Satya Nadella and the three stages of scientific truth
A textbook case in how good ideas are often initially throttled


Prelude: A conjecture is issued
In early March 2022 I wrote an essay for Nautilus that went viral but also almost killed my career, engendering more hate than anything I have ever written. I conjectured that deep learning, at least as we knew it, instantiated by LLMs, would hit a wall, and that new approaches would be needed sooner or later.
The crux of the argument was this
the so-called [LLM] scaling laws aren’t universal laws like gravity but rather mere observations that might not hold forever, much like Moore’s law, a trend in computer chip production that held for decades but arguably began to slow a decade ago…. we may already [be] approaching a point of diminishing returns… [The question becomes] What else might we need?
The point was that we probably needed new architectures.
Act I: ”In the first stage it is ridiculed”
Hundreds (maybe thousands) of people derided these notions. Here are few that were popular:
April 2022:

May 2022
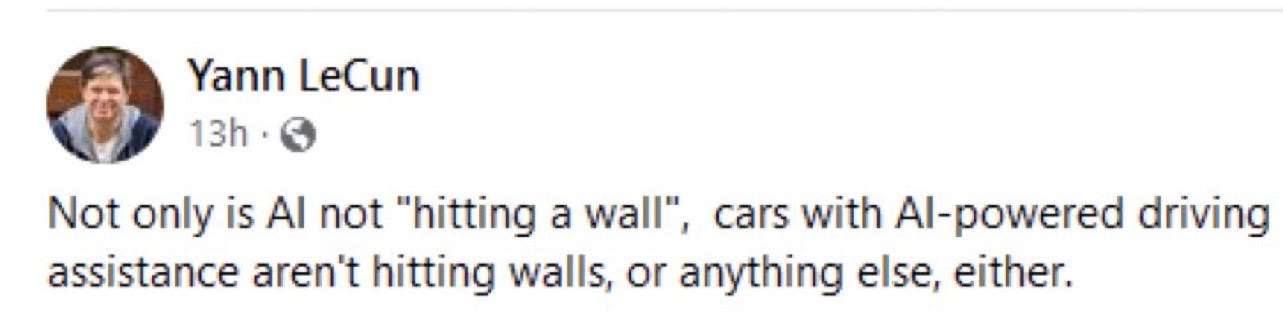
June 2024
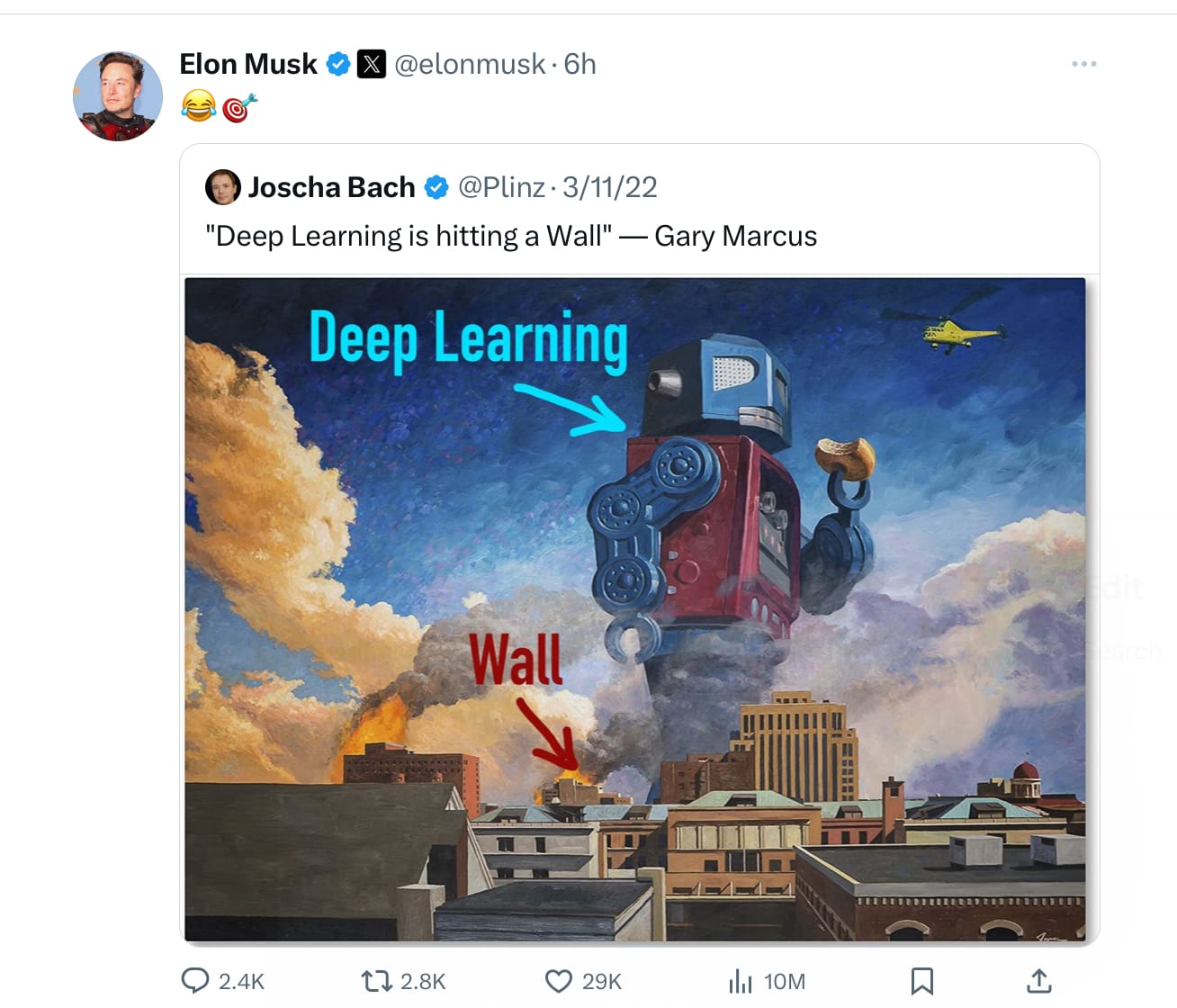
Act II: “In the second stage it is opposed”
Opposition has continued throughout. As recently as earlier this week Dario Amodei, CEO of Anthropic, said in an interview “nothing I've seen... leads me to expect that things will slow down.”
Act III: “In the third stage it is regarded as self evident”
In recent weeks, the third stage has finally arrived. For example, Microsoft CEO Satya Nadella, yesterday, November 2024, said this:
So now in fact there is a lot of debate. In fact just in the last multiple weeks there is a lot of debate or have we hit the wall with scaling laws. Is it gonna continue? Again, the thing to remember at the end of the day these are not physical laws. There are just empirical observations that hold true just like Moore’s law did for a long period of time and so therefore it’s actually good to have some skepticism some debate because that I think will motivate more innovation on whether its model architectures or whether its data regimes or even system architecture.”
[Boldface added to show astonishing note-for-note similarity to my original 2022 formulation, recapping the title (“hit a wall”), the questions about the durability of scaling, the distinction between natural laws and empirical generalizations, the example of Moore’s law, and the need to innovate and consider new architectures.]
Many other Tech CEOs and others, including Marc Andreeseen (A16Z), Alexandr Wang (ScaleAI), have also used the phrase “hitting a wall” and the idea of diminishing returns in the last couple weeks. Naturally, not one has cited me, nor did any of them stand by when I first sounded the alarm.
Epilogue
The sociology here is extraordinary. The field has often treated me as a pariah. The media sometimes treated me as a crank. Practically an entire field, including researchers and executives, tried to shout me down, long before the data were in.
The disparagement, dismissal, and revisionism here are all textbook Schopenhauer.
§
Part of what Schopenhauer was calling attention to was the resistance people often have to new ideas (here, that scaling might not be an enduring law of the universe, and that new approaches might be necessary, to supplement LLMs).
What’s at stake? Science gets delayed.
Here the delay has been in considering alternatives to LLMs. Hundreds of billions of dollars were invested on the assumption that I was wrong, largely to the exclusion of investment in other approaches. Almost a half decade lost, when we could have been seriously investing in other approaches and might have made genuine progress towards robust, trustworthy artificial intelligence.
The question now is, what we will do next?
Gary Marcus has been warning of the limits of pure deep learning since an essay he wrote for the New Yorker in 2012. He still thinks that symbol-manipulation, as discussed in his 2001 book The Algebraic Mind and again in the second half of “Deep learning is hitting a wall” will be part of the solution.
The scaling hypothesis is wrong. It depends on magic. https://www.linkedin.com/pulse/state-thought-genai-herbert-roitblat-kxvmc
The measure of scaling is wrong. Data scaled as compute scaled and it is probably the amount of data that affected the model. https://arxiv.org/abs/2404.04125
The predicted shape of the scaling function is wrong. If it requires exponentially more data for linear improvements, then it must slow down over time.
The measure of intelligence is wrong. Intelligence cannot be measured by existing benchmarks when the model has the opportunity and the means to memorize the answers (or very similar answers).
The models are wrong. LLMs model language, not cognition.
So, what's next? That is what my book is about. Here is an excerpt: https://thereader.mitpress.mit.edu/ai-insight-problems-quirks-human-intelligence/ In the book I lay out a roadmap for the future of artificial intelligence. As Yogi said: "If you don't know where you're going, you might end up someplace else.
The surprise is not that CEOs hype their products. Instead, it's that ignorance of how LLMs (and artificial neural networks generally) actually work that allows the hype to be believed. If they were making cars, say, and claimed that future models were going to go 1000 mph within 5 years, they would be immediately asked what technology they would use and be ridiculed if they didn't have a good answer.