Deep Research, Deep Bullshit, and the potential (model) collapse of science
Sam Altman’s hype might just bite us all in the behind

As Harry Frankfurt observed1, “The liar cares about the truth and attempts to hide it; the bullshitter doesn't care if what he or she says is true or false, but cares only whether the listener is persuaded.“
§
Anyone remember Meta’s Galactica, in the good old days, in mid-November 2022, just a few days before ChatGPT dropped? It was a train wreck, writing perfectly well-formed articles on utter gibberish. A personal favorite, elicited by Tristan Greene in the few short days before Meta withdrew it in November 2022, was this one:

I have good news, for those who like that sort of garbage. Sam Altman just released a fancier remake Deep Research, which, like Meta’s predecessor, can write science-sounding articles on demand, on any topic of your choice.
Influencers were quick to hype it, with a barrage of statements like these, which was retweeted by Sam Altman himself:
A few hours later Unutmaz followed up with more gushing:
And the lemmings ate it up. Hundred thousand views for the latter post alone; over a third of million for the first. We can be sure that DeepResearch will get heavily used.
But that may not be a good thing.
§
Time will tell, but I still feel that one of my most prescient essays was the one posted almost exactly two years ago to the day in which I warned that Generative AI might undermine Google’s business model by polluting the internet with garbage, entitled What Google Should Really be Worried About:

The basic conjecture then — which has already been confirmed to some degree – was that LLMs would be used to write garbage content undermining the value of the internet itself.
At the time, I warned that
Cesspools of automatically-generated fake websites, rather than ChatGPT search, may ultimately come to be the single biggest threat that Google ever faces. After all, if users are left sifting through sewers full of useless misinformation, the value of search would go to zero—potentially killing the company.
For the company that invented Transformers—the major technical advance underlying the large language model revolution—that would be a strange irony indeed.
§
Deep Research, because it works faster and expands the reach of what can be automatically generated, is going to make that problem worse. Scammers will use it, for example, to write “medical reports” that are half-baked (in order to sell ads on the webistes that report such “research”).
But it is not just s scammers; the larger problem may be naive people who believe that the outputs are legit, or who use it as a shortcut for writing journal articles, missing the errors it produces.
§
There aren’t a lot of public samples yet of Deep Research’s output, but one essay that already did circulate, on tariffs, “Revisiting the McKinley Tariff of 1890 through the Lens of Modern Trade Theory”, was initially praised.
On inspection, though, it was not so great. There’s a reddit thread about this already:
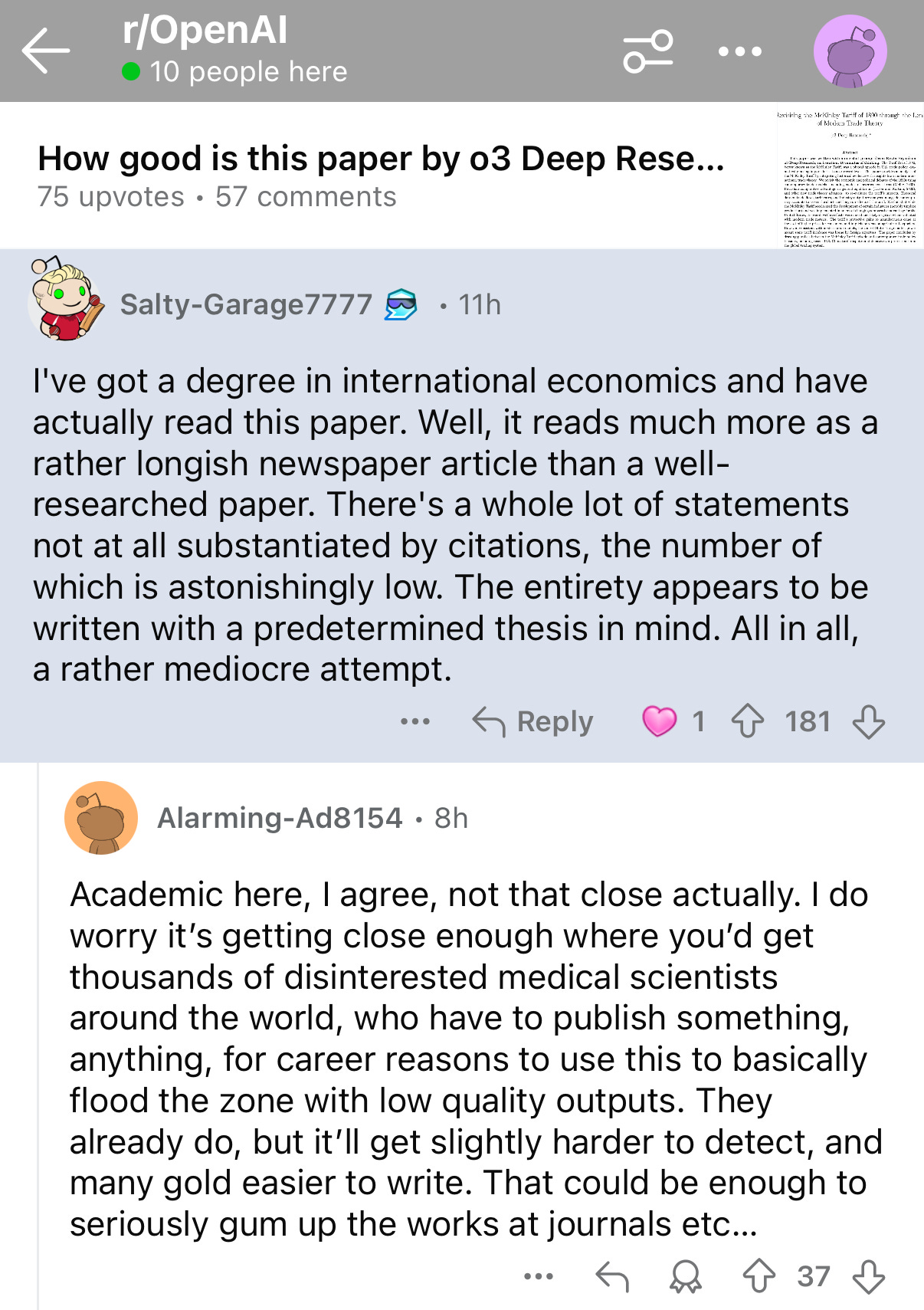
Someone on X absolutely nailed what I think is the real risk here:
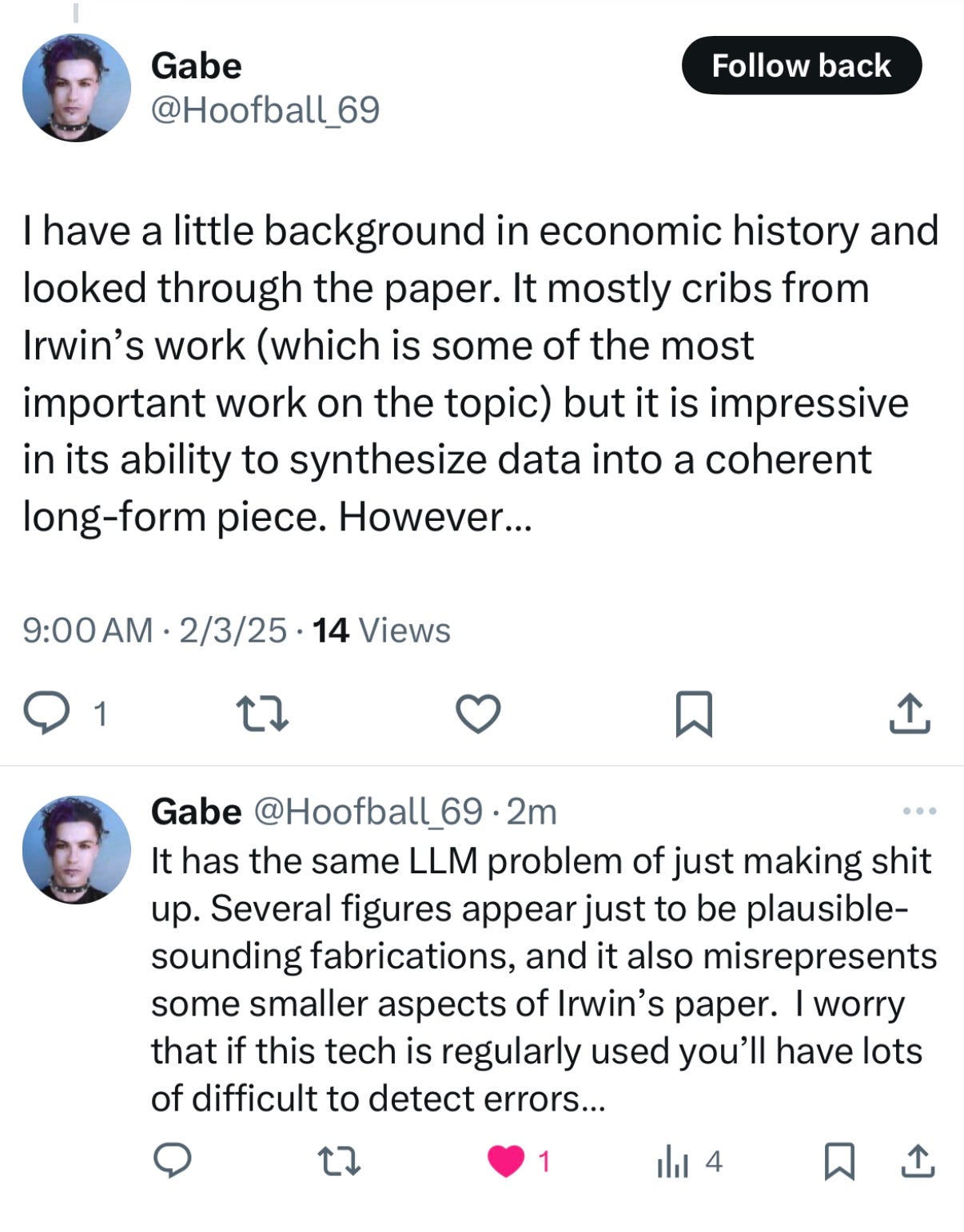
The thing about using “reasoning” to “synthesize large amounts of online information and complete multi-step research” is that you want to get it right, reliably.
And that’s just not realistic given the current state of AI. Indeed, OpenAI themselves acknowledge this in the fine print.
It can sometimes hallucinate facts in responses or make incorrect inferences, though at a notably lower rate than existing ChatGPT models, according to internal evaluations. It may struggle with distinguishing authoritative information from rumors, and currently shows weakness in confidence calibration, often failing to convey uncertainty accurately.
Same old, same old.
§
Unfortunately, virtually everything that Deep Research produces will pass a LGTM test ( “it ‘looks good to me’”); people will assume it’s legit, even when it is isn’t. Few people will fact-check its output carefully, since it will all superficially look ok. Students will quickly learn that every term paper it writes gets an A.
Scientific researchers will start to use it, too (as Unutmaz recommended). And inevitably errors will seep in to the scientific literature,, often undetected.
And once they are there, they won’t go away.
§
“Model collapse”, aka “model autophagy disorder”, is what happens when AI models chase their own tails..
The output of DeepResearch will inevitably feed further models; we will wind up with more of this:

And it’s not just the models that will be infected, but the scientific literature itself.
Because Deep Research lowers the effort, making it trivial to write legit-sounding articles, paper mill factories (there is already such a thing, designed to game citation counts, “an illegitimate, yet lucrative business“ that is growing) will massively ramp up production, choking the peer review process and saturating the market with hard-to-find, hard-to-rectify errors.
When — not if — Deep Research begins to flood the medical zone with shite, we are all in trouble.
Gary Marcus wrote this essay while sitting in a ski lodge, waiting for fog to clear, and worrying about the unstoppable avalanche of scientific garbage that likely awaits us all.
PS Frankfurter’s On Bullshit should be required reading.
Writing this without Frankfurter’s legendary book in hand, so the quote may be a paraphrase from the original. https://en.wikipedia.org/wiki/On_Bullshit
Well, I just ran another set of elementary cryptanalytic tests on these new "reasoning" models and things are pretty much the same. Answers which are glib, confident, and hilariously wrong. I'll write it up soon for my substack.
But real lesson is this: LLMs *mimic* the *form* of reasoning. That's all. There is nothing more to it, no semantics, no meaning, no "understanding." It's just a more elaborate version of the way they *mimic* the *form* of prose. Maybe every time we use the abbreviation "LLM" we should add "(Large Language Mimicry)" after it.
As humans we have a cognitive shortcoming: when we are presented with a well-formed communication we assume it to be derived from a semantic understanding of the topic. We have not been conditioned to recognize large-scale, high-resolution and essentially empty mimicry of language. It's going to take a lot of painful experience to overcome that shortcoming.
I'm stuck on the phrase: "It can sometimes hallucinate facts..."
If it's a "hallucination" it's not a "fact."
Reminds me of one of my favorite Orwell quotes: "If people cannot write well, they cannot think well, and if they cannot think well, others will do their thinking for them."
The BSing we see from places like OpenAI shows that a) they cannot think well; b) they assume we cannot think well; c) most people, in fact, cannot think well enough to see through their smoke screen. Which is why their BS gets so much traction.
And that's a fact, not a hallucination.