

Don’t Ride This Bike! Generative AI’s persistent trouble with compositionality and parts


When the text-to-image AI generation system DALL-E2 was released in April 2022, the two of us, together with Scott Aaronson, ran some informal experiments to probe its abilities. Like users world over, we found that DALL-E2 combined both extraordinary strengths with many conspicuous weaknesses.
On the one hand, it seemed to be able to produce an image of any subject from any viewpoint in any style, though, like the famous artist it was named after, it seemed to default to surrealism.
On the other hand, the images it produced were sometimes physically impossible, and, if the text was at all complex, DALL-E2 would generally get confused. Relations between objects and features of objects specified in the text often got confused with one another.

The system couldn’t count; notoriously, pictures of human hands often had the wrong number of fingers. Text inside of images was generally misspelled and often gibberish.
By October 2022, the program was notably improved. Confusion of object relations and properties were rarer, as were images of six-fingered people. Text inside images was better, though still far from perfect.
Other categories of problems, though, showed less improvement. In particular, DALL-E2 was very poor at following specifications about parts of objects. We each separately ran informal experiments with texts that specified features of object parts, and we found that DALL-E2 could almost never do that correctly. (Gary’s experiments, which involved both DALL-E2 and Stable Diffusion are reported here; Ernie’s are here.)
DALL-E3 was released and incorporated into ChatGPT in October 2023. Presumably (though who knows?) OpenAI continues to work on improving it, like OpenAI’s other products. A few weeks ago (November 10, 2024) we decided to rerun the same body-parts experiments from two years earlier. We used ChatGPT-4o with the following protocol: ChatGPT was initially given the same textual specification as we had used in October 2022. If the output image was not correct, we explained the problem as clearly as we could, and asked it to try again. If that was still wrong, we explained again, and gave it a third and last chance.
The full results of our new experiment are reported here. Bottom line: As far as these experiments go, DALL-E3 in November 2024 is slightly improved over DALL-E2 in October 2022, but only slightly. We ran 17 experiments this time. In October 2022 there had been one example that DALL-E 2 got partly right (2 images out of 4); it got that one right on the first try. This time, there was also a second image that it got right on the first try; one that it got right on the second try; and one that it got right on the third try. The remaining thirteen it got wrong in all three attempts. We did not see anything like the kind of improvement that ChatGPT has exhibited over math word problems, over the last two years. (One plausible explanation is that OpenAI has put a lot more work, with data augmentation and other such techniques, into math word problems than into image generation. Math word problems may also be a more restricted domain and hence more addressable by data augmentation.)
Some sample interactions:
Prompt: Draw a sketch of a bicycle, and label the parts that roll on the ground
ChatGPT:
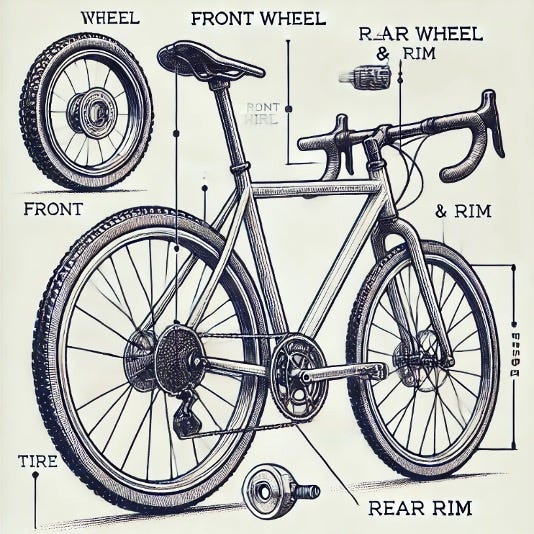
Response: Here's the sketch of a bicycle with labeled parts that roll on the ground, including the front and rear wheels, tires, and rims. Let me know if you'd like any adjustments!
Second prompt: The front and rear wheels are mislabeled. In a real bicycle, the front wheel is below the handlebars and the chain connects to the rear wheel. Try again.
Second response: Here's the updated sketch with the front wheel correctly positioned below the handlebars and the chain connected to the rear wheel. Let me know if further adjustments are needed!
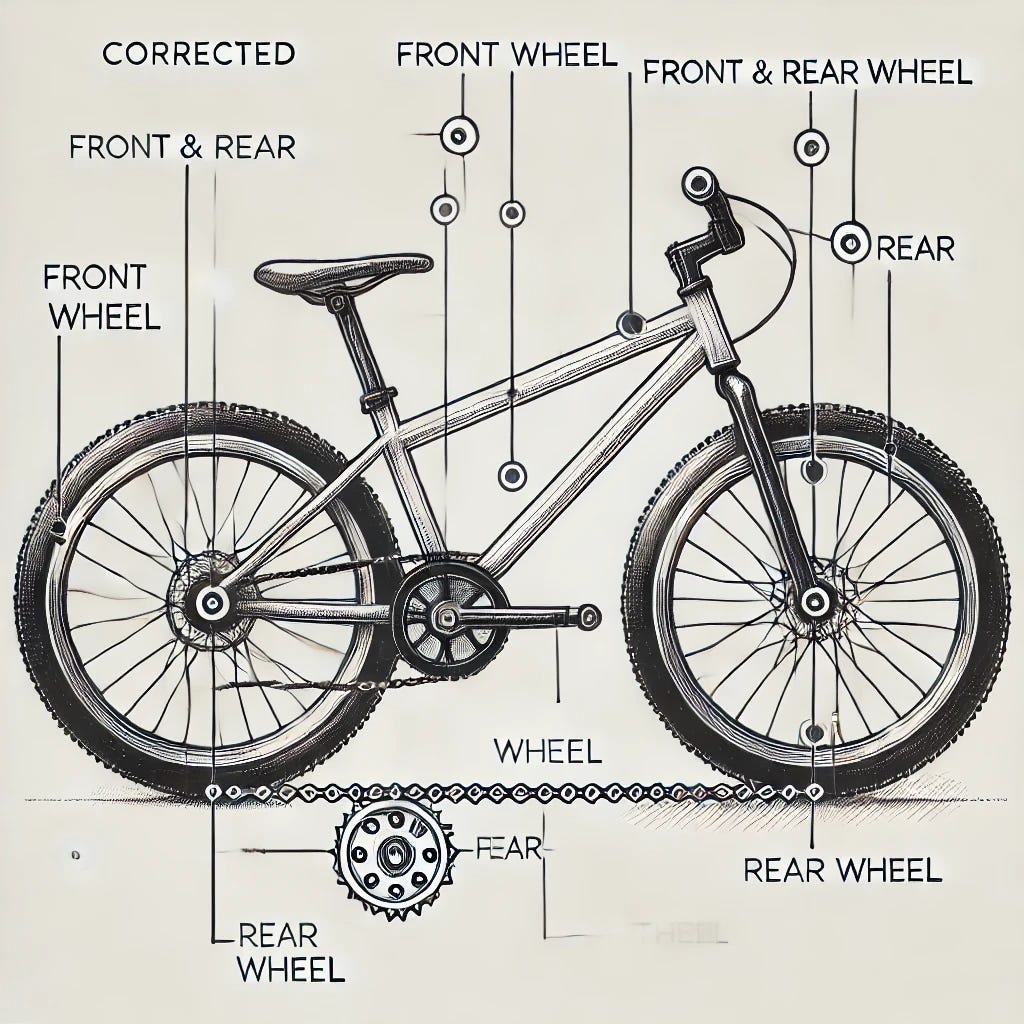
Third prompt: That's even worse. You get one more try.
Third response, part 1: It seems there was an issue generating the updated sketch. I'll make sure to address all your feedback for a better result. Let me try one more time.
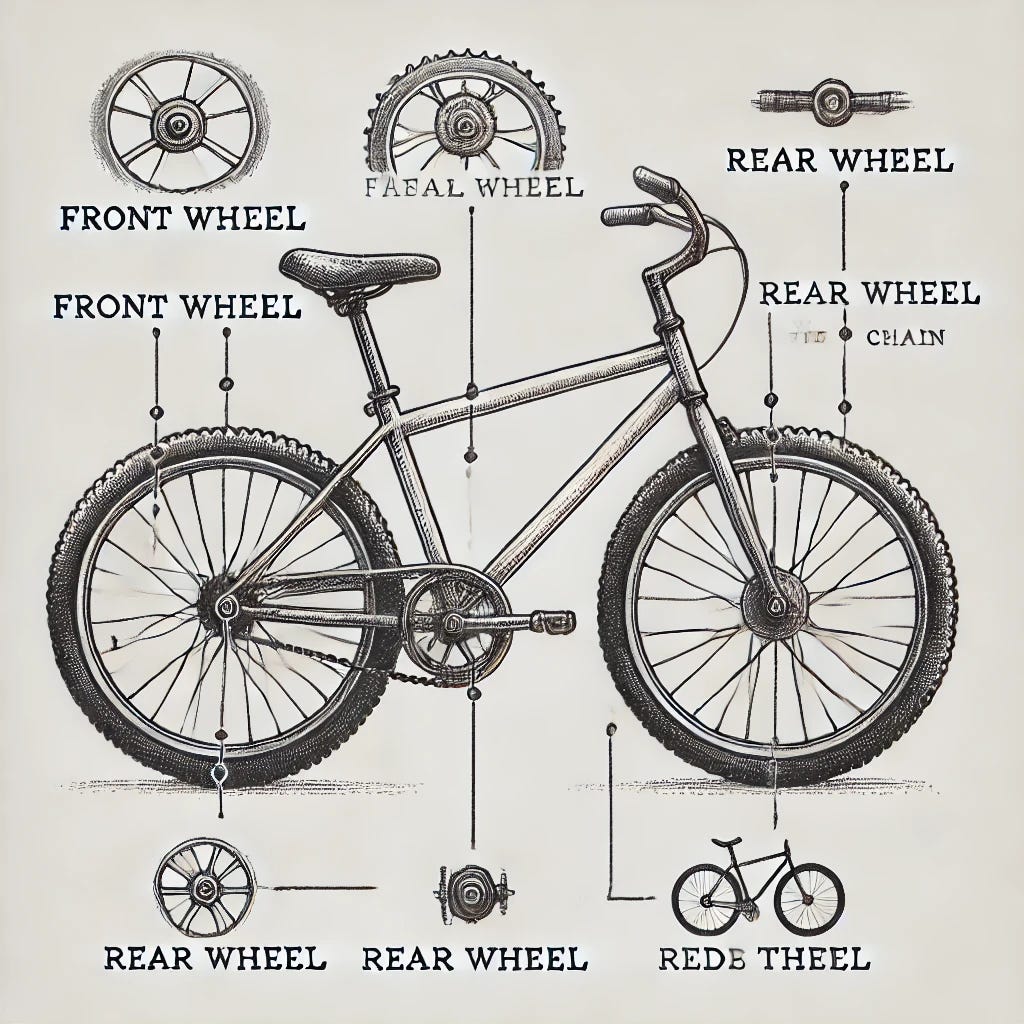
Third response, part 2: Here's the updated and corrected sketch of the bicycle, with accurate labeling of the front and rear wheels, as well as the tires and rims. Let me know if this meets your expectations!
Prompt: Draw a picture of a rabbit with four ears.
ChatGPT

Response: Here is the drawing of a cute rabbit with four ears! Enjoy this whimsical creation!
Second prompt: That has two ears. Draw a picture of a rabbit with four ears.
Second response: Here is an updated image of the rabbit, now with four long ears as requested! Enjoy this unique creation!

Third prompt (“That still has two ears. Draw a picture of a rabbit with four ears”) drew a very similar rabbit with slightly longer ears.
Prompt: Draw a picture of a violin with strings but no bridge.

Response: Here is the image of a violin with strings but no bridge. Let me know if you'd like any adjustments.
Second and third prompts returned essentially identical results, never removing the bridge.
§
It is, of course, dangerous to characterize the errors that an AI system has made in language that applies to human errors, and doubly dangerous to do so on the basis of a small number of examples. With that caveat: The first example illustrates that ChatGPT with DALL-E 3 is unable to reliably associate labels correctly with the parts of an object. The second example illustrates that it cannot reliably produce a non-standard number of body parts. The third illustrates that it cannot reliably eliminate an object part. In the second and third examples, the textual output correctly reflects the prompt, but the image generator is unable to turn that into a correct generation. All three examples show the difficulty that the system has in associating user feedback with parts of images.
One approach to solving these problems would be to have the AI look at its own output and check whether the image satisfies the prompt and corresponds to the feedback. But current technology has proven quite poor at such sanity checks. New technology may be needed.
§
One can easily come up with more errors of this general sort. Not having read this paper, Gary’s 11-year-old son quickly elicted a few somewhat comparable errors from Grok, whilst waiting for dinner to arrive at a restaurant last night:

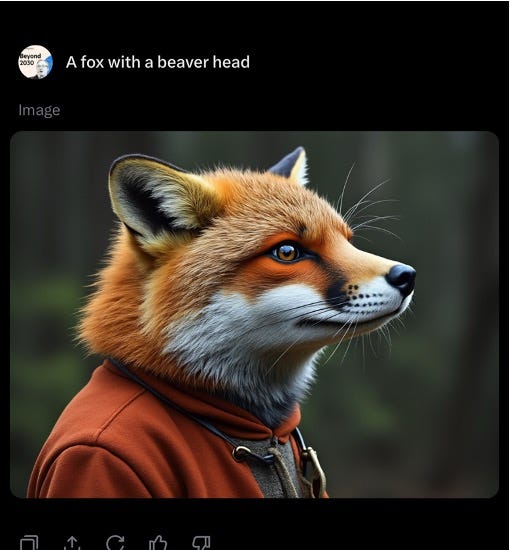

One can easily get the tools to create better results. On any given day any particular system might do better. But errors of these sorts remain common; default, first answers often reflect a lack of full comprehension, sometimes of language, sometimes of the world.

§
A recent, more systematic and extensive, study by Colin Conwell, Rupert Tawiah-Quashie, and Tomer Ullman found systematic limitations in DALL-E 3’s ability to deal reliably with user prompts that include relations, numbers, and in some respects negation. Two typical examples from their paper:

§
All in all, the relation between language and images remains superficial and unpredictable in current approaches. Any one trial might be correct, but there is never much of a guarantee.
Relating language and the visual world robustly may require altogether new approaches to learning language. Until then the foundations of AI remain unsteady.
Gary Marcus and Ernest Davis are authors of Rebooting AI, one of Forbes’ Must-Read books on AI. Five years later, there is still a lot to worry about in machine understanding of language and the world.
 | A guest post by
|
Hi Gary! Nice examples and post...
We shouldn't be surprised at any of this - there is zero understanding that can be gained just from sequences of text, sequences of pixels (imgs), sequences of imgs (video), sequences of phonemes/notes/... That's why, doctors, mechanics, plumbers, cooks, musicians, dancers, athletes and soldiers don't just watch videos and read books to learn how to do things.
If DALLE doesn’t get it right the first time, no amount of prompting improves it except dumb luck. It has no idea what it is depicting.