Further Trouble in Hinton City
More on storage and the shallow understanding of Generative AI

A couple of days ago I gave a whole bunch of reasons to doubt Hinton’s confident but problematic claims that GenAI systems don’t store things and do understand them.
More evidence against his claims just keeps piling up.
One piece of evidence comes from a new study that I plan to discuss in a future essay, which examines how sensitive LLMs are to minor perturbations, like rearranging the order of answers in multiple choice, the insertion of special characters, or changes to the answer format. As it turns out, minor changes make a noticeable difference, enough to rearrange “leaderboard” rankings. If a system really had a deep understanding, trivial perturbations wouldn’t have such effects.
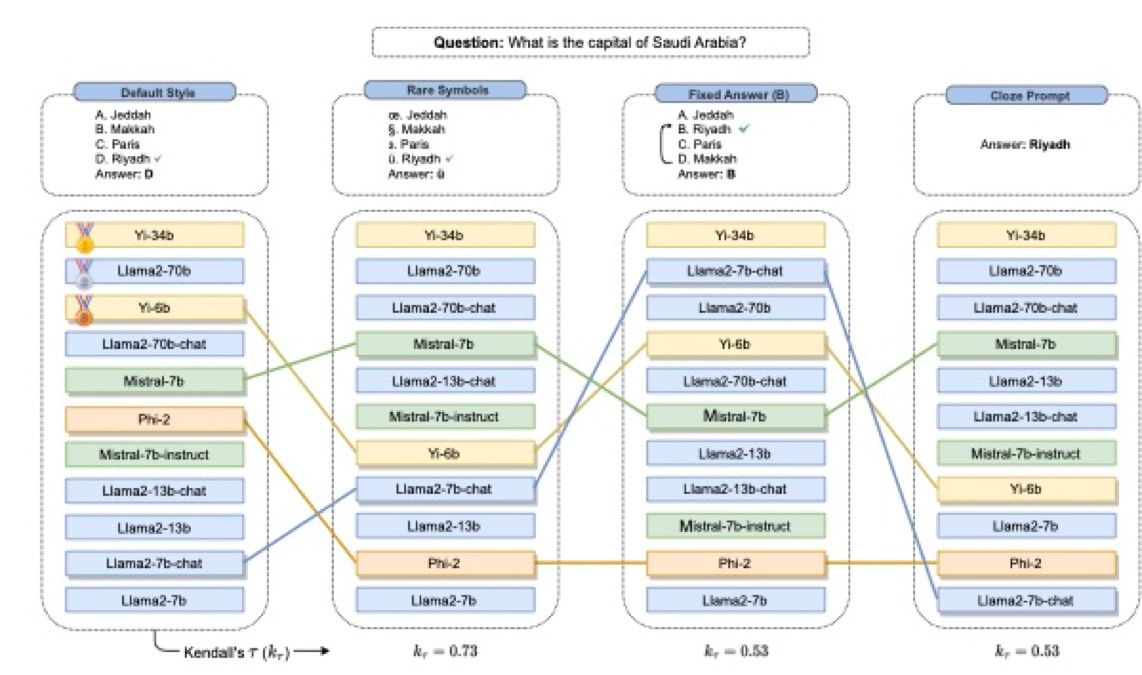
Suffice to say for now, it’s not a win for LLMs and understanding.
§
In the meantime, in the picture is worth a 1,000 words department, here’s a very clever example, from Substack author
, which speaks strongly yet concisely against everything Hinton was trying to say:
The example highlights three things:
1. GenAI systems do effectively store things. (In this case, canonical video game controller images.)
2. They are attracted1 𝘵𝘰 those effectively-stored2 representations, particularly (I would presume) frequent ones. They (often) don’t come up with a novel independent design that would meet the requirements. (The “italian plumbers” examples I have discussed, in which GenAI systems tend to gravitate towards Nintendo’s trademarked Mario character, illustrate the same thing.)
3. They fail to “understand” simple concepts, such as “design to used with only one hand.” This should remind you of my older essays Horse Rides Astronaut and Race, statistics, and the persistent cognitive limitations of DALL-E. Noncanonical situations continue to remain difficult for generative AI systems, precisely because frequent statistics are a mediocre substitute for deep understanding.
§
I will leave the last words this time to the well-known ML expert François Chollet:

Gary Marcus loves it when an argument comes together.
Attracted to does not of course mean that no other output is possible. Someone on X was able to get Midjourney to produce an image of a truly one-handed controller with a different prompt. But that prompt (itself machine-generated from a 50 word prompt)) was vastly more directive, and far more complex, involving 245 words, the first quarter or so of which I include here “A cutting-edge video game controller designed for one-handed use, shaped like a teardrop for ergonomic comfort and grip stability. The base of the teardrop fits snugly in the palm, while the narrower top allows easy access to controls with the thumb and fingers…” As Devine Morse, a philosophy PhD student, put it, “I could also get an unusually obedient toddler to write Shakespeare if I gave them detailed enough instructions”. There are other ways to break free from the attractors (“let’s think this through step by step” is rumored to be having some success) but what you get by default does often seem to that which has been highly trained.
By effectively stored I mean stored in some way such that something can be easily reconstructed, such as a JPEG file which is not a bitmap but still obviously on any reasonable interpreting a form of storage that can be readily be reconstructed to something nearly identical to the original.
"LLMs break down on anything that wasn’t in their training data. Because they’re 100% memorization."
If this doesn't elucidate why the bots can't produce new or original creative work, nothing will. Am growing weary of people arguing that "humans create the same way as LLMs." We might need a new vocabulary to better define artistry, creativity, and mastery.
Very interesting study, thanks for sharing. That's going to be my morning read.
PS. I love how Chollet writes and thinks about this stuff, very lucid and in way that everybody can understand. (Very similar to your style). His analogy of the LLM as a "program database" is a great mental model to understand what they're doing. I quote: "Prompt engineering is the process of searching through program space to find the program that empirically seems to perform best on your target task. It's no different than trying different keywords when doing a Google search for a piece of software."