Deconstructing Geoffrey Hinton’s weakest argument
Hinton’s “savage” but misguided attack on Marcus, analyzed


“Don't mess with the Godfather. Geoffrey Hinton savages Gary Marcus”, said one tweet I read this morning. Another was mistakenly convinced that I was “destroyed” by Hinton’s critique.
What Hinton argued is that I was hallucinating in my belief that LLMs remain limited in their understanding of language. You can see the whole clip here, evidently drawn from a talk he gave in Toronto in October, but here’s a transcription of his argument:
These hallucinations as they’re called, or confabulations, they are exactly what people do, we do it all the time. Doing confabulation is: there's someone called Gary Marcus who criticizes neural nets and he says, "Neural nets don't really understand anything, they read on the web." Well that's 'cause he doesn't understand how they work.1 He's just kind of making up how he thinks it works.
They don't pastiche together text that they've read on the web, because they're not storing any text. They're storing these weights.
So actually that's a person doing confabulation. called, or confabulations, they are exactly what people do, we do it all the time
Distilled, Hinton is basically making three arguments::
Because neural networks often perform well, they must understand what they are talking about.
Neural networks don’t store text, so anyone who thinks they are pastisching is hallucinating.
Hallucination errors in LLMs are not a problem, because people hallucinate, too.
None of them flies.
Let’s take them in reverse order. On the point that humans hallucinate too, it is true that humans make errors. But, except in hallucinations associated with disorders like schizophrenia, human errors are very different. Humans rarely make things up wholesale, LLMs do. For example, ChatGPT claimed (falsely yet authoritatively, and without any evidence) that I had a pet chicken named Henrietta:

Wholesale unintentional fabrication is not the same thing as making a flawed argument, or lying, or spinning facts for political gain, and so on. Instead, it’s an error from recombining little bits of text in wrong ways. Turns out for example that an illustrator named Gary Oswalt illustrated a book named Henrietta Gets a Nest, and perhaps the statistical reconstruction process got muddled.

In my entire life I have never met a human that made up something outlandish like that (e.g, that I, Gary Marcus, own a pet chicken named Henrietta), except as a prank or joke.
One of the most important lessons in cognitive psychology is that any given behavioral pattern (or error) can be caused by many different underlying mechanisms. The mechanisms leading to LLM hallucinations just aren’t the same as me forgetting where I put my car keys. Even the errors themselves are qualitatively different. It’s a shame that Hinton doesn’t get that.
§
On the second point, pastisching, neural networks don’t literally store their input texts (or images etc), and I never said that they did. I generally make clear that the notion of pastische is an analogy, not literal truth, even in podcasts:
EZRA KLEIN: You have a nice line in one of your pieces where you say GPT-3, which is the system underneath ChatGPT, is the king of pastiche. What is pastiche, first, and what do you mean by that?
GARY MARCUS: It's a kind of glorified cut and paste. Pastiche is putting together things kind of imitating a style. And in some sense, that's what it's doing. It's imitating particular styles, and it's cutting and pasting a lot of stuff. It's a little bit more complicated than that. But to a first approximation, that's what it's doing is cutting and pasting things.
Being a bit more precise, though still resorting to analogy, what LLMs do is to break down their inputs into lots of little (distributed) bits, and then sometimes reconstruct the originals in the course of their reconstruction process. Because of the immense amounts of data they are now trained on, and because of the immense number of parameters on which they are trained, that reconstruction can in fact sometimes come very close to memorization. The New York Times versus OpenAI lawsuit made that abundantly clear, with a hundred examples like this one, in which ChatGPT reconstructed entire stretches of text (red) from brief prompts2 (black text in top line):

Scientfic work shows this is no fluke. Neural networks do effectively memorize some of what they are trained on, and indeed there is a whole subfield now about the topic. A paper published on November 28 found that it is hard to get them to stop: “current alignment techniques do not eliminate memorization”.
Embarrassingly for Hinton, much of the best work on this comes from Nicolas Carlini who has worked at Google for the last several years, where Hinton also worked until his recent retirement. Because data leakage is such a serious problem, and questions of memorization versus generalization loom so large in the field, Hinton surely should have been aware of it. By not even acknowledging the growing literature on memorization (let alone challenging it), Hinton made himself look to be seriously out of touch.
§
Finally, the argument about understanding is slightly more nuanced. The term understanding itself is not perfectly well-defined. One might conceivably attribute some shallow level of understanding to LLMs, but there are many reasons to doubt that current neural networks have deep understanding.
“Deep understanding” is a term that Davis and I used throughout our 2019 book, Rebooting AI, literally the conceptual focus of the entire book:
In short, our recipe for achieving common sense, and ultimately general intelligence, is this: Start by developing systems that can represent the core frameworks of human knowledge: time, space, causality, basic knowledge of physical objects and their inter-actions, basic knowledge of humans and their interactions. Embed these in an architecture that can be freely extended to every kind of knowledge, keeping always in mind the central tenets of abstraction, compositionality, and tracking of individuals.
Develop powerful reasoning techniques that can deal with knowledge that is com-plex, uncertain, and incomplete and that can freely work both top-down and bottom-up. Connect these to perception, manipulation, and language. Use these to build rich cognitive models of the world. Then finally the keystone: construct a kind of human-inspired learning system that uses all the knowledge and cognitive abilities that the Al has; that incorporates what it learns into its prior knowledge; and that, like a child, voraciously learns from every possible source of information: interacting with the world, interacting with people, reading, watching videos, even being explicitly taught.
Put all that together, and that's how you get to deep understanding.
It's a tall order, but it's what has to be done.
Our central claim was that statistical approximators (such as the earlier, smaller LLMs that were then popular) lack common sense, the ability to reason causally, and so on.
As I put it to Hinton on X today (no reply thus far), reprising and updating what Davis and I have long argued, “Given vast datasets, LLMs approximate well, but their understanding is at best superficial. That’s *why* they are unreliable, and unstable, hallucinate, are constitutionally unable to fact check, etc.”
I stand by all that. I don’t think Hinton has any real argument against it.
§
There is also something important to be said here about politics and rhetoric. Yann LeCun recently has shifted to my position, and Hinton knows it. But he pretends not to—using an old rhetorical trick—to make it look (falsely) like I stand alone.
Here’s an example where Hinton and LeCun discussed this publicly two months ago, on November 25:
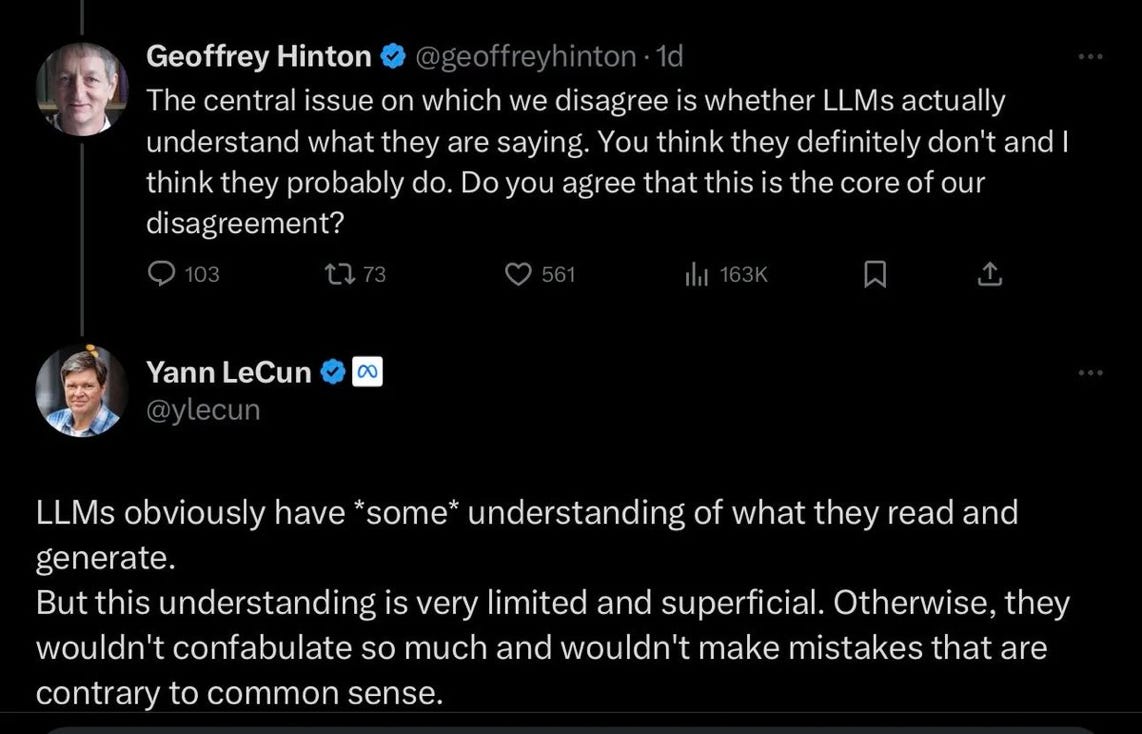
Notice (a) that LeCun makes *exactly* *the same argument I make above and have been making for years, (b) how politely Hinton engages with LeCun, (c) that in the video at the top directed at me Hinton doesn’t address LeCun’s counterargument, and (d) that in the video Hinton does not acknowledge the fact that someone else eminent shares my view—in his effort to falsely portray me as isolated—even though he full well knows that his close colleague LeCun does share that view.
From a politician I might expect such misdirection. From a fellow academic, it is deeply unscholarly.
§
The reality is that Hinton has lost touch. He doesn’t understand the extent to which LLMs do in fact sometimes pastische together huge chunks of texts that have effectively been memorized. LLMs do (sometimes) regurgitate large chunks of effectively stored text, and they don’t understand anything at a deep level. He doesn’t grapple with how his long-time ally has shifted over to my side. And he hasn’t wrapped his head around the many failures (such as regular but unpredictable hallucinations) that show that LLMs are simply approximators, without the true common sense that we would asssociate with deep understanding.
§
It really isn’t just me, or just me and LeCun. As I was writing this, many others leapt to my defense on X, largely making the same points. A least one tech CEO has said out loud what I was thinking:
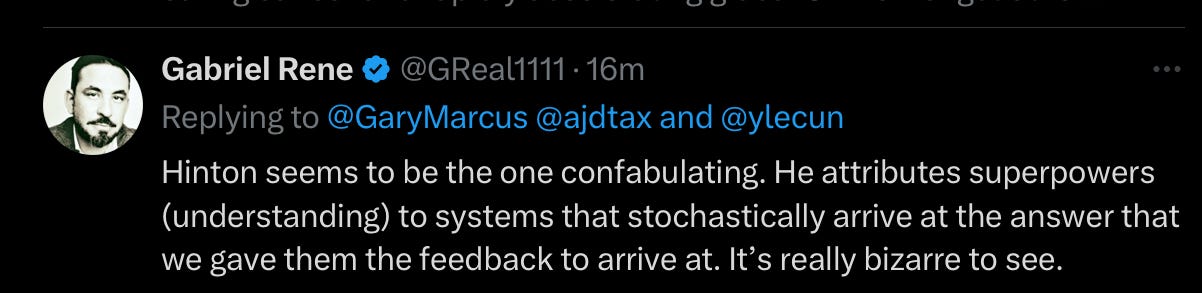
Tim Crane, a philosopher, from Vienna, wrote “very disappointing comment from Hinton, both in content and tone”. Another philosopher, from Auburn, wrote this
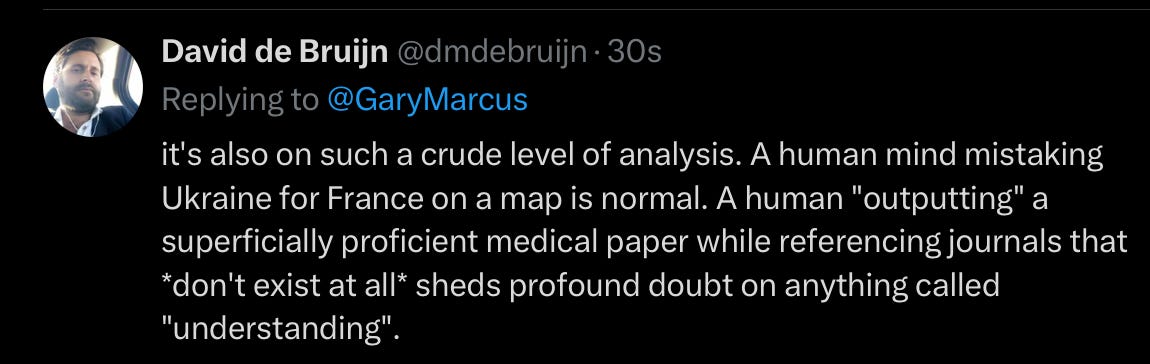
From someone with a M.S., in cognitive science from U. Rochester:
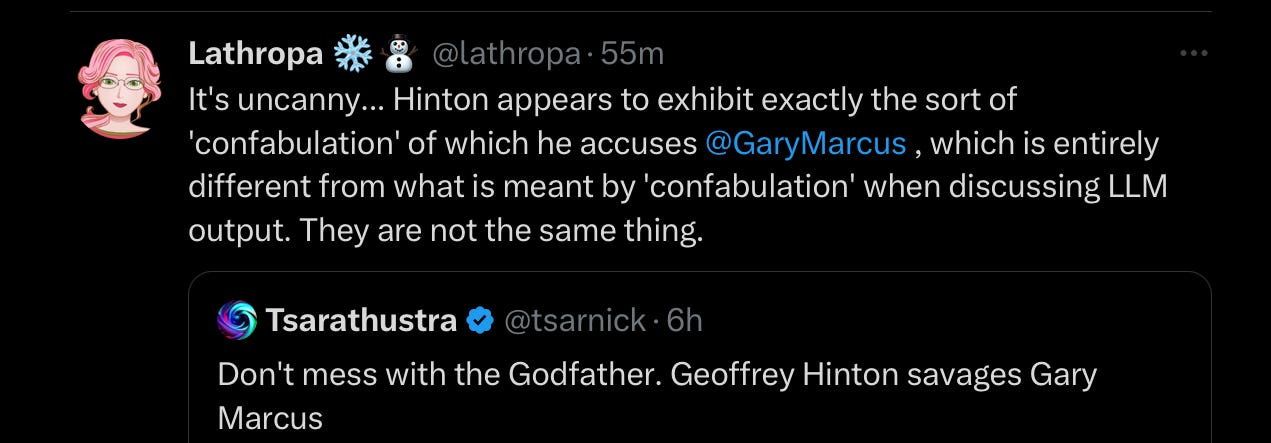
ML researcher and entrepreneur Chomba Bupe added:

The linguist Evelina Leivada was even more scathing:
All that pushback against Hinton, just in the last few hours. I am truly not alone.
§
The irony of all this is that in November Hinton publicly accused LeCun of being intellectually self-absorbed, putting heavy weight on his own views while ignoring contradicting views:

That’s exactly what Hinton has done here. He has mistaken his own opinion for that of many others (almost all experts in classical AI would disagree with him), all the while arguing for a mistaken view in a most condescending yet (in this case) regrettably uninformed way.
Gary Marcus, Professor Emeritus at NYU, is a scientist who has been writing about the limitations of neural networks for over three decades, in books and articles in leading journals such as Science, Nature, Cognition, and Artificial Intelligence. The core challenges that Marcus pointed out in his 2001 MIT Press book The Algebraic Mind, including hallucinations and unreliability, remain unsolved—23 years later.
“They don't pastiche together text that they've read on the web… They’re storing these weights and generating things.” is a somewhere between a false dicotomy and misdirection. LLMs don’t store things in simple databases, but when presented with enough data, their regeneration of distributed bits has demonstrably duplicated lengthy training materials multiple times, a phenomenon that is called memorization in the field.
OpenAI will no doubt by now have filtered this specific example so that it can no longer be replicated, now that it has appeared in a lawsuit. But the variety of the examples along with the technical literature on memorization and data leakage in large language models make clear that this kind of reconstruction certainly can happen with some regularity.
As someone who works with LLMs every day trying to get them to work consistently at scale (that is, applying the same prompt template thousands of times), I can confidently say that LLMs don't understand anything. Something that understood the directions would not give a completely different answer when the prompt is amended to say "Format your answer using JSON". Why would or should that change anything? There is even a paper where they simply changed the format of the prompt /format/ and got different results, "QUANTIFYING LANGUAGE MODELS’ SENSITIVITY TO SPURIOUS FEATURES IN PROMPT DESIGN or: How I learned to start worrying about prompt formatting". That's not understanding.
There are certainly some semantics that come along for the ride when you have trained on massive amounts of text, but that doesn't mean you have semantics. We know this from Eliza.
They are...transformers. We are doing some very clever things with LLMs but we have to be clever because of the LACK of understanding.
AI terminology is at best misleading. We assume these machines must be behaving like humans because... Well, we've always assumed these machines must be behaving like humans. And so we allow ourselves to use terms like "hallucination". Dijkstra pointed out long ago the problems with anthropomorphisms in the software industry. But anthropomorphisms in AI are pathological.