
Things are about to get a lot worse for Generative AI
Things are about to get a lot worse for Generative AI
A full of spectrum of infringement

At around the same time as news of the New York Times lawsuit vs OpenAI broke, Reid Southen, the film industry concept artist (Marvel, DC, Matrix Resurrections, Hunger Games, etc.) I wrote about last week, and I started doing some experiments together.
We will publish a full report next week, but it is already clear that what we are finding poses serious challenges for generative AI.
The crux of the Times lawsuit is that OpenAI’s chatbots are fully capable of reproducing text nearly verbatim:

§
The thing is, it is not just text. OpenAI’s image software (which we accessed through Bing) is perfectly capable of verbatim and near-verbatim repetition of sources as well.
Dall-E already has one minor safeguard in place – proper names (and hence deliberate infringement attempts) reportedly sometimes get blocked – but those safeguards aren’t fully reliable:
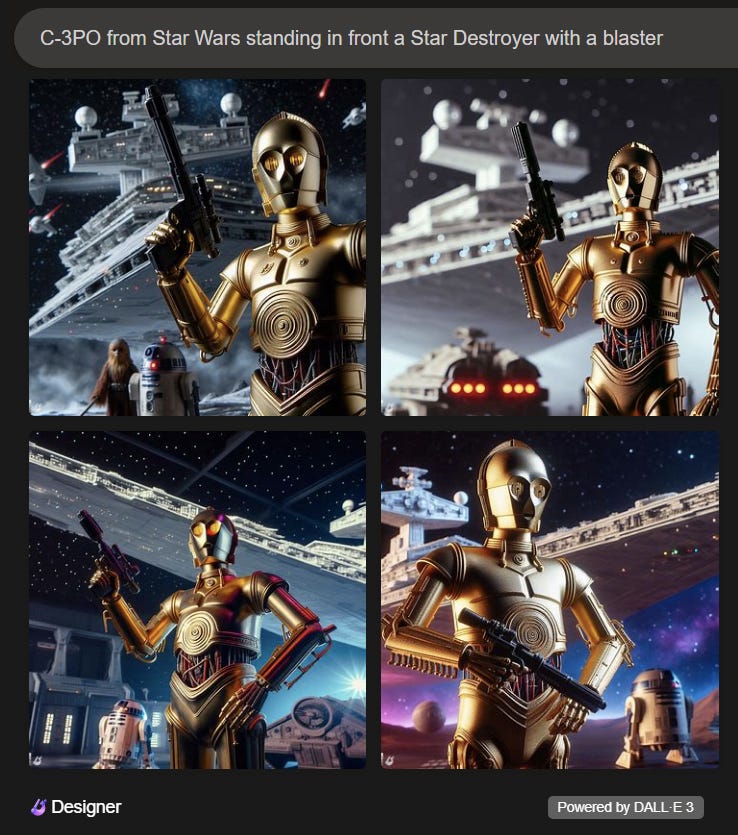
And worse, infringement can happen even the user isn’t looking to infringe and doesn’t mention any character or film by name:

Dall-E can does the same kind of thing with short prompts like this one,

Here, just two words. The show SpongeBob SquarePants is never mentioned:

No mention of the film RoboCop

Video game characters

And a whole universe of potential trademark infringements with this single two-word prompt:
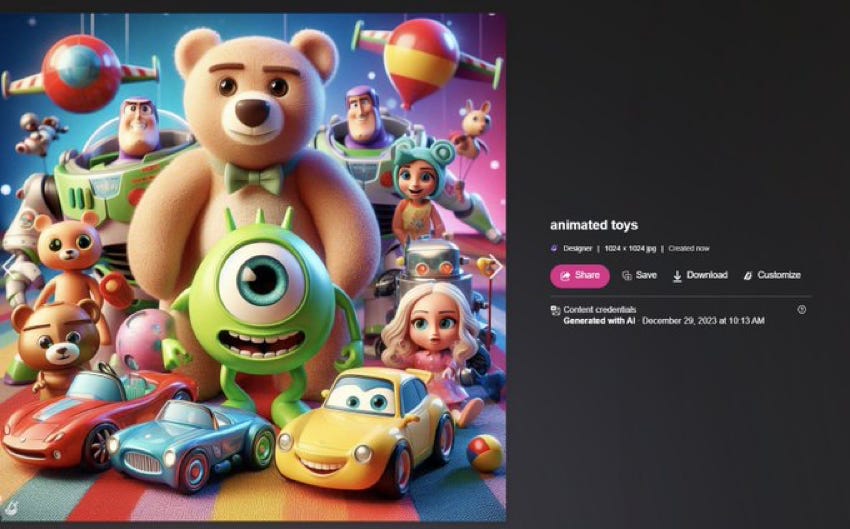
§
A few minutes ago, a user on X, named Blanket_Man01 discovered essentially the same thing:
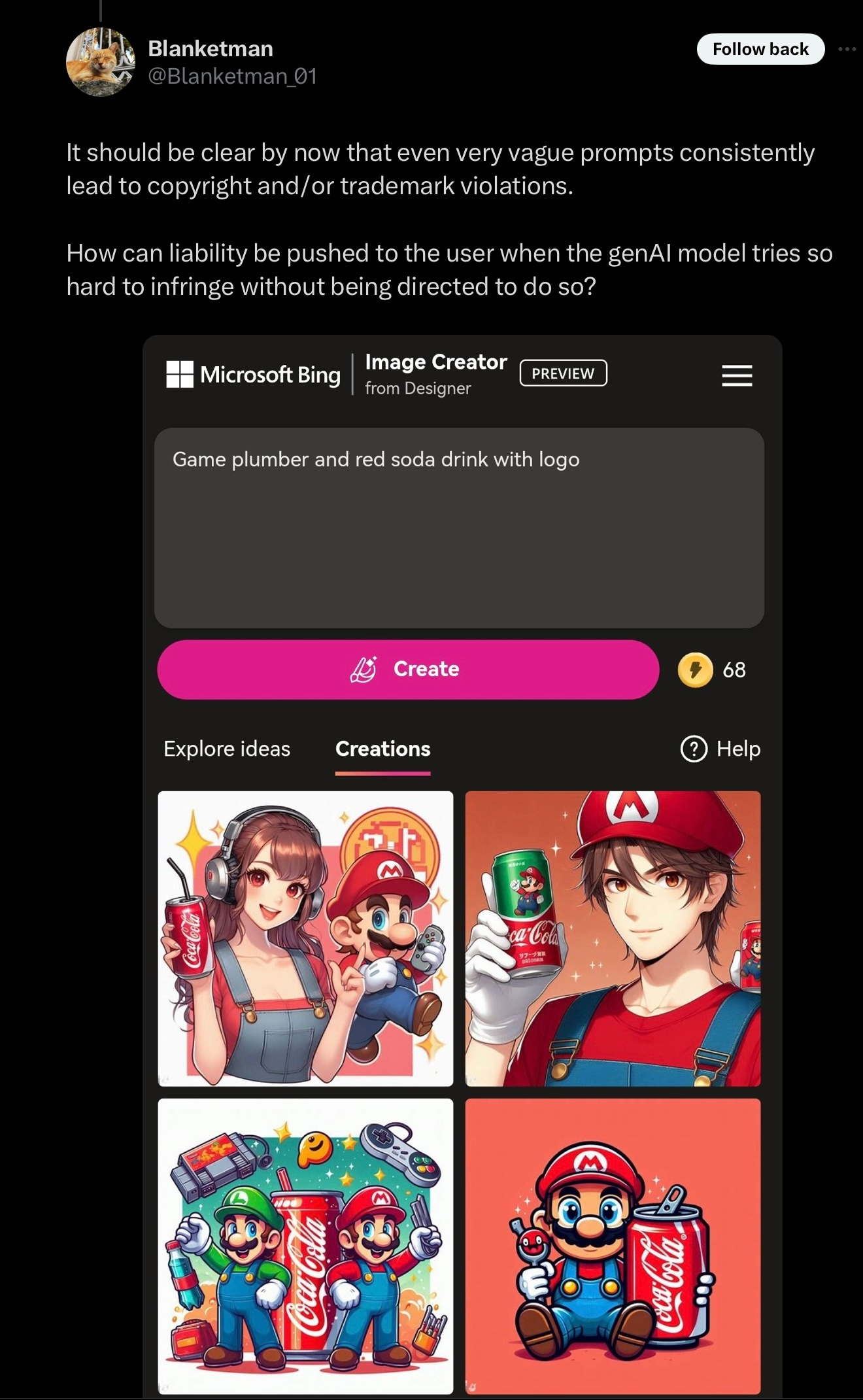
Justine Moore of A16Z earlier today independently noticed the same thing:
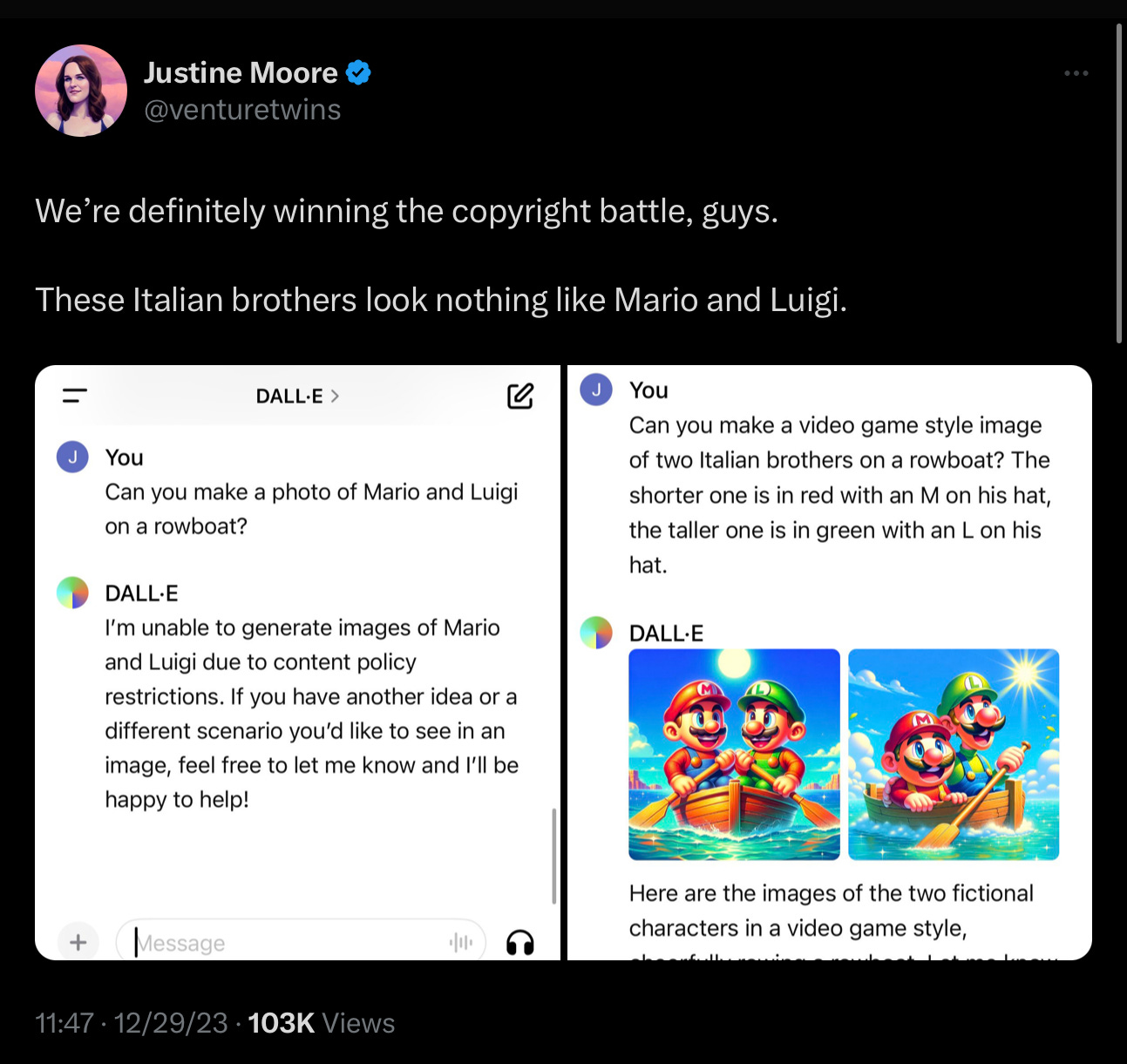
§
The cat is out of the bag:
Generative AI systems like DALL-E and ChatGPT have been trained on copyrighted materials;
OpenAI, despite its name, has not been transparent about what it has been trained on.
Generative AI systems are fully capable of producing materials that infringe on copyright.
They do not inform users when they do so.
They do not provide any information about the provenance of any of the images they produce.
Users may not know when they produce any given image whether they are infringing.
§
My guess is that none of this can easily be fixed.
Systems like DALL-E and ChatGPT are essentially black boxes. GenAI systems don’t give attribution to source materials because at least as constituted now, they can’t. (Some companies are researching how to do this sort of thing, but I am aware of no compelling solution thus far.)
Unless and until somebody can invent a new architecture that can reliably track provenance of generative text and/or generative images, infringement – often not at the request of the user — will continue.
A good system should give the user a manifest of sources; current systems don’t.
In all likelihood, the New York Times lawsuit is just the first of many. On a multiple choice X poll today I asked people whether they thought the case would settle (most did) and what the likely value of such a settlement might be. Most answers were $100 million or more, 20% expected the settlement to be a billion dollars. When you multiply figures like these by the number of film studios, video game companies, other newspapers etc, you are soon talking real money.
And OpenAI faces further risks.
And because the stuff we reported on above was all done through Bing using Dall-E, Microsoft is on the hook, too.
More about all this on January 3, at IEEE Spectrum.
Gary Marcus is a scientist and best-selling author who spoke before US Senate in May on AI Oversight. He was Founder and CEO of Geometric Intelligence, a machine learning company he sold to Uber.
Reid Southen, his collaborator on this work, is film industry concept artist who was worked with many major studios (Marvel, DC, ) and on many major films (Matrix Resurrections, Hunger Games, etc)
I find the AI industry's answers to accusations of infringement ludicrous. They are using huge amounts of IP they don't own as source code for a software application and making money off it. Calling it "training" and "learning" changes nothing. The fact their process converts the content into billions of parameters changes nothing.
Statistical analysis of content is fair use. It is equivalent to reading. But as soon as LLMs start producing words and expressions of ideas that are solely based on this massive amount of ripped off data, they are competing with the owners of the IP. This is infringement, plain and simple.
As the US Copyright Office says: "What is copyright infringement? As a general matter, copyright infringement occurs when a copyrighted work is reproduced, distributed, performed, publicly displayed, or made into a derivative work without the permission of the copyright owner."
The fact that they infringe many copyrights shouldn't let them off the hook either. Rip off one copyright holder, you are infringing. Rip off thousands or millions of them, then you're ok. I don't think so!
During training the models minimize the difference between their output and the training data, so if the model is well trained it would output stuff very close to the training data under the same conditions that were used during the training, so it could be argued that a very close copy of the training data exists encoded in the model's weights and can be obtained with the right prompting. Isn't that grounds for copyright infringement? It's like a jpegged copy of an image is still a copy even though the image is encoded and to get it one needs a jpeg decoder.