Sora’s Surreal Physics
Some thoughts on what it all means for AGI

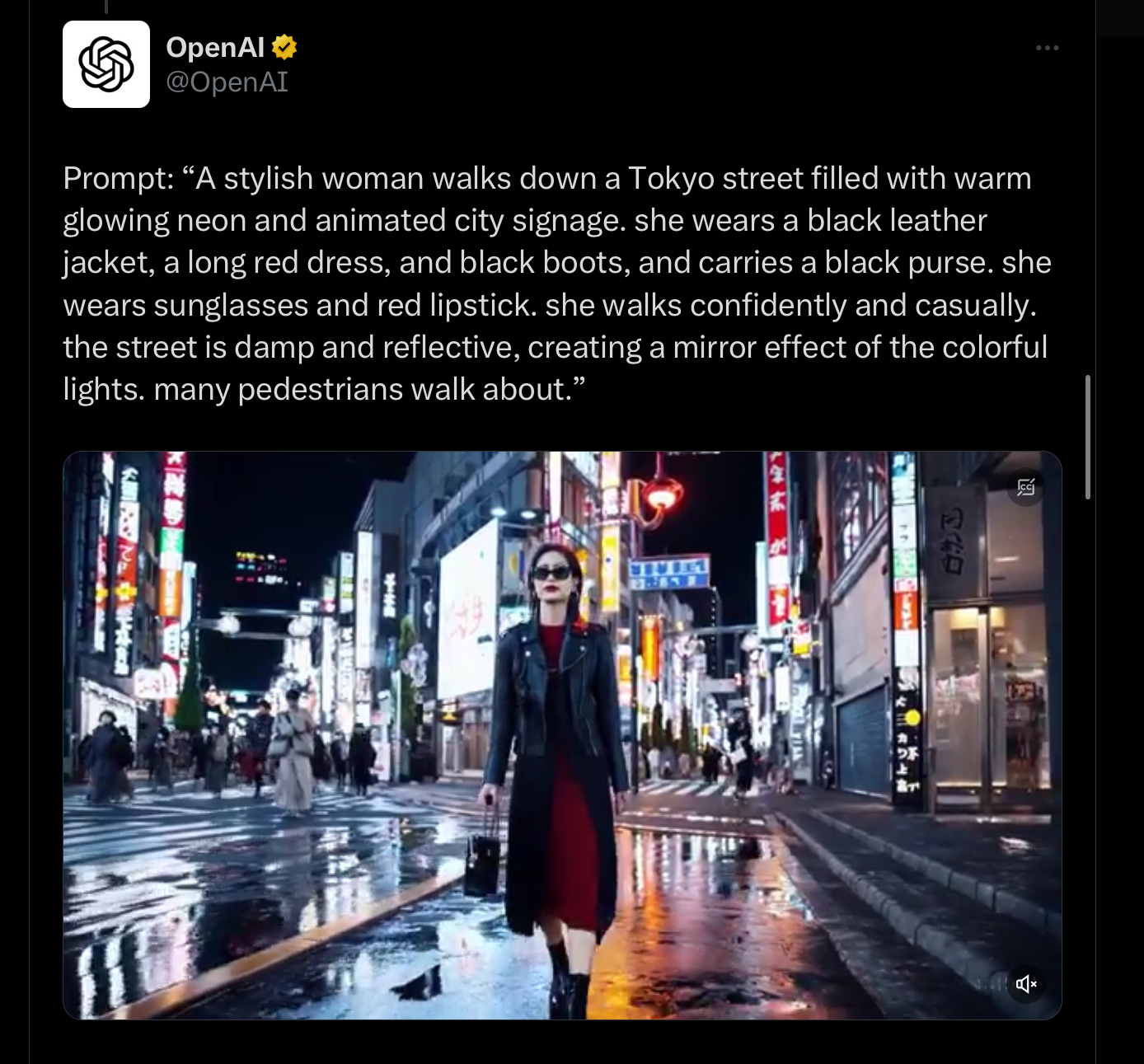
All the tech world is abuzz with OpenAI’s just-released latest text-video synthesizer, and rightly so: it is both amazing and terrifying, in many ways the apotheosis of the AI world to which they and others have been building. Few if any people outside the company have tried it yet (always a warning sign), so we are left only with the cherry-picked videos OpenAI has cared to show. But even from the small number of videos out, I think we can conclude a number of things.
The quality of the video produced is spectacular. Many are cinematic; all are high-resolution, most look as if (with an important asterisk I will get to) they could be real (unless perhaps you watch in slow-motion).. Cameras pan and zoom, nothing initially appears to be synthetic. All eight minutes of known footage are here; certainly worth watching at least a minute or two.
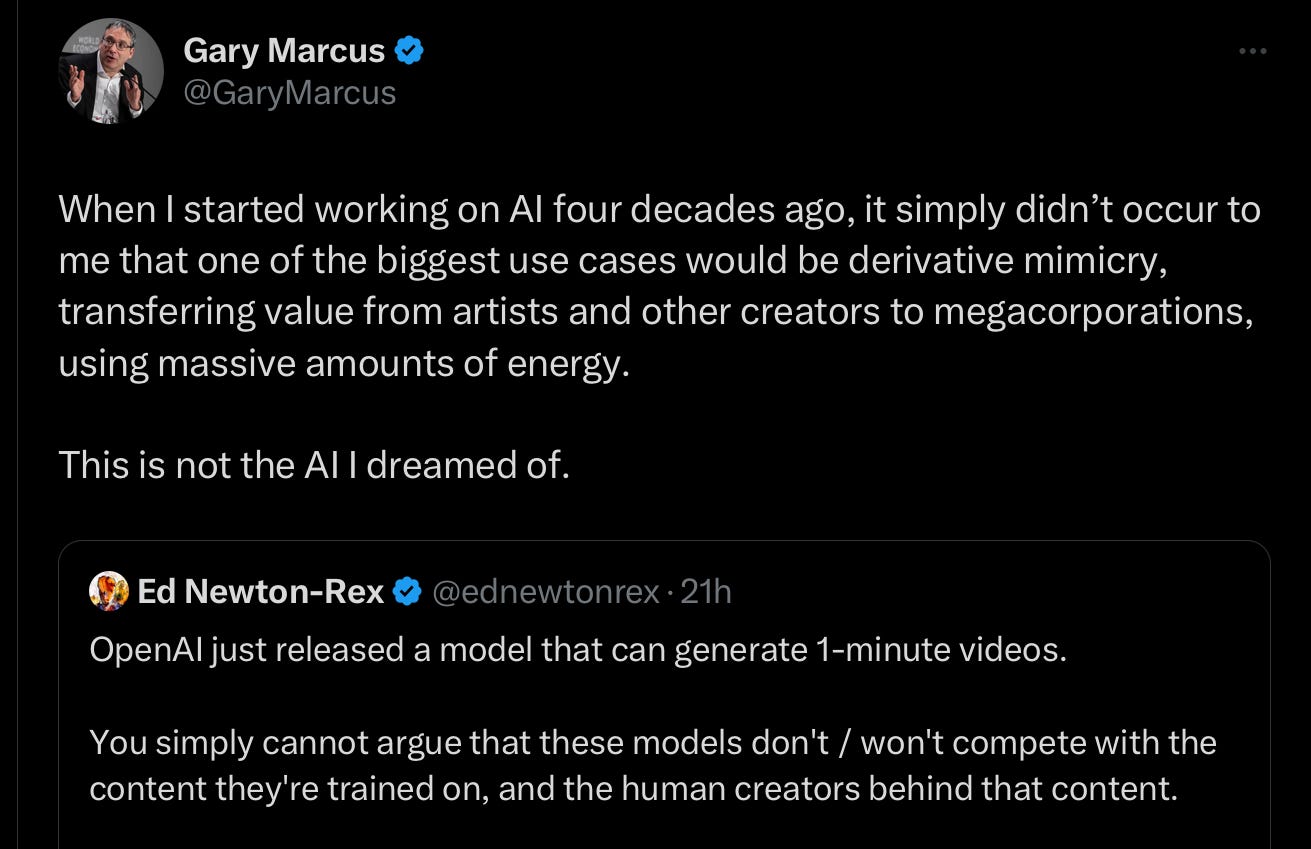
The company (despite its name) has been characteristically close-lipped about what they have trained the models on. Many people have speculated that there’s probably a lot of stuff in there that is generated from game engines like Unreal. I would not at all be surprised if there also had been lots of training on YouTube visited, and various copyrighted materials. Artists are presumably getting really screwed here. I wrote a few words about this yesterday on X, amplifying fellow AI activist Ed Newton-Rex. He, like me, has worked extensively on AI, and increasingly become worried about how AI is being used in the world:
The uses for the merchants of disinformation and propaganda are legion. Look out 2024 elections.
All that’s probably obvious, Here’s something less obvious: OpenAI wants us to believe that this is a “path towards building general purpose simulations of the physical world”. As it turns out, that’s either hype or confused, as I will explain below.

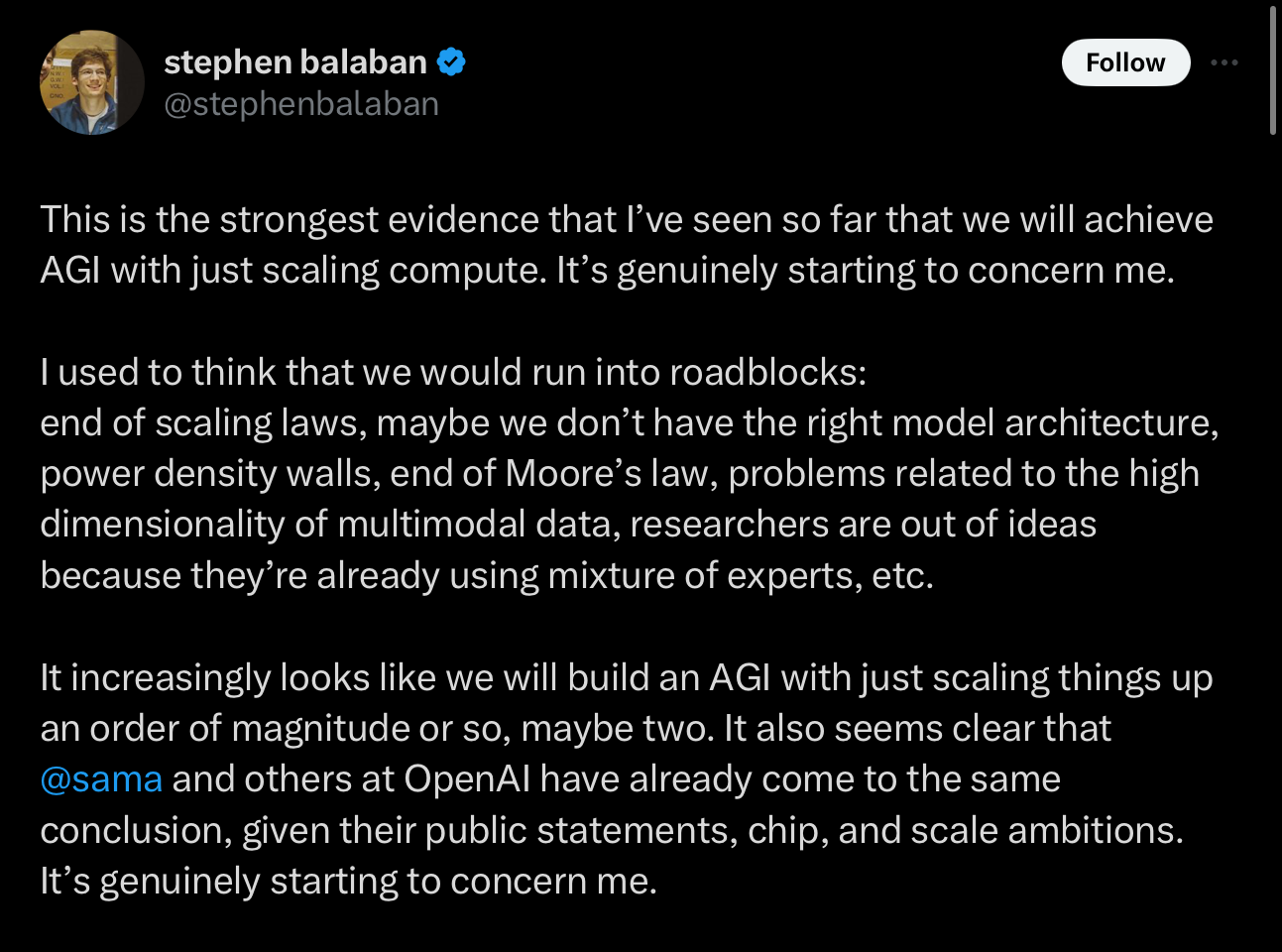
Others seem to see these new results as tantamount to AGI, and vindication for scaling laws, according to with AGI would emerge simply from having enough compute and big enough data sets:

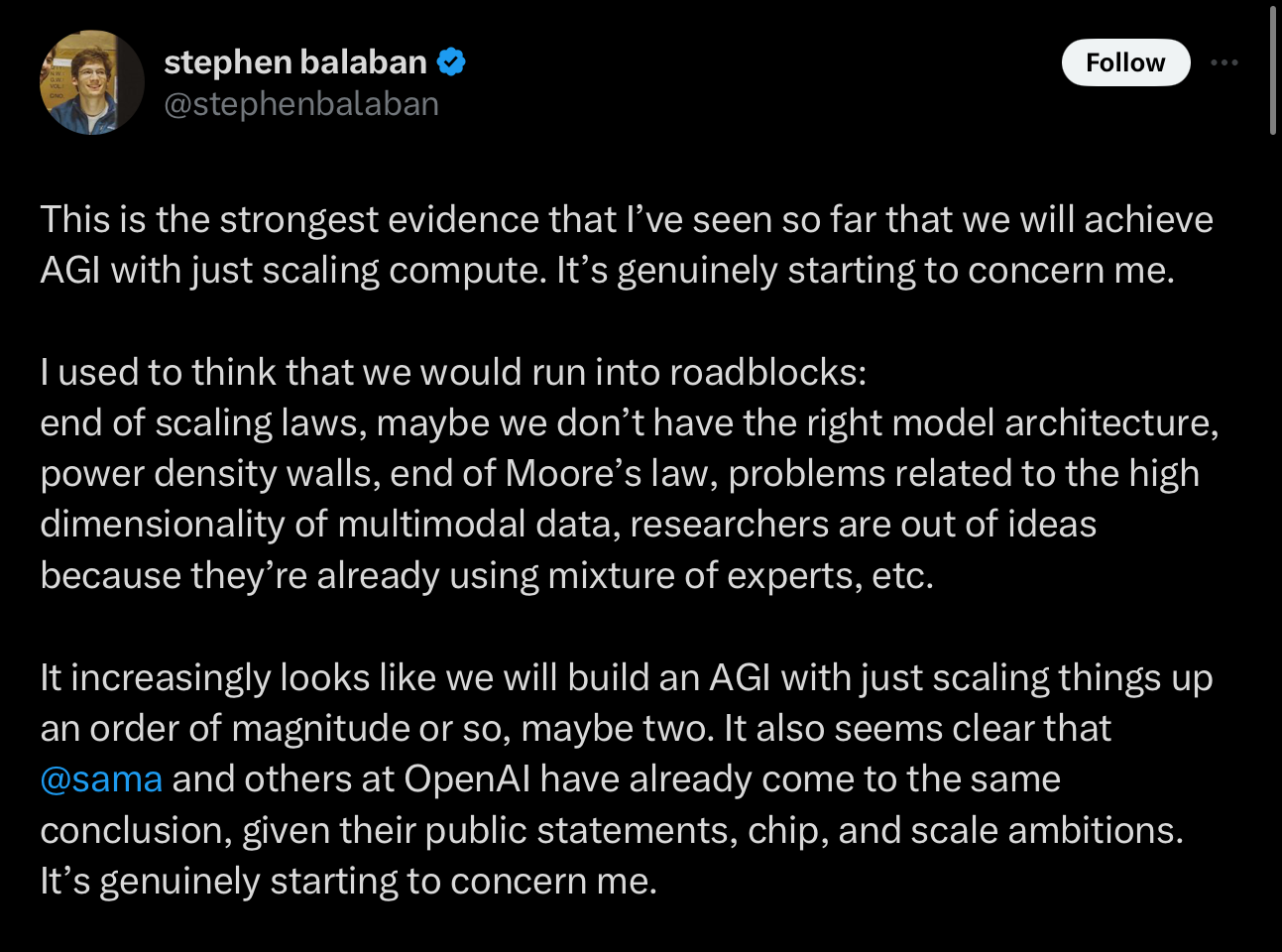
In my view, these claims — about AGI and world models — are hyperbolic, and unlikely to be true. To see why, we need to take a closer look.
§
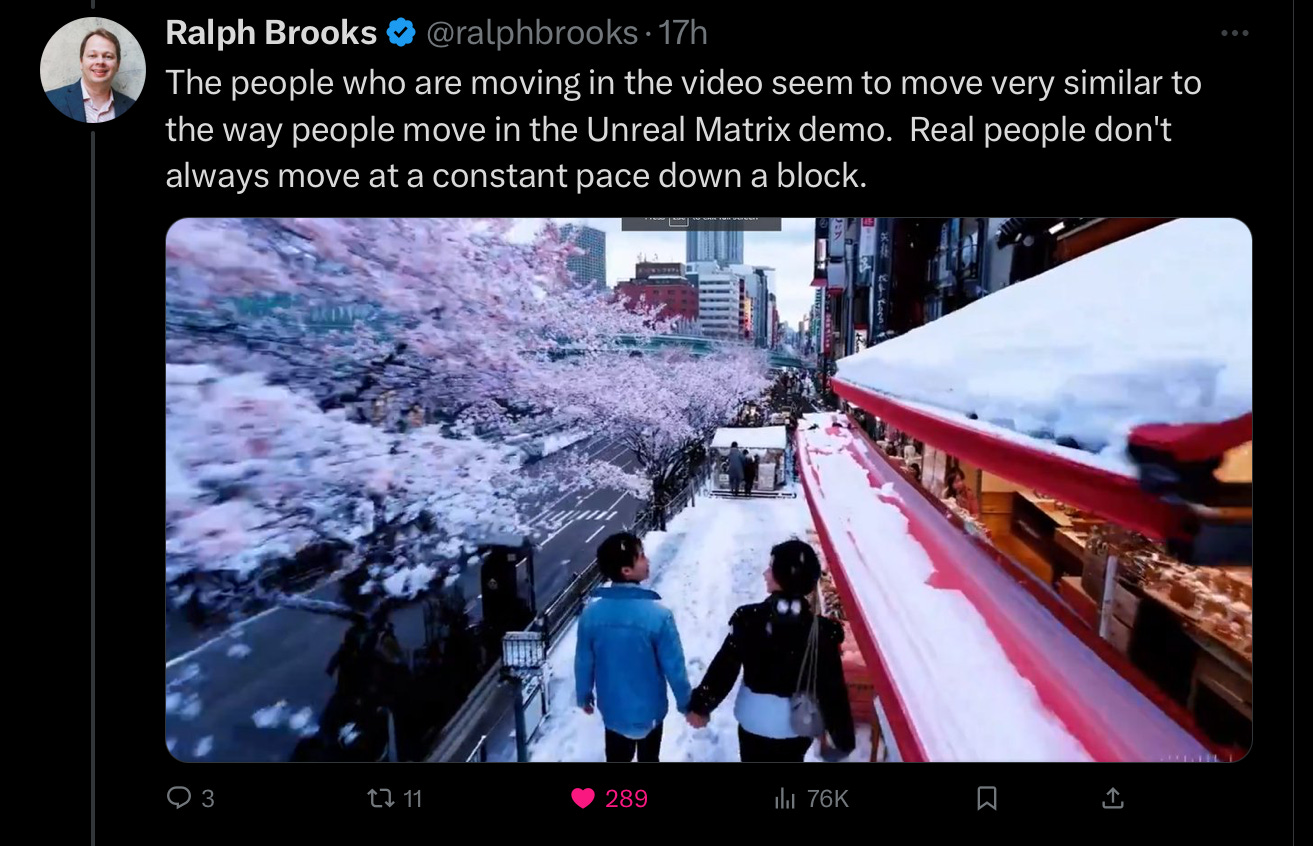
When you actually watch the (small number of available) videos carefully, lots of weirdnesses emerge; things that couldn’t (or probably couldn’t) happen in their real world. Some are mild; others reveal something deeply amiss.
Here’s a mild case. Could a dog really make these leaps? I am not convinced that is either behaviorally or physically plausible (would the dalmation really make it around that wooden shutter?). It might pass muster in a movie; I doubt it could happen in reality.

Physical motion is also not quite right, almost zombie-like, as one friend put it:
Causality is not correct here, if you watch the video, because all of the flying is backwards.

And if you look carefully, there is a boot where the wing should meet the body, which makes no biomechnical or biological sense. (This might seem a bit nitpicky, but remember, there are only a handful of videos so far available, and internet sleuths have already found a lot of glitches like these.)
Lots of strange gravity if you watch closely, too, like this mysteriously levitating chair (that also shifts shape in bizarre ways):

Full video for that one can be seen here.
It’s worth watching repeatedly and in slow motion, because so much weird happens there.
What really caught my attention though in that video is what happens when the guy in the tan shirt walks behind the guy in the blue shirt and the camera pans around. The tan shirt guy simply disappears! So much for spatiotemporal continuity and object permanence. Per the work of Elizabeth Spelke and Renee Baillargeon, children may be born with object permanence, and certainly have some control it by the age of 4 or 5 months; Sora is never really getting it, even with mountains and mountains of data.
That gross violation of spatiotemporal continuity/failure of object permanence is not a one-off, either; it’s something general. In shows up again in this video of wolf-pups, which wink in an and out of existence:

As Jurgen Gravesteinpointed out to me, it’s not just animals that can magically appear and disappear. For example, in the construction video (about one minute into compilation above; I can’t see a separate link to it), vehicle drives directly over some pipes that initially appear to take up virtually no vertical space. A few seconds later, the pipes are clearly stacked several feet high in the air; no way could the vehicle drive straight over those.
We will, I am certain, see more systemic glitches as more people have access.
And importantly, I predict that many will be hard to remedy. Why? Because the glitches don’t stem from the data, they stem from a flaw in how the system reconstructs reality. One of the most fascinating things Sora’s weird physics glitches is most of these are NOT things that appears in the data. Rather, these glitches are in some ways akin to LLM “hallucinations”, artifacts from (roughly speaking) decompression from lossy compression. They don’t derive from the world.
More data won’t solve that problem. And like other generative AI systems, there is no way to encode (and guarantee) constraints like “be truthful” or “obey the laws of physics”or “don’t just invent (or eliminate) objects”.
Indeed the real lesson here is that Generative AI remains a recalcitrant beast, no matter how much data you throw at it.
§
Space, time, and causality would be central to any serious world model; my book about AI with Ernest Davis was about little else; those were also central to Kant’s arguments for innateness, and have been central for years to Elizabeth Spelke’s work on “core knowledge” in cognitive development.
Sora is not a solution to AI’s longstanding woes with space, time, and causality. . If a system can’t at all handle with the permanence of objects, I am not sure we should even call it a world model at all. After all, the most central element of a model of the world is stable representations of the enduring entities therein, and the capacity to reason over those entities. Sora can only fake that by predicting images, but all the glitches show the limitation of such fakery.
Sora is fantastic, but it is akin to morphing and splicing, rather than a path to the physical reasoning we would need for AGI. It is a model of how images change over time, not a model of what entities do in the world.
As a technology for video artists that’s fine, if they choose to use it; the occasional surrealism may even be an advantage for some purposes (like music videos).
As a solution to artificial general intelligence, though, I see it as a distraction.
And god save us from the deluge of deepfakery that is to come.
Gary Marcus has been wishing for a very long time that AI would confront the basics of space, time, and causality. He continues to dream.
I think this is what Andrej Karpathy meant when he said: “I always struggle a bit with I’m asked about the ‘hallucination problem’ in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.”
(https://twitter.com/karpathy/status/1733299213503787018?s=61&t=20jnuQQ5opsvX5aRlZ2UBg)
"It increasingly looks like we will build an AGI with just scaling things up an order of magnitude or so, maybe two." - such absurd statements just reveal a lack of understanding of even the basic problems in AI. Any cs graduate would/should know that attacking an exponential complexity problem (which is what the real world is) with a brute force approach (just scaling things up) is doomed. But because there are no good ideas currently how to really solve intelligence, people behave like a drowning man clutching onto a straw.