The desperate race to save Generative AI
Copyright infringement issues could sink their business. Here’s their game plan, and why you should’t bite.

What do you when your potentially zillion dollar business suddenly runs into a massive obstacle that turns out to be bigger than expected?
First thing you do is stonewall. If something really big drops, “no comment” is a time-honored classic; ducking reporters altogether is even better. When a reporter at Business Insider asked OpenAI and Midjourney for comment on the Marcus-Southen results showing the potential for inadvertent plagiarism in generative AI, even with simple prompts that were not asking for infringing content, OpenAI and Midjourney went with #2:
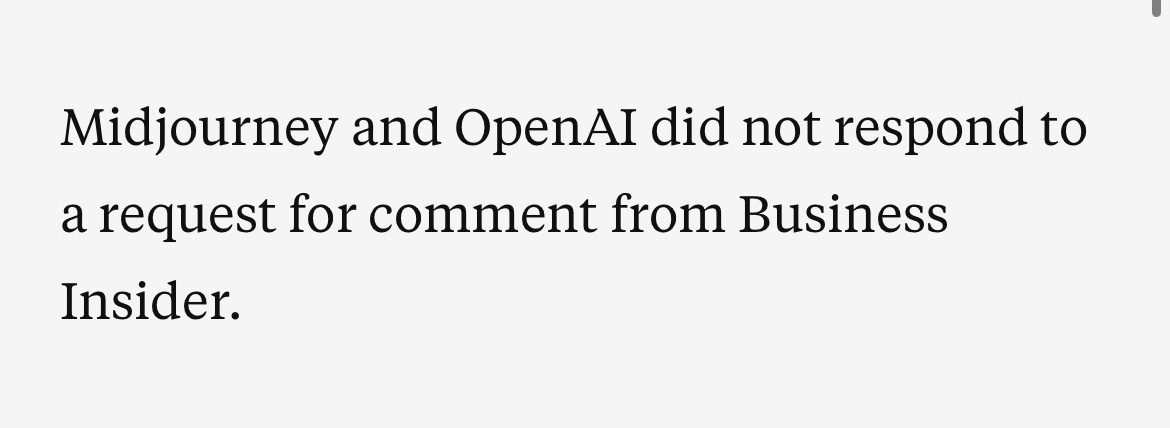
§
Stonewalling is rarely enough long-term. You also want to lobby, both the public and the government. Here’s OpenAI, making their case to the British government, per a scoop today in The Daily Telegraph (sent to me by Cardiff prof Leighton Andrews).
It’s worth reading carefully, to see what lies ahead (and lies are ahead):
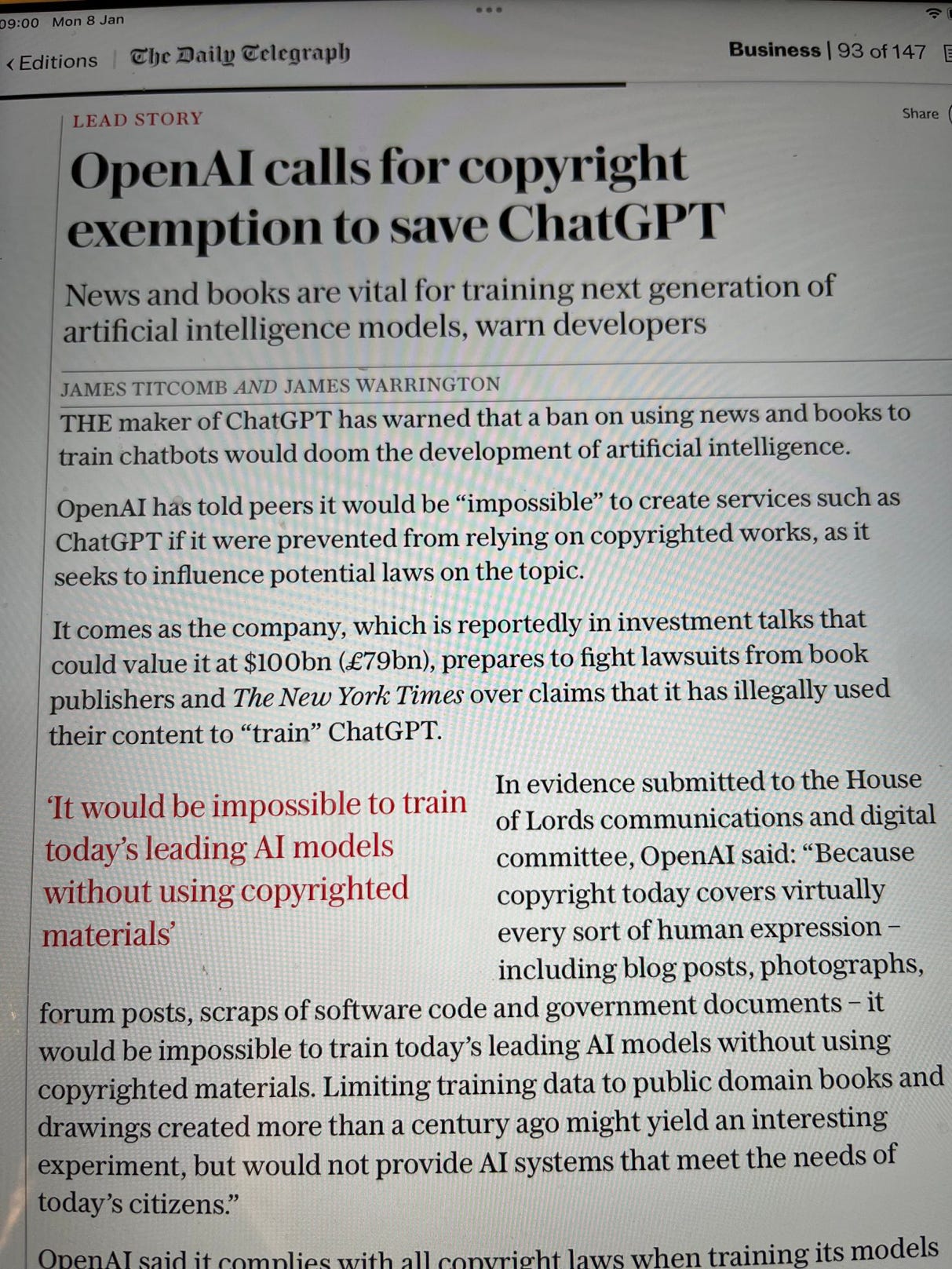
Frankly this is self-serving nonsense: My snarky reply on X, which instantly went viral, was this
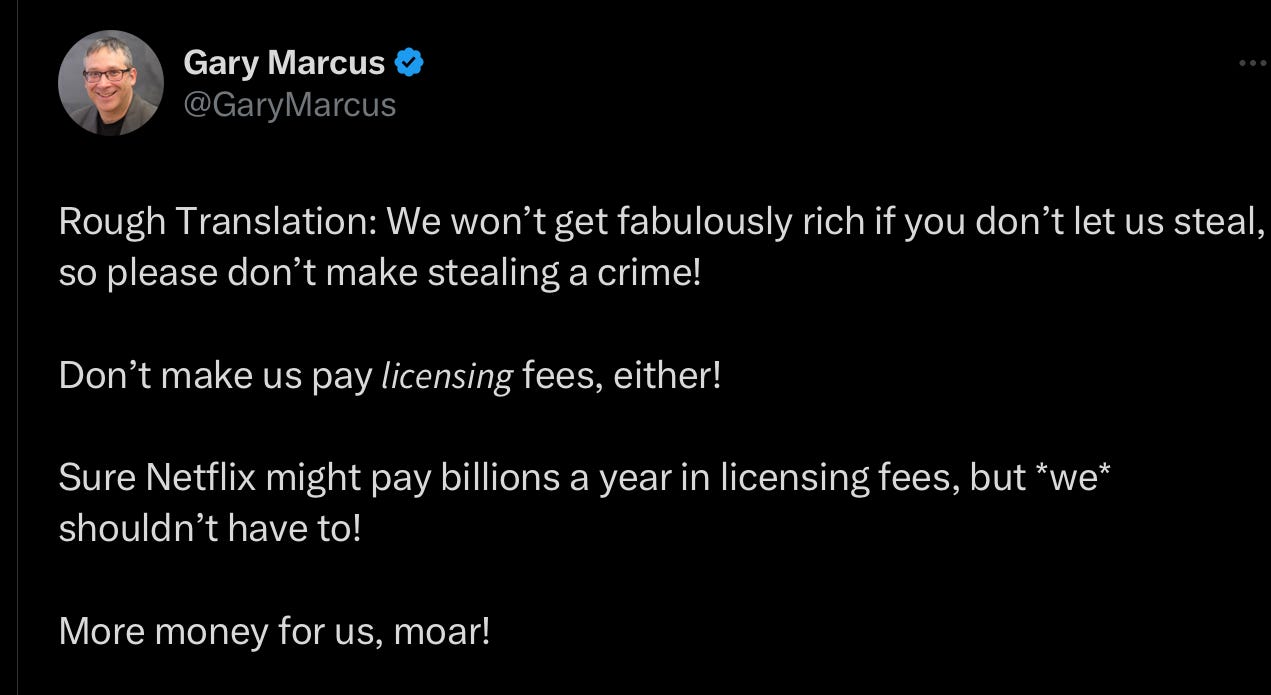
The artist Jon Lam’s quote tweet of the above is even more direct, and went even more viral. In the interest of protecting delicate ears, I will quote only the less off-color opening bit here.

§
OpenAI’s lobbying campaign, simply put, is based on a false dichotomy (give everything to us free or we will die)—and also a threat: either we get to use all the existing IP we want for free, or you won’t get to generative AI anymore. But the argument is hugely flawed. To begin with, the threat is empty: open source LLMs are already out in the wild, and a large number of people know how to build them. LLMs may eventually be replaced by better technologies, but for now, they aren’t going anywhere, even if some of the commercial purveyors go out of business.
More importantly, and here’s another shifty rhetorical move, nobody is actually suggesting that OpenAI only use public domain works. The real suggestion, which OpenAI wants to avoid, is that they pay licensing fees for the commercial works they want to use. Streamers, for example, license everything they stream; there is literally no conceptual reason why OpenAI could not do the same. They just don’t want to. (Streamers like Netflix and Spotify probably don’t enjoy writing fat checks, either.)
As Craig Cowling put it on X, parodying OpenAI’s argument, “I run a sandwich shop. There's no way I could make a living if I had to pay for all my ingredients. The cost of cheese alone would put me out of business.” The argument from “my profits will be smaller if I don’t steal” just doesn’t fly. Netflix and Spotify don’t make it.
And you know what, OpenAI knows this argument is bullshit; they know that licensing is a possibility, because they have been running around working on licensing deals. Leaving that option out in their bogus dichotomous thumbnail of the future is completely disingenuous.
The real issue is of course money. In November they offered to indemnify their customers, against copyright claims; in the intervening months, they must have done the math. Covering all those claims with the accidental infringing machine they have created would be a nightmare. The only chance they have of becoming the zillionaires they aspire to be is to rewrite the rules.

§
Meanwhile there is a critical technical point, too.
It is a particular flaw of current AI — but not a logical necessity for any imaginable AI — that it cannot learn except by downloading internet-sized gobs of content. Ask anyone who graduated from the Annapolis Maryland St John’s University; it’s possible to learn an awful lot just from the classics.
It’s likewise a flaw that that current AI cannot learn without a tendency to inadvertently regurgitate big bits of text and images that look uncannily like their sources, but not a logical necessity. Indeed, as Southen and I pointed out yesterday in the IEEE Spectrum, the tendency towards potential infringement, in current AI looks like maybe it gets worse in bigger models. That’s a flaw in the software, not society’s responsibility.
If the current batch of AI companies cannot create AI that performs reasonably well based on public domain sources and whatever they are prepared to pay to license, they should go back to the drawing board—and figure out how to build software that doesn’t have a plagiarism problem—rather than fleecing artists, writers, and other content providers.
As I just noted on X:
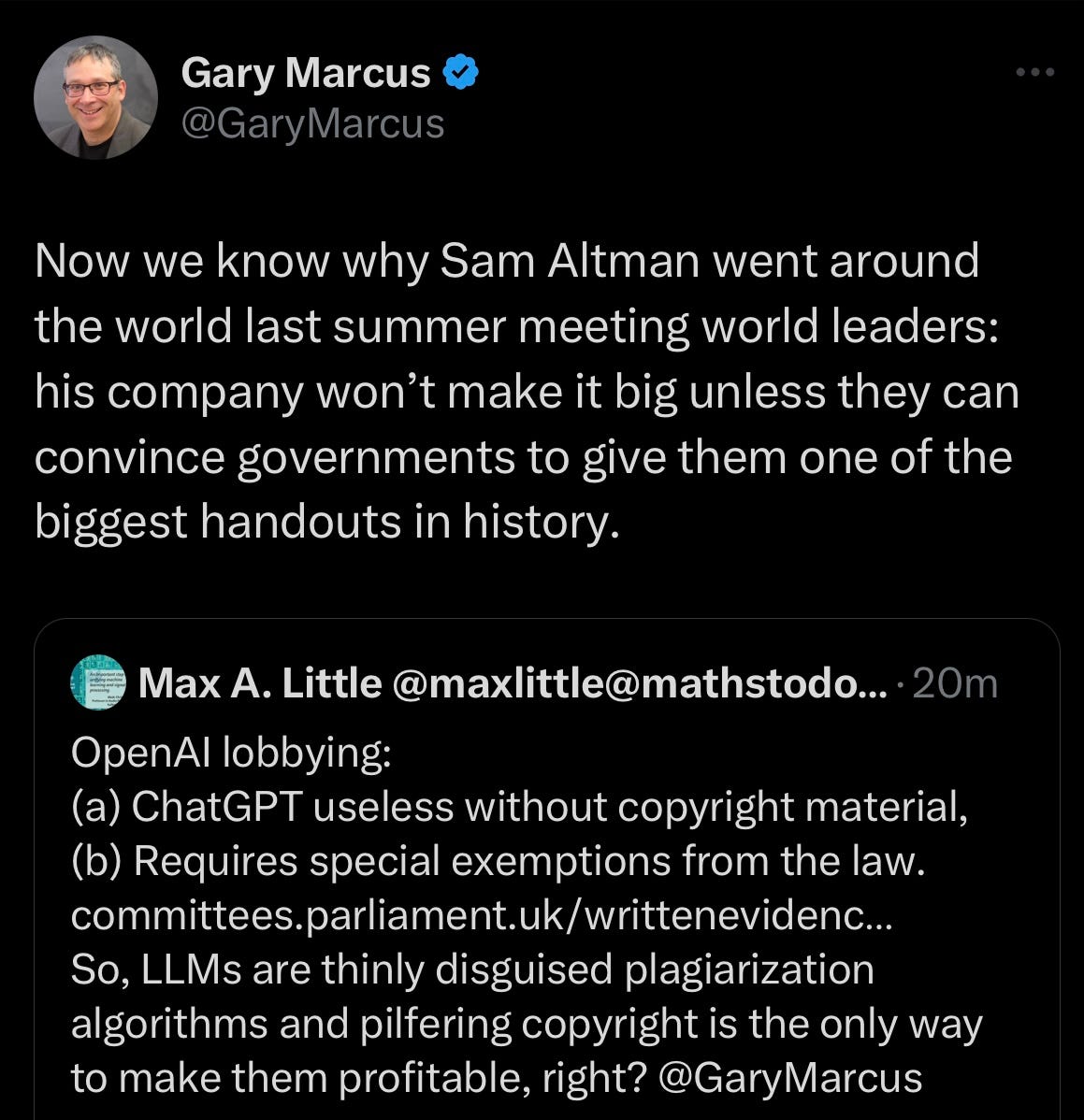
§
OpenAI wasn’t the only one to try to counter the Times lawsuit with lobbying. Prominent machine learning expert Andrew Ng, who is involved in many GenAI companies (in part through his Landing.AI) and presumably has a large financial interest in the outcome, lobbied too, in his case to the public.
Yesterday Ng wrote a long post on his blog, on X, and on LinkedIn, implying that the NYT was too aggressive and would perhaps lose.
Here’s a screenshot of most of the long argument (minus a link that didn’t fit in). You can read it detail or skim if you prefer. The key ideas are two.
First he would like to see training of large models construed as fair use, second, he thinks maybe ChatGPT isn’t as bad as the Times made it appear, pointing to a specific AI technique called RAG (see Ng’s nice short explanation below) as a possible culprit that could be worked around:
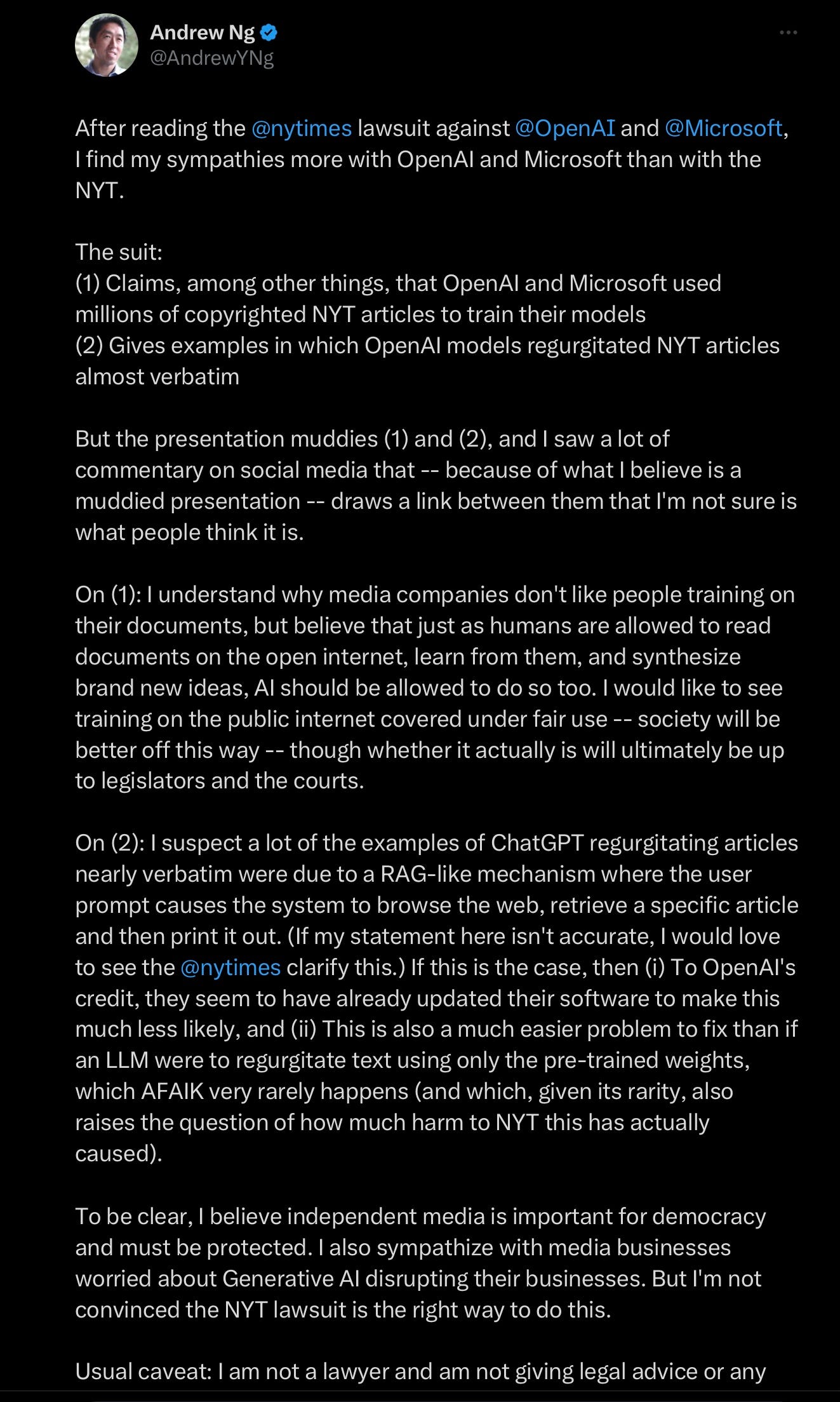
On the first point, good luck. Here’s what Southen and I wrote about fair use yesterday at the IEEE Spectrum:
Of course, not every work that uses copyrighted material is illegal. In the United States, for example, a four-part doctrine of fair use allows potentially infringing works to be used in some instances, such as if the usage is brief and for the purposes of criticism, commentary, scientific evaluation, or parody. Companies like Midjourney might wish to lean on this defense.
Fundamentally, however, Midjourney is a service that sells subscriptions, at large scale. An individual user might make a case with a particular instance of potential infringement that their specific use of, for example, a character from Dune was for satire or criticism, or their own noncommercial purposes. (Much of what is referred to as “fan fiction” is actually considered copyright infringement, but it’s generally tolerated where noncommercial.) Whether Midjourney can make this argument on a mass scale is another question altogether.
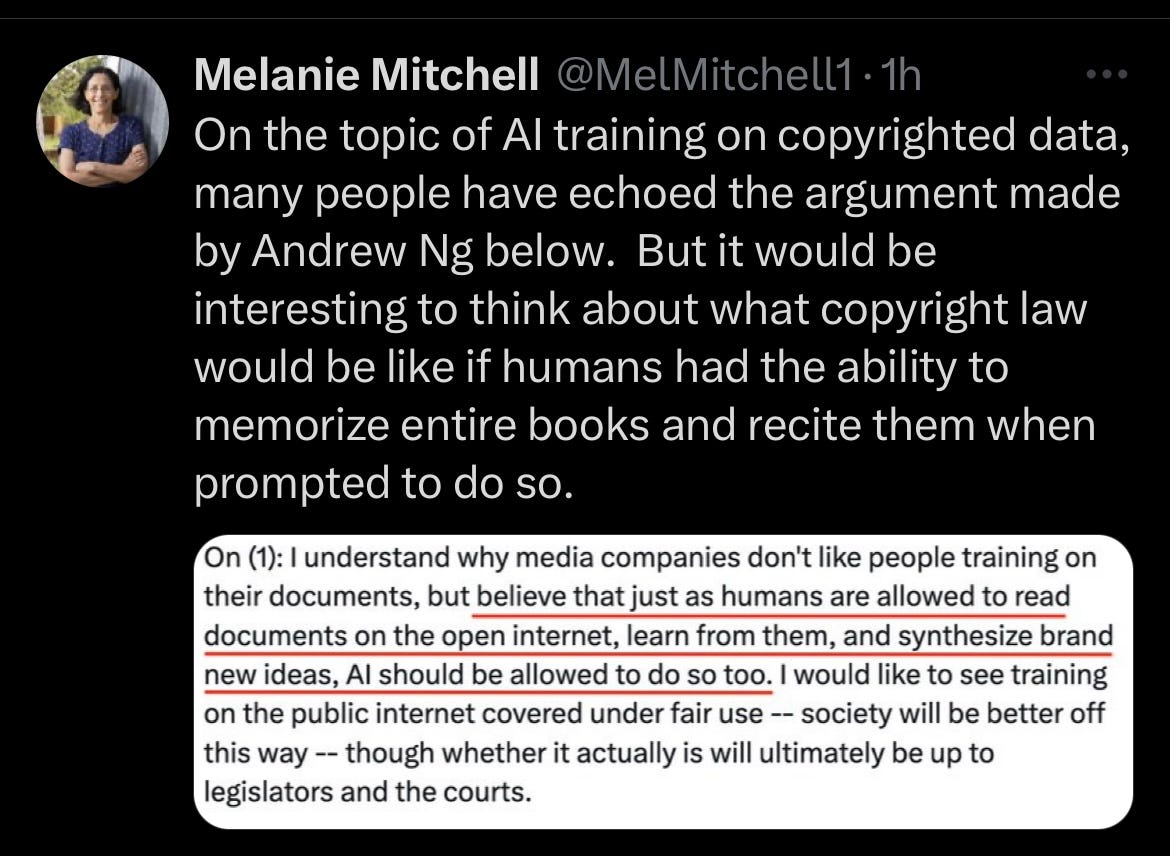
Melanie Mitchell also raised an interesting thought experiment, with respect to Ng’s claims about greater good:
§
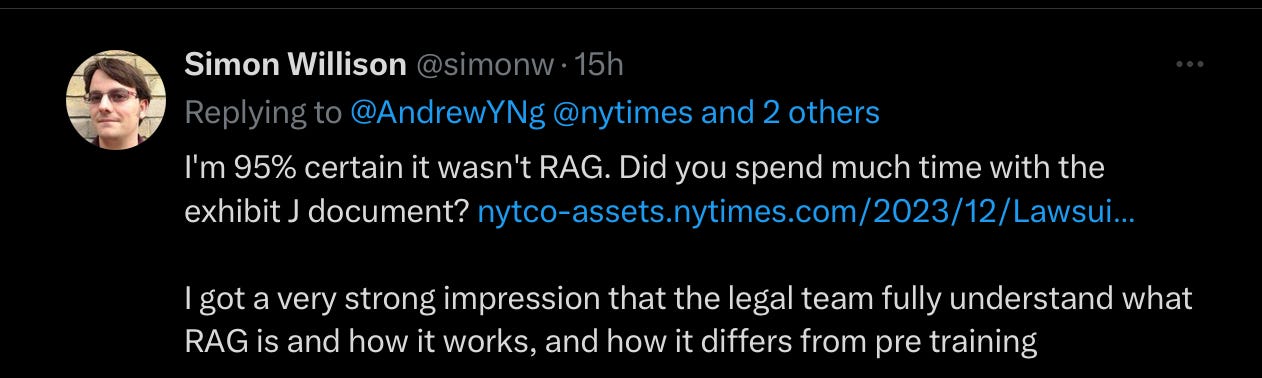
On Ng’s technical point, reading Marcus and Southen at IEEE would be a good idea there, too. It’s not clear that RAG (Retrieval Augmented Generation) actually played a key role in the NYT stuff in the first place:
But it’s even clearer that the image generation programs have not been using it; at least so far, that just hasn’t been a thing, and it would be much much harder to do with images. And what Southen and I showed is that generative image programs are prone to exactly the same kind of regurgitation that is at issue.
In short, the pointer to RAG is basically a red herring. GenAI has a plagiarism problem, and it’s not just a function of RAG, as Ng seemed to be hinting.
§
The software engineer Frank Rundatz has been writing a lot of good stuff about these issues lately. I like this post of his on X a lot (we quote another in the Spectrum), comparing Google (which sends people to original sources) and OpenAI (which does not, or at least not to nearly the same degree); it also speaks to Ng’s claims about what would or would not make society better off:

Rundatz’s argument could be made vastly more general; if UK or other lawmakers succumb to their nonsense arguments, and rewrite existing rules for the benefit of GenAI, abandoning principles that go back to the time of the printing press, there will be momentary jubilation for many, and OpenAI will (maybe, if the GPU costs and unreliability problems don’t otherwise kill them, two big ifs) get rich.
But in the end, nobody will create good, fresh, new content anymore, and the internet will start eating its own tail. We will will all suffer in the end, fed a mediocre stew of regurgitate.
Let us hope that doesn’t happen.
P.S. For some more self-serving lobbying, see also this statement from a large VC firm.
Gary Marcus hopes desperately that the UK government won’t fall for this nonsense.
I like and agree with Gary's forecast that without proper compensation/licensing, original content will dwindle and the online world will be all re-consumed vomit. That alone should be a reason to make sure that content creators are incentivized to continue creating original and truthful content. Otherwise, everyone is a loser in this closed system.
"We won't get fabulously rich if you don't let us steal, so please don't make stealing a crime."
Drop the Mic GM. That one line sums up everything! I love the complex simplicity of it.