

Open letter responding to Yann LeCun
A memo for future intellectual historians

Yann LeCun asked me a question yesterday on LinkedIn, after I suggested that he had belatedly come around to some of my ideas. He asked “what idea” I had in mind. I actually have many.
Because LinkedIn limits the length of replies and number of links, and length is required in this context, my reply is posted below, as an open letter that I will also link on LinkedIn.
(If LeCun posts a rebuttal I will link it in an update to the below.)
§
Dear Yann,
Thank you for engaging.
My ideas, like yours, have been both positive (proposals about things we might do next) and negative (concerns about current approaches). As we both know, as scientists, you need a clear idea of what needs to be fixed before you can proceed, which is why you yourself preface nearly all of your recent talks with your own (extremely similar) ideas of where LLMs are stuck, e.g., this one last November:
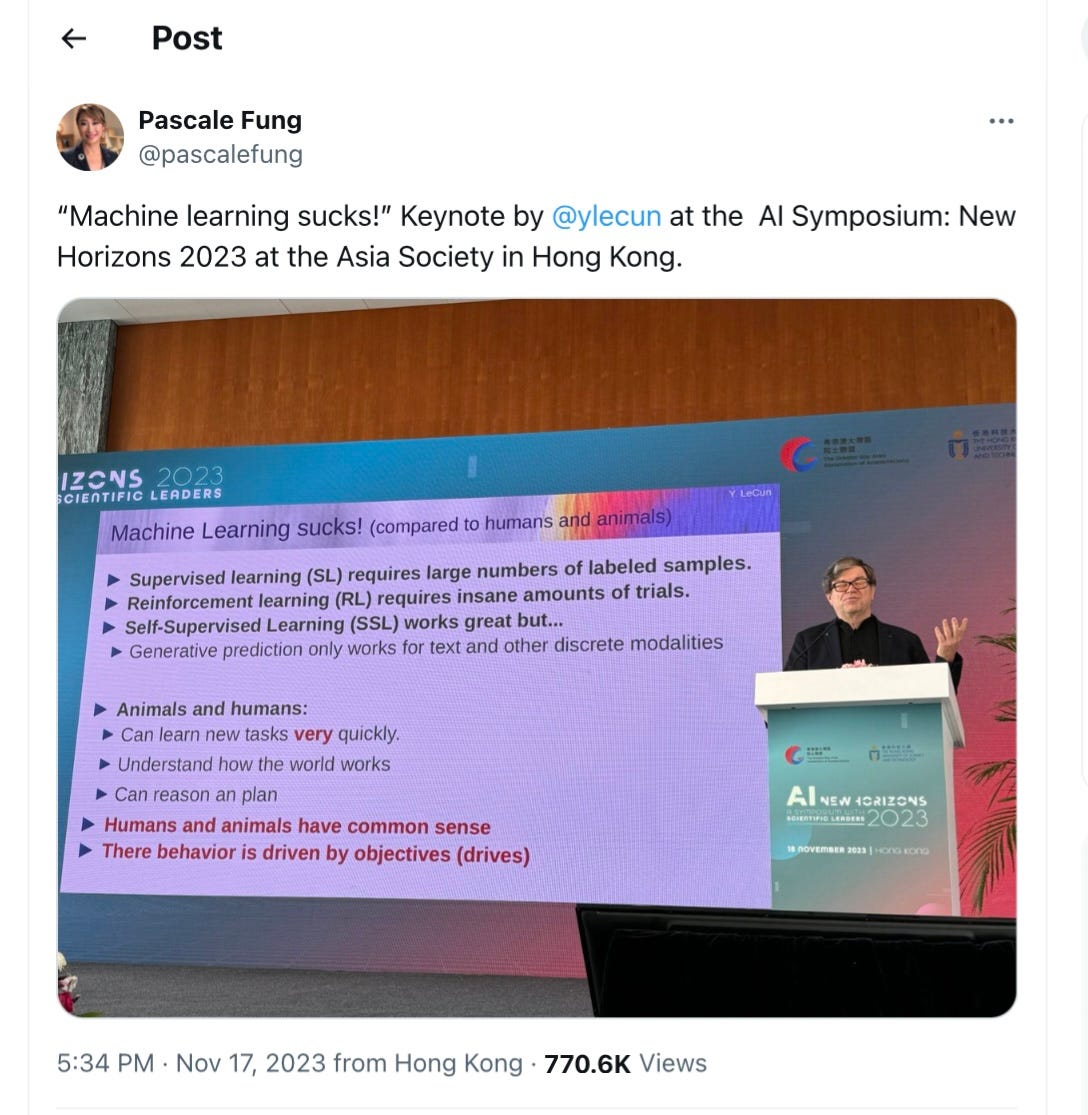
Let’s look at the critique side, first. Your current critique for what is wrong with LLMs overlaps heavily with what I said repeatedly—often to heated opposition from you—from 2018 to 2022 (and in some cases going back to 2001 and 2012). In my 2018 critique, Deep Learning: A Critical Appraisal, I argued that deep learning as we knew it then/as it was mostly commonly used then was greedy, heavily dependent on massive data, and that it would have trouble reasoning. At the time, you argued that all this was “mostly wrong”. The notion that humans are faster learners? I made that point in my 1999 experiments with human infants, which I directly contrasted with then-popular ML. The lack of world learning in machine learning ? That was THE central focus of my 2019 book with Davis. About the only thing on that slide that I haven’t emphasized for years is the bit about drives.
But what about LLMs in particular?
In 2019 I pointed out through a series of examples on Twitter with GPT-2 that LLMs were subject to essentially the same critique: greedy with respect to data, uninterpretable, unreliable as reasoners, subject to hallucinations, etc, that they lacked world models (“they don't develop robust representations of *how events unfold over time*), and that they would be inadequate on their own. When I initially pointed out these limitations, you alleged that I was “Wrong [and ]… ] fighting a rear-guard battle.” You in no way endorsed any of the claims I made then (though you frequently assert the same things now) You were also initially hostile to my 2022 paper that said scale was not all we need.
Nowadays, the introductions to virtually all your talks sound almost *exactly* like the ideas on what ailed LLMs that I was articulating then. Saying that LLMs are an “off-ramp” as you did only after ChatGPT appeared is just not that different from saying that current deep learning approaches are ”hitting a wall” or that (your words, not mine) “ML sucks”. If you want to argue that some future, as yet unknown form of deep learning will be better, fine, but with regards to what exists and is popular now, your view has come to mirror my own.
§
Turning to positive agenda, our ideas are again now similar, but again many of mine preceded yours. Nowadays we both (unlike many other people) stress the absolutely essential nature of common sense, physical reasoning and world models, and the failure of current architectures to handle those well. But that wasn’t always the case. The failure of contemporary neural networks to capture these things were the central themes in my 2019 book Rebooting AI with Ernest Davis (which you have been dismissive of) and in my 2020 arXiv article “The Next Decade in AI”; the emphasis on common sense and physical reasoning has been essential in my work with Ernie going back at least to 2013. Our 2015 ACM review anticipated the challenges that pure web mining (which is essentially what LLMs do) would face in capturing commonsense, reaching the conclusion that
“All of these programs are impressive — it is remarkable that you can get so far just relying on patterns of words, with almost no knowledge of larger-scale syntax, and no knowledge at all of semantics or of the relation of these words to external reality. Still, they seem unlikely to suffice for the kinds of commonsense reasoning discussed above”.
You have written some pretty similar things of late, like this in 2022
“LLMs have no stable body or abiding world to be sentient of—so their knowledge begins and ends with more words and their common-sense is always skin-deep. The goal is for AI systems to focus on the world being talked about, not the words themselves — but LLMs don’t grasp the distinction. There is no way to approximate this deep understanding solely through language; it’s just the wrong kind of thing.”
but at the time, back in 2015, you thought big deep nets were all you need, writing in Nature in 2015 that “big activity vectors, big weight matrices and scalar non-linearities … perform the type of fast ‘intuitive’ inference that underpins effortless commonsense reasoning” — dismissing then any need for specific efforts devoted to commonsense, physical reasoning or world models.
Once again you eventually come around to what Ernie and I have argued all along, now believing that LLMs (our most effective known uses of big activity vectors combined with big weight matrices) give you none of that for free.
§
To take a different kind of example, I have long argued that models need to innately be more structured than pure multilayer perceptions, even prior to learning. In our 2017 debate, you argued (against me) that we didn’t need any innate structure. But your current approach (JEPA) has several distinct modules (e.g, for perception distinct from memory distinct from action distinct from a critic) — with that overall structure (though not exact wrights) given innately, prior to experience.
Of course my biggest (and most difficult to confirm or reject) positive conjectures, all made in 2001 in The Algebraic Mind, remain speculative: the importance of representing kinds distinctly from individuals, separating reasoning from latent representations, incorporating explicit compositional structure and explicit operations over variables, incorporating some degree of innate pre learning, and exploiting explicit knowledge databases. I stand by all of them. Importantly, DeepMind, among others, has achieved some strong results with neurosymbolic approaches (e.g., AlphaGeometry). Meta’s Cicero is another example.
§
At this point, there is a clear pattern: you often initially dismiss my ideas, only to converge on the same place later — without ever citing my earlier arguments, a clear academic no-no.
The irony of all of this is that you and I are among the minority of people who have come to fully understand just how limited LLMs are, and what we need to do next. We should be allies.
If we put our heads together, we might even think of something good.
Gary
I'd be very interested to know some of the thinking and underlying observations that caused Yann to change his mind on these issues. It can be very difficult for people to publicly reverse themselves on almost anything, even more so something so close to their area of expertise, and possibly so intertwined with their scientific reputation.
Having grown up in between a physics lab (father) and a computer (my mother was a ...), and then spectator of decades of knock down drag out scientific brawling, the biggest research question I was left with was .... 'what makes smart people so stupid?'.
Kathryn Myronuk does a good talk on 'the failure modes of experts'