AGI versus “broad, shallow intelligence”
The BSI we have now, versus the AGI we want


Nobody serious thinks that we have reached AGI (artificial general intelligence) yet. A few days ago, one of the sharper and more elegant thinkers in AI, François Chollet wrote, quite rightly:
Pragmatically, we can say that AGI is reached when it's no longer easy to come up with problems that regular people can solve (with no prior training) and that are infeasible for AI models. Right now it's still easy to come up with such problems, so we don't have AGI.
Shane Legg, one of the co-inventors of the term, and one of the cofounders of DeepMind, responded to Chollet:
I've been saying this within DeepMind for at least 10 years, with the additional clarification that it's about cognitive problems that regular people can do. By this criteria we're not there yet, but I think we might get there in the coming years.
When I shared Shane’s post on X with the a comment (“ None of the people who helped coined the term AGI thinks we are there yet“), another of the people to have helped coined the term, Ben Goertzel, perhaps the researcher who has most directly and publicly advocated for AGI for the longest period of time, chimed in:
Yes clearly we have not achieved Human-Level AGl yet in the sense in which we meant the term when we published the book "Artificial General Intelligence" in 2005, or organized the first AGI Workshop in 2006 or the first AGI Conference in 2008….. the things that put the term on the map in the Al research community...
What was meant there was not merely having a generality of knowledge and capability similar to that of a typical humans (and to be clear o3 isn't there yet, it's way superhuman in some ways and badly subhuman in others), but also having a human-like ability to generalize from experience to very different situations... and no LLM-centered system I've seen comes remotely close to this. …
Anyone who tries to tell you otherwise is either confused or trying to hype something. Every declaration of us already reaching AGI I have seen rests on redefining the term downwards, as I discussed last week,
But Houston, we still have a definitional problem. If what have now is not AGI, what is it?
§
An older distinction, that no longer feels complete, is between narrow AI and general AI. Ernest Davis and I leaned heavily on that in our 2019 book Rebooting AI, written in 2018 just before LLMs become widespread. There, we distinguished between narrow systems, such as AlphaGo, which played Go but did little else, and general AI that ought to be able to do anything reasonable that you throw at it.
When I was pressed to define AGI myself in 2022 I proposed (after consultations with Goertzel and Legg), the folllowing, which I still stand by:
shorthand for any intelligence ... that is flexible and general, with resourcefulness and reliability comparable to (or beyond) human intelligence
LLMs don’t meet that; as the world has discovered, reliability is not their strong suit; as I have often written here, and as Goertzel also emphasizes, LLMs lack the ability to reliably generalize to novel circumstances. Likewise, the inability of LLMs to do basic fact checking and sanity checking speak to their lack of resourcefulness.
GenAI answers are frequently superficial; they invent things (“hallucinations” or what I would prefer to call confabulations”), they fail to sanity check their own work, and they regularly make boneheaded errors in reasoning, mathematics and so on.. One never knows when one will get a correct answer or ludicrous response like this one observed by AI researcher Abhijit Mahabal:
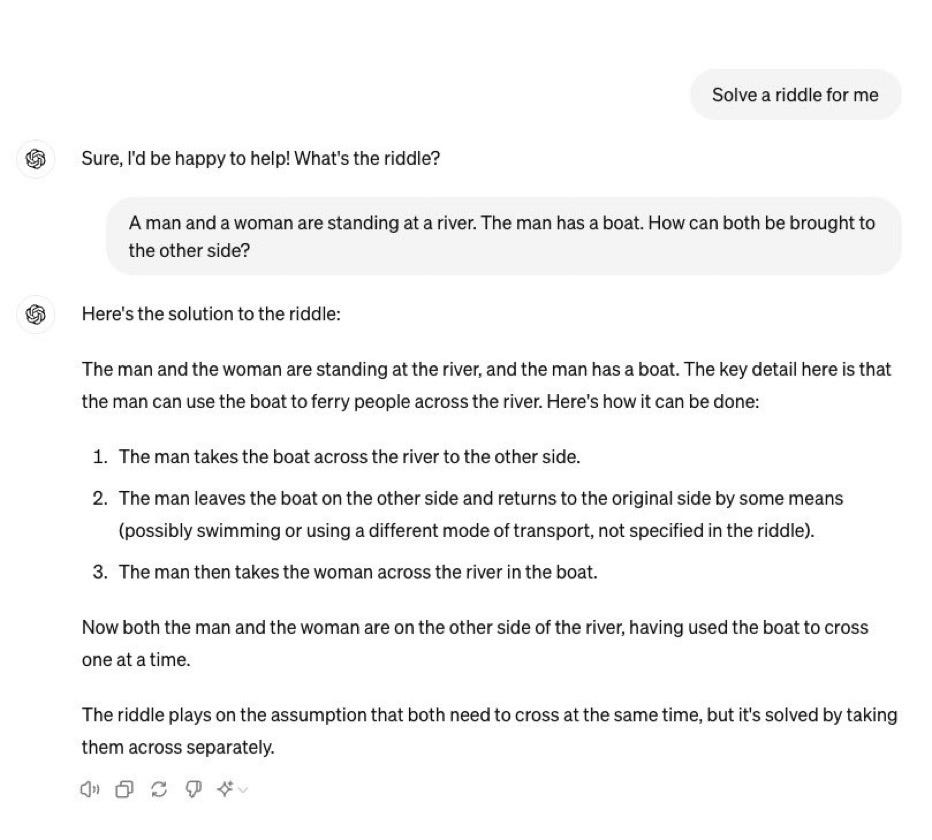
There are by now legions of examples of like these, like another Mahabal just posted. Colin Fraser has posted many variant on X. No system has been shown to be robust across all the variations (though specific ones vary across replications, perhaps in response to publicly shared examples). (Mahabal’s recent example with alternative chess is equally instructive).
If you will pardon the metaphor, AGI should be able to stand on its own two feet. Instead, LLMs are still unpredictable enough that humans should still be in the loop in most case. Something is still missing.
Counting on AI that is shallow and not reliable, it should also be said, could cause huge problems. We can never guarantee that broad but shallow AI will be safe, or that it will be human-compatible (in the words of Stuart Russell), or that it will do what we ask of it.
§
For all these reasons, I propose that we call LLMs broad, shallow intelligence..
LLMs are undeniably wide (if not fully general) in their application, as Gerben Wierda suggested in a recent manuscript, fully capable of taking a shot at a great many kinds of problems. But they remain superficial, in that their responses invariably have the right kind of language for any given problem, but (unlike the hypothetical Star Trek computer) rarely trustworthy. The river crossing example and many others shows that LLMs often use the words without a deep understanding what those words mean. As Mahabal noted in email to me, “[at times LLMs] seem quite capable of regurgitating or replicating someone's deep analysis that they have found on the internet, and thereby sound deep”, but that regurgitation is an illusion. Genuine depth is lacking.
For me, “broad but shallow” well captures the current regime.
Broad, shallow intelligence (BSI) is a mouthful, but it has two fundamental advantages: it is accurate, and clarifies the bar that we should be trying to surmount. We still want, as Davis and I argued, deep understanding. A system answering a river-crossing problem should not answer by superficial analogy to the words in similar problems found in a giant scrape of the internet, but rather by reasoning through concepts about boats, rivers, people, and so on. Then same should hold true for whatever concepts lie behinds the words that LLMs use.
Then, and only then, will we have reliable solutions to the unreliability that has plagued recent AI.
§
When grifters and influencers in 2025 claim that AGI has been solved or is imminent, you should ask: is that really true? Will we able to rely on these forthcoming systems to give sound answers in a wide range of domains? Will they significantly deeper than their predecessors, in principled ways? Or just slightly improved continuations of the same game: jack-of-all-trade approximations of all trades, but masters of none, shallow and lacking in deep understanding?
Moving past broad but shallow AI and into a new and hopefully safer and more reliable regime should be a major research priority for the human species.
Gary Marcus, co-author of Rebooting AI, which warned “we are ceding more and more authority to machines that are unreliable .. and lack any comprehension of human values”, has been writing about natural and artificial intelligence since he was old enough to drink. He is still waiting for AGI.
Excellent. Again.
"Broad, shallow intelligence (BSI) is a mouthful"
Let's simplify the acronym by shortening it. I think that BS covers the issue nicely. At least for the present.
LLMs don't have intelligence. They are still just programs which can answer questions posed in ordinary languages. The answers are not reliable. Because they don't have internal structured models, they cannot tell whether they are truthfull or not. They are not hallucinating. It's a typical case of anthropomorphism. Even young children know when they are making up stories or not.
LLMs don't have capability to reflect on their own operation.
Typical LLM products have case-by-case fixes to deal with known hallucination cases. They are like Amazon's automated shops which are maintained by remote humans.
LLMs are hugely wasteful. They consume huge amount of electicity and water for frivolous queries of questionable value.
We need to recognize that LLMs are just tools to generate draft texts under proper constraints.
A fraction of investments could be directed to proper academic researches of human intelligence and knowledge for greater value. By neglecting proper researches, we are hurting ourselves.