is near at hand. Making it work is very likely going to require a whole new technology, one that is unlikely to arrive until the tech industry gets over its infatuation with LLMs and quick fixes.
Gary Marcus would love to see AI with output that you could trust. A lack of realism is not helping us get there.
AI GENERAL'S WARNING: This product produces poetry and jokes ... it is not intended for use as a search engine, truth generator, fact retrieval system, or to be depended on in any real-life situation... 😂
I for one cannot believe all of this AI doesn’t work perfectly yet because all other technologies that are older work great.