Muddles about Models
Why it’s stretch to say that large language models represent ”literal world models”

In a new paper that is lighting X on fire (1.6 million views and counting), called Language Models Represent Space and Time, Wes Gurnee and Max Tegmark argue that “modern LLMs acquire structured knowledge about fundamental dimensions such as space and time, supporting the view that they learn not merely superficial statistics, but literal world models”, based on some analyses of the alleged capacity of LLMs to understand geography.
Although I have little doubt in the results, I sharply disagree with their argument. Of course as Fei Fei Li correctly pointed out on X, it all depends on what you mean by a “model”, but here’s the crux, same as it ever was: correlations aren’t causal, semantic models.
Finding that some stuff correlates with space or time doesn’t mean that stuff genuinely represents space or time. No human worth their salt would think there are dozens of cities thousands of miles off East Coast, throughout the Atlantic Ocean.
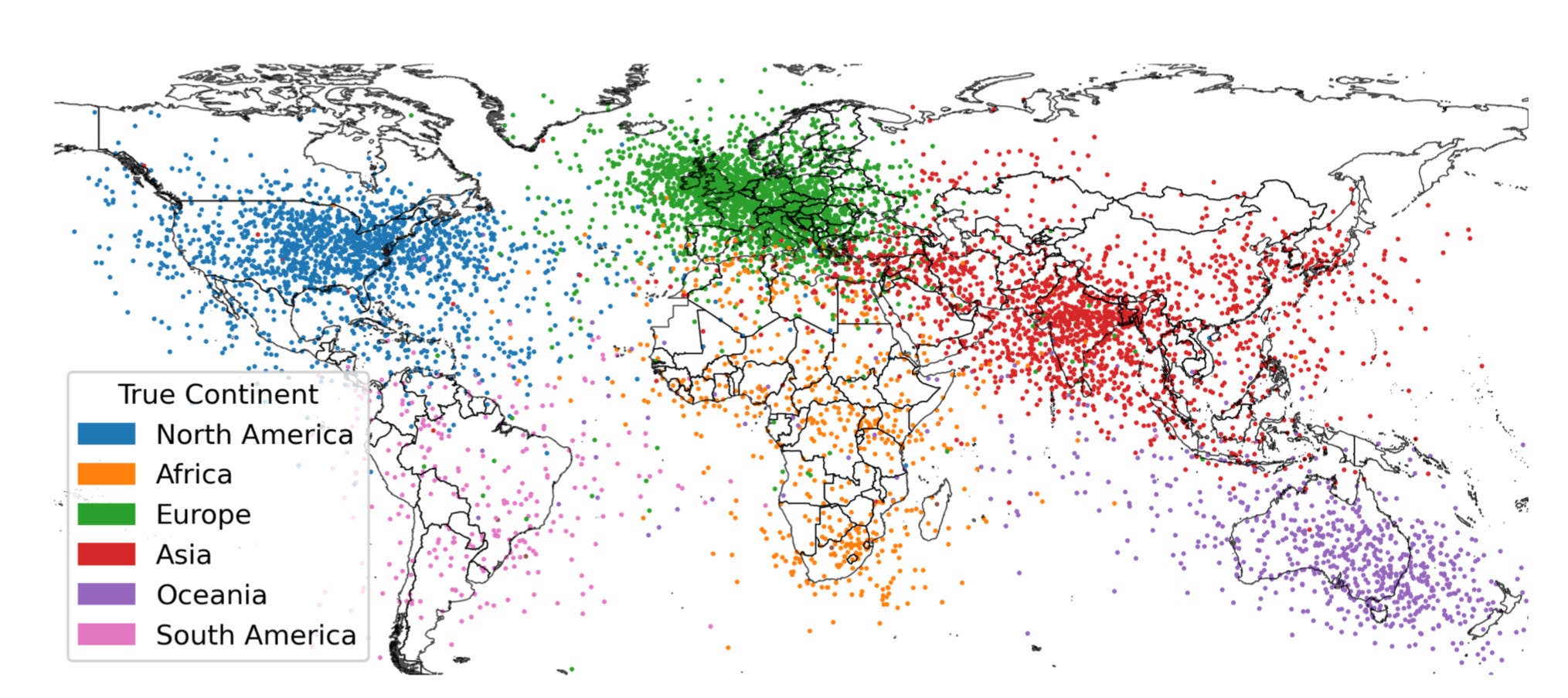
Correlating where cities are with what’s said about them is no substitute for a map.
It’s also not even remotely new. Although Gurnee and Tegmark seem impressed with their results (“we attempt to extract an actual map of the world!”) the fact at geography can be weakly but imperfectly inferred from language corpora— is actually already well-known, A thread on X points out that there in fact lots of earlier results that are essentially similar, like this barely-discussed one from 2017, using a variety of older techniques:
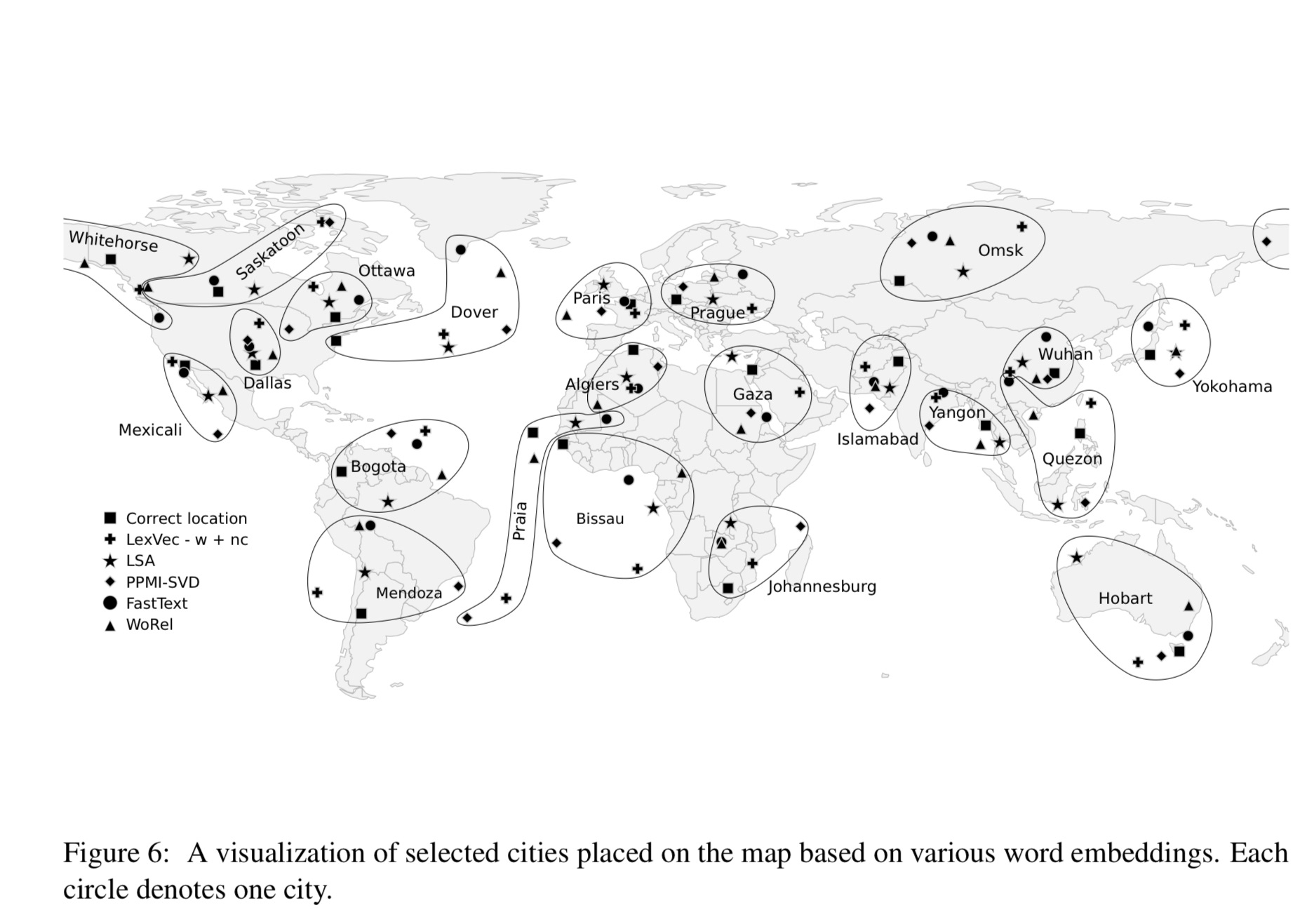
To which I will add this one, more primitive, from 2009, hinging on an earlier text-driven technique called Latent Semantic Analysis:
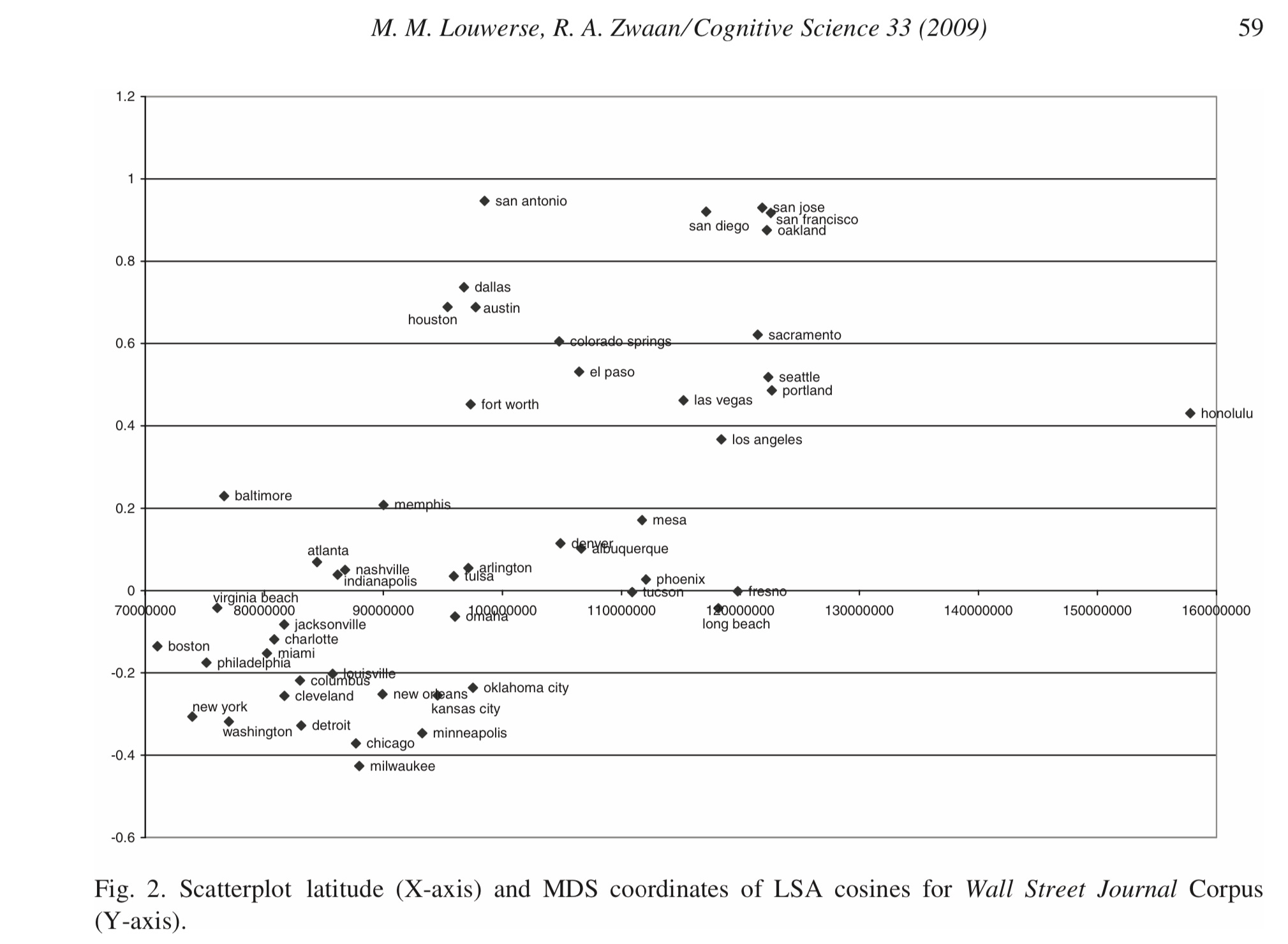
You don’t need a large language model to discover that Dallas and Austin are commonly used in sentences about Texas, and that Chicago and Milwaukee often appear together, too, in sentences about the Great Lakes. (And it is not even clear that LLMs do this any better at this than the many other older techniques studied in 2017.)
§
I asked Ernie Davis about the new paper, and he wrote back a couple hours later with a razor-sharp email, pointing out that even if you charitably called the findings that Gurnee and Tegmark documented a “model”, the system as a whole probably doesn’t actually use that (much) downstream.
Figure 1 of the paper places a fair number of North American cities in the middle of the Atlantic Ocean. OK, so if you take one of those cities and ask for the distance to some city that is correctly placed, does it use the positions as computed by this model? If it doesn't --- and I'd bet very long odds that it doesn’t do that --- then that seems to me evidence that the model is not being used. Or, if someone wants to claim that it isn't evidence, then they would have to explain that.
The whole point of models is to be able to use them downstream for other purposes, e,g, in robotics, navigation, computer graphics, and so on. Models that can’t be used downstream are scarcely worthy of the name, and are in no position to solve the reliability problems that plague current AI.
Importantly, as Davis put it, just because you can approximate some feature (like location) doesn’t mean you can reliably use it semantically for inference (is Newark off the coast of the US?).1
§
Nor does it mean that an LLM has abstracted what a map is, such that it could read e.g, the maps from https://azgaar.github.io/Fantasy-Map-Generator/ and determine whether you necessarily need to to pass through Yeorian Trade Company to get from the Kingdom of Lendokia to the Herheimian Empire.
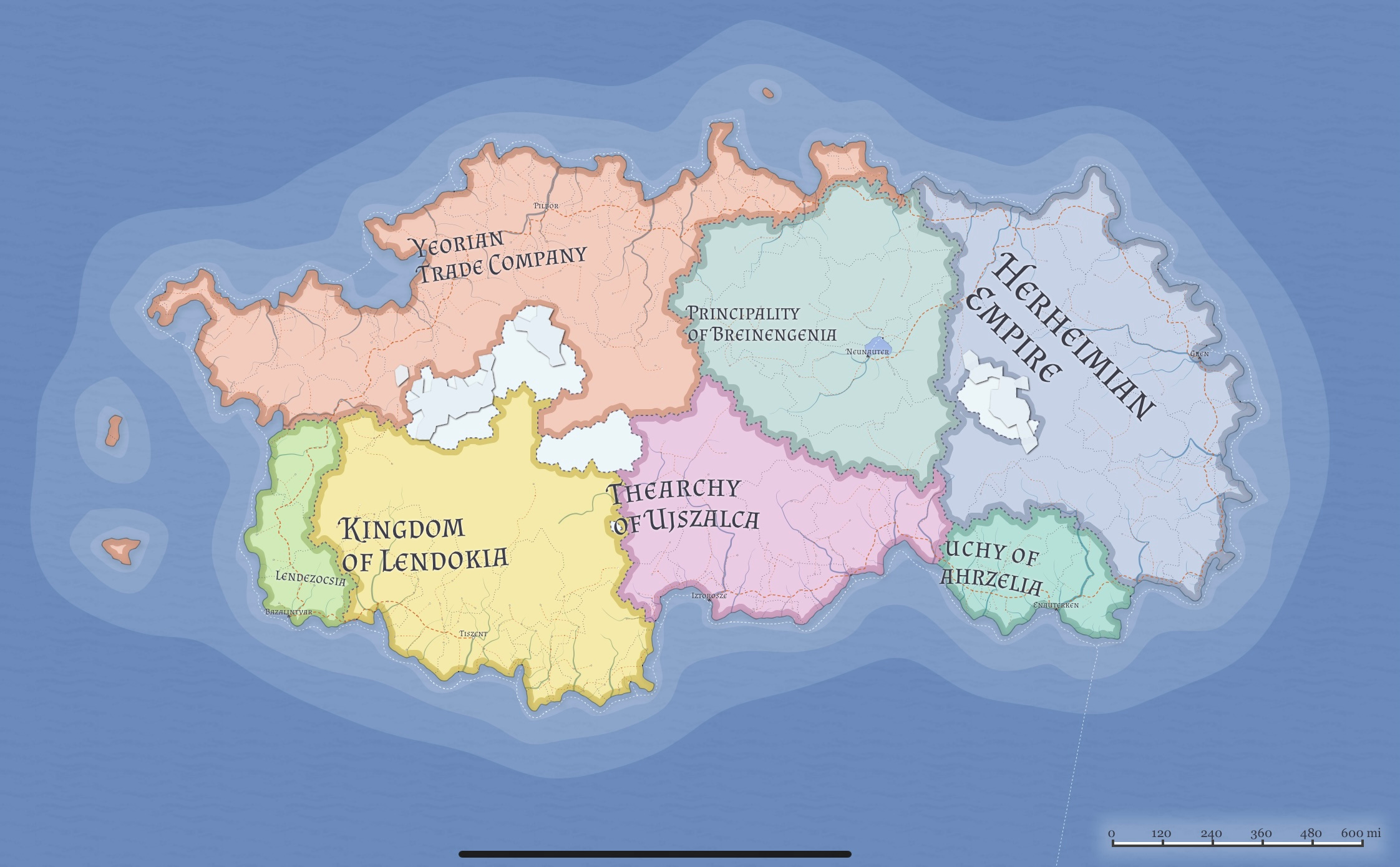
§
Subbarao (Rao) Kambhampati nailed the underlying issue well with this sarcastic tweet:
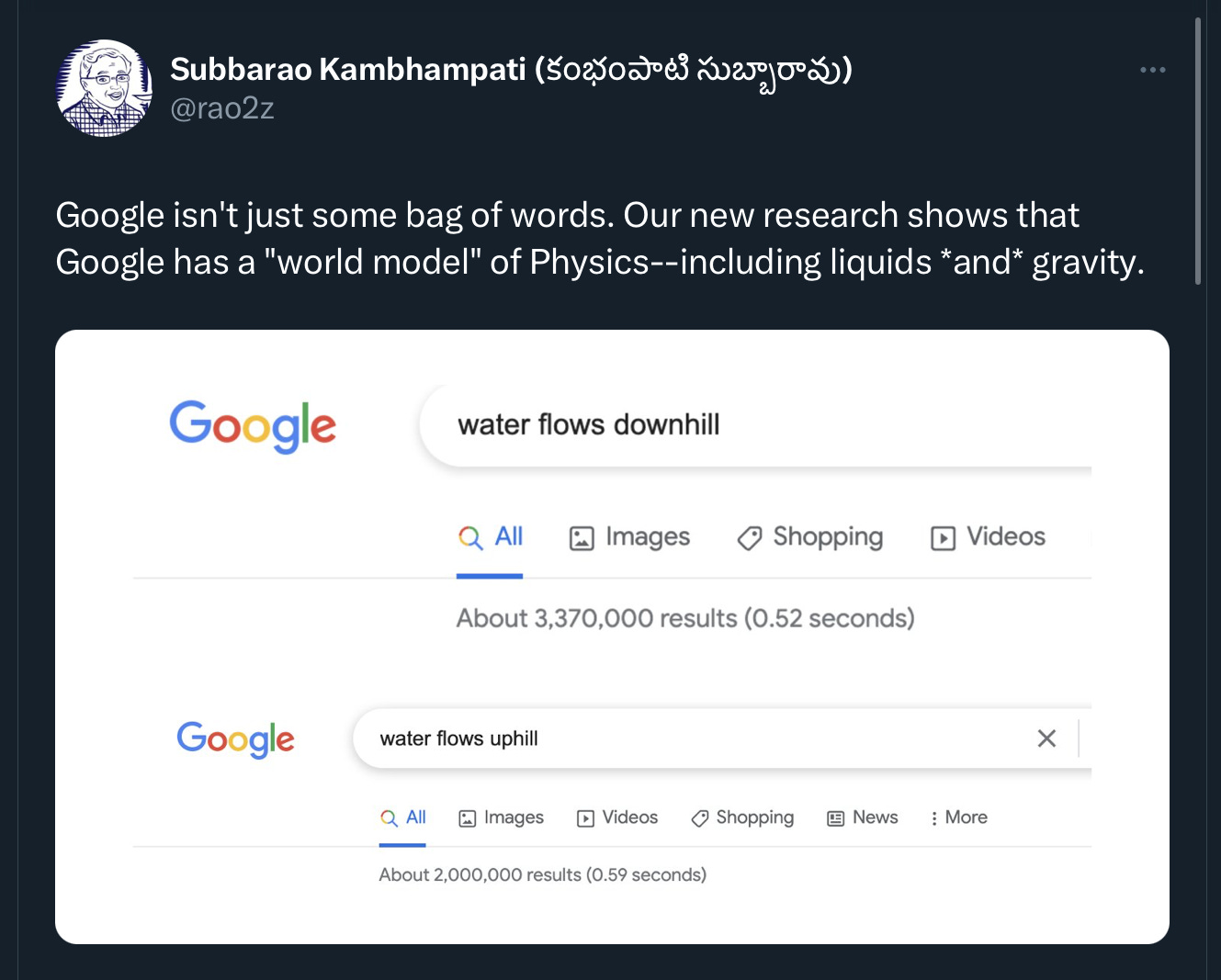
Nobody serious thinks that Google Search has a model of physics in any meaningful sense of the word. (Rao notes that his tongue was in cheek). Just because there is (in this case) a correlation between the number of web hits and physical reality, doesn’t mean Google Search has a model of physics that could e,g. guide a domestic robot. Yes, Google Search accounting might sometimes get things right, because the ways that people use language on the web correlates to some degree the world. But doesn’t mean you can rely on the variable number of Google hits as a physical model of the world. It will work for some things but not others. If you want trustworthy AI, this ain’t it.
§
Every week or three somebody tries to persuade me that GPT has miraculously learned to play chess, but inevitably someone else reports that the latest systems still regularly maks illegal moves like these, that no human player with even modest competence would ever make:

To be sure, GPT can sometimes play a decent (never world-class) game of case by correlating against some massive library of chess games that it has no doubt been trained on. But even when it does, it still doesn’t really model the rules of chess well enough to stick to them. It’s the same problem: correlations are fragile, and you can’t count on them.
I would conjecture that you can’t say to ChatGPT, let’s play a game of chess and then (say) 37 moves in pause, and get it to reliably answer how many white bishops are left on the board, nor to explain what happened to some pawn that had been taken a few moves earlier. The system’s guess about moves in correlation space doesn’t correspond to an actual board that could be analyzed in unexpected ways. Maybe there is a state in game space represented (to use technical language) but there is no semantic model that could be used in flexible ways.
Pretty much every fantasy I have ever heard about GPT-5 doesn’t reckon with that fact, the fact that the correlational regime doesn’t yield flexible models that can reliably support inferences on novel questions. (Any military application you might imagine would be toast for precisely that reason.)
Without flexible underlying models that can reliably support inferences on novel questions, we can expect more of the same of what we are seeing over and over now: more hallucinations, more reasoning that is hit or miss, and nothing like the stability we should insist on for future AI.
§
In The Information, the reporter Kaya Yurieff just tried out LinkedIn’s new OpenAI powered assistant, and found the usual schmeer of plausible errors, same truth mixed with BS we have come to expect over and over again:
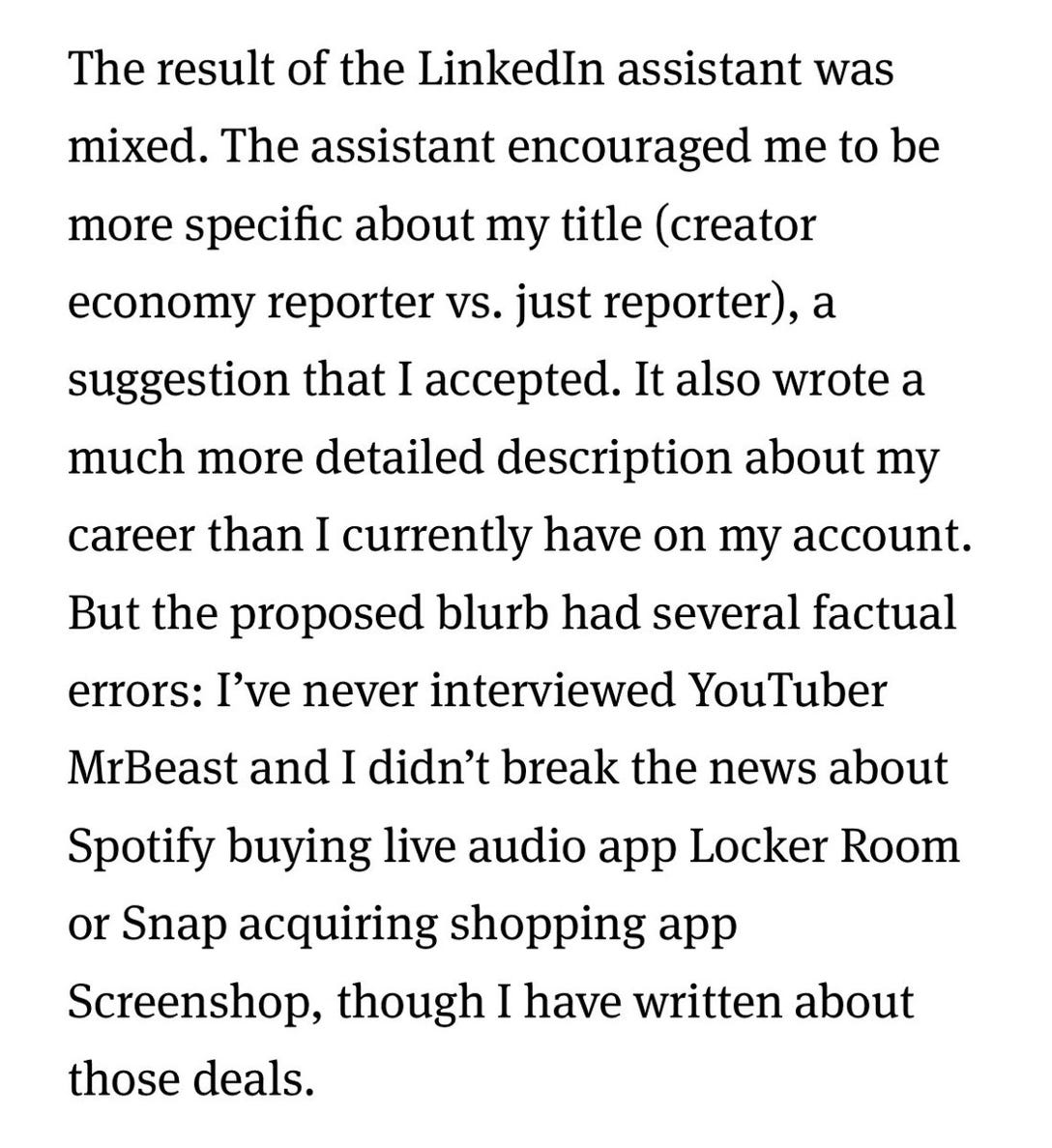
It’s actually the same issue. The system doesn’t have a semantically valid model of what Yurieff has actually done with her life, just correlations in word space. It’s maybe plausible that she interviewed MrBeast, but she didn’t. There is no internal model of what she actually did, and hence no capacity to support reliable inference, hence no guarantee that anything it writes about her will be true.
To encapsulate the heart of what Ernie Davis and I said at length in our 2019 book Rebooting AI, AI is unlikely to ever be trustworthy if its makers continue to skip the step of having explicit cognitive models of the world. Nothing in Gurnee and Tegmark’s new results change that. Some corpus statistics will correlate well with world, some will wind up lost in the Atlantic sea.
And here is why all this matters: safety, which is what Tegmark really cares about, is not going to emerge anytime soon, and probably ever, from hit-or-miss systems that substitute correlation for a factual, structured, interrogable representations of the world.
And pretending that they might is not going to get us closer to safe AI.
Gary Marcus lives in the hope that people who are trying to build AI will eventually read and understand the cognitive science literature.
Davis also points out that, although Gurney and Tegmark emphasize advances in LLM’s discovery of space and time, the model that they have identified represents longitude as a linear value from -180 to 180 degrees, with no idea that it circles back on itself.
Excellent piece. I have come to understand that all the great results attributed to LLMs should instead be attributed to the millions of human beings that LLMs use as preprocessors. LLMs are essentially cheaters with no understanding. What LLMs do show is that human language is highly statistical. But this is not a great scientific breakthrough since linguists have known this for decades, if not centuries.
The hype surrounding LLMs (and generative AI in general) always brings me to what I consider to be the acid test for AGI. Can it be used to design a robot cook that can walk into an unfamiliar kitchen and fix a meal? Generative AI models don't stand a chance to pass this test. Not in a billion years.
To say that a language model has a model of the world is an oxymoron. There is a general principle here. The general principal is that all of these claims that some GenAI model has a cognitive property are all based on the logical fallacy of affirming the consequent. Here is an example of this pseudologic. If Lincoln was killed by robots, then Lincoln is dead. Lincoln is dead, therefore, he was killed by robots. This conclusion is obviously nonsense.
In the case of GenAI, the argument is: If the model has this cognitive property (reasoning, sentience, model of the world, etc.), then it will answer this question correctly. It answers correctly, therefore it has the described competence. This conclusion is no more valid than the one about Lincoln's death. It is not valid to assume from the consequent, that the premise is true. Other factors could have produced the result (John Wilkes Booth or language patterns).
To assert that large language models have any properties beyond those that were designed into them (language modeling) is magical thinking based on a logical fallacy. The language model is sufficient to explain the observation, and since we know how the language models was built, we have no reason to think that there is any more to it than that.