

OpenAI’s Lies and Half-Truths
Not every thing the company says is completely candid.

The internet has gone bananas over Wall Street Journal reporter Joanna Stern’s interview of OpenAI’s CTO Mira Murati, mainly about how Murati dodged and weaved when asked what Sora was trained on.
Dare Obasanjo described it as “a master class in how NOT to answer an obvious question”:
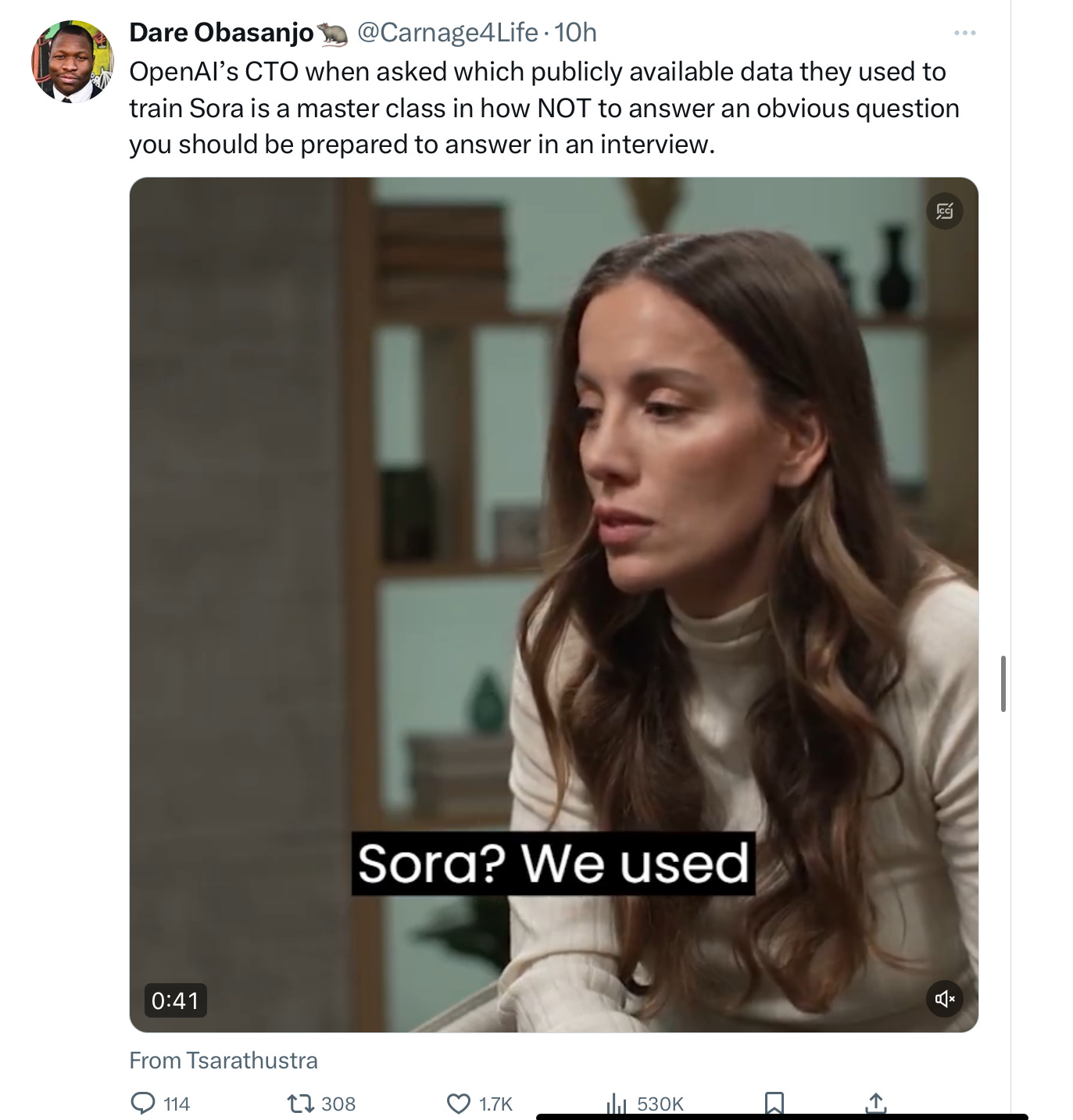
DCN’s Jason Kint urged us to watch her blink while she talks.
Journalist Chris Stokel-Walker posted this

AI researcher and composer turned AI activist Ed Newton-Rex posted a hilarious video of monkeys stealing hubcaps, under the legend “when your data is publicly available”.
In an X post promoting the interview, WSJ’s Joanna Stern said “Come for her insightful analysis of new AI video clips and her answers about when it's coming out. Stay for the non-answers about if YouTube and other video data was used to train the model.”
Journalist Sharon Goldman weighed in, too, making exactly the right points about trust and transparency:

I said

Aside from all that, Murati claimed she had no idea what specific data Sora was trained on; given her role as CTO that seems all but inconceivable.
§
But Murati’s evasion is not new — it’s part of longstanding pattern.
Here are some highlights over the years. What they have said, and what it really means:
OpenAI, 2015:”Researchers will be strongly encouraged to publish their work, whether as papers, blog posts, or code, and our patents (if any) will be shared with the world. We’ll freely collaborate with others across many institutions and expect to work with companies to research and deploy new technologies.”
Translation: We are happy to let the public believe that we are open, but it’s really just a recruiting promise that we don’t intend to live up to (Ilya, January 2016) – but we shouldn’t disabuse people of that notion (Sam, May 2016).
Meanwhile, phrases in official filings like“Charitable” and “For the public benefit” don’t seem to have meant much at all.
§
Press release, October 2019: We are “solving a Rubik’s cube with one hand”.
Translation: Using a well-known algorithm that we didn’t invent to decide which faces of the cube to turn, we taught a robot to do motor control on a specially instrumented Rubik’s cube with bluetooth sensors inside.
§
Co-Founder and then CTO Greg Brockman, in email to me August, 2020, when I requested access to GPT-3: “Thanks for reaching out. We have tens of thousands of beta requests…... We're actually very excited to invite folks interested in scientific evaluation of the model ... So yes, we will definitely make sure to invite you (and even give you special priority, because fair criticism and thorough evaluation helps drive progress), but it will take some time.”
Translation : We will never, ever give you advanced access to red-team any of our software. [Narrator: and they never have.]
§
Sam Altman, to the Senate, May 2023: I love my job, and don’t have any equity in OpenAI
Translation: But I do have equity in YCombinator and YCombinator has equity in OpenAI. It’s probably worth a lot, but you wouldn’t like me as much if I acknowledged that, so I won’t. Also, did I mention I own the OpenAI venture fund? Nope, guess not, sorry.
§
Sam Altman, also to the Senate, May 2023: Please regulate us
Translation: But (revealed a few weeks later) behind the scenes we will try hard to water down your regulations.
§
Sam Altman, June 2023, asked when if ever he would pause AI development, said if “the models are improving in ways that we don't fully understand, that would be one.”
Translation: Kidding! “We can predict with confidence that the GPT paradigm is going to get more capable but exactly how is a little bit hard. For example, why a new capability emerges at this scale and not that one. We don’t yet understand that. If we assume this [current] GPT paradigm is the only breakthrough that’s going to happen, we’re going to be unprepared for very major new things that do happen.” But no way are we slowing down.
§
Murati brings us right up to the present, March 2024: We used “publicly available and licensed” materials to train Sora.
Translation: We licensed some, and took whatever else we could find, licensed or not.
§
And there you have it. Half truths about openness, about what data they are training on, about finances, about their views on regulation, about when if ever they would pause, and more, essentially every topic that matters, from the day they were launched all the way to the present. A lack of full candor seems to run straight through the corporate DNA.
As the company gears up to upload your private email, calendar, and documents, possibly for eventual resale to advertisers, that’s something worth considering.
Never mind what might happen if Altman’s worst fears about rogue AI ever materialize.
Gary Marcus will not deny that he is disturbed by many of things he has noted from OpenAI over the years.
with humans like that, who needs rogue AI
I'm startin' to believe they maybe tole a few fibs! Is OpenAI looking to dethrone Meta for most mendacious and exploitative tech company? It's stiff competition with Zuckerberg and LeCun at Meta, but I believe in you Sam and Mira, I really do!