Partial Regurgitation and how LLMs really work
A sticky example / Up with which I will not chuck

There's someone called Gary Marcus who criticizes neural nets and he says, "Neural nets don't really understand anything, they read on the web." Well that's 'cause he doesn't understand how they work.1 He's just kind of making up how he thinks it works.
They don't pastiche together text that they've read on the web, because they're not storing any text. They're storing these weights.
– Geoffrey Hinton
Hinton is partly right, partly wrong. Neural nets do store weights, but that doesn’t mean that they know what they are talking about, and is also doesn’t mean that don’t memorize texts, as the New York Times lawsuit showed decisively:

§
The tricky part, though — and this what confuses many people, even some who are quite famous — is that the regurgitative process need not be verbatim.
As of tonight, I have a new favorite example of what we might call —and sorry for being gross – but we need a new term for this, partial regurgitation.
Compare the automatically-generated bullshit on the left (in this case produced by Google’s AI) with what appears to be the original source on the right.
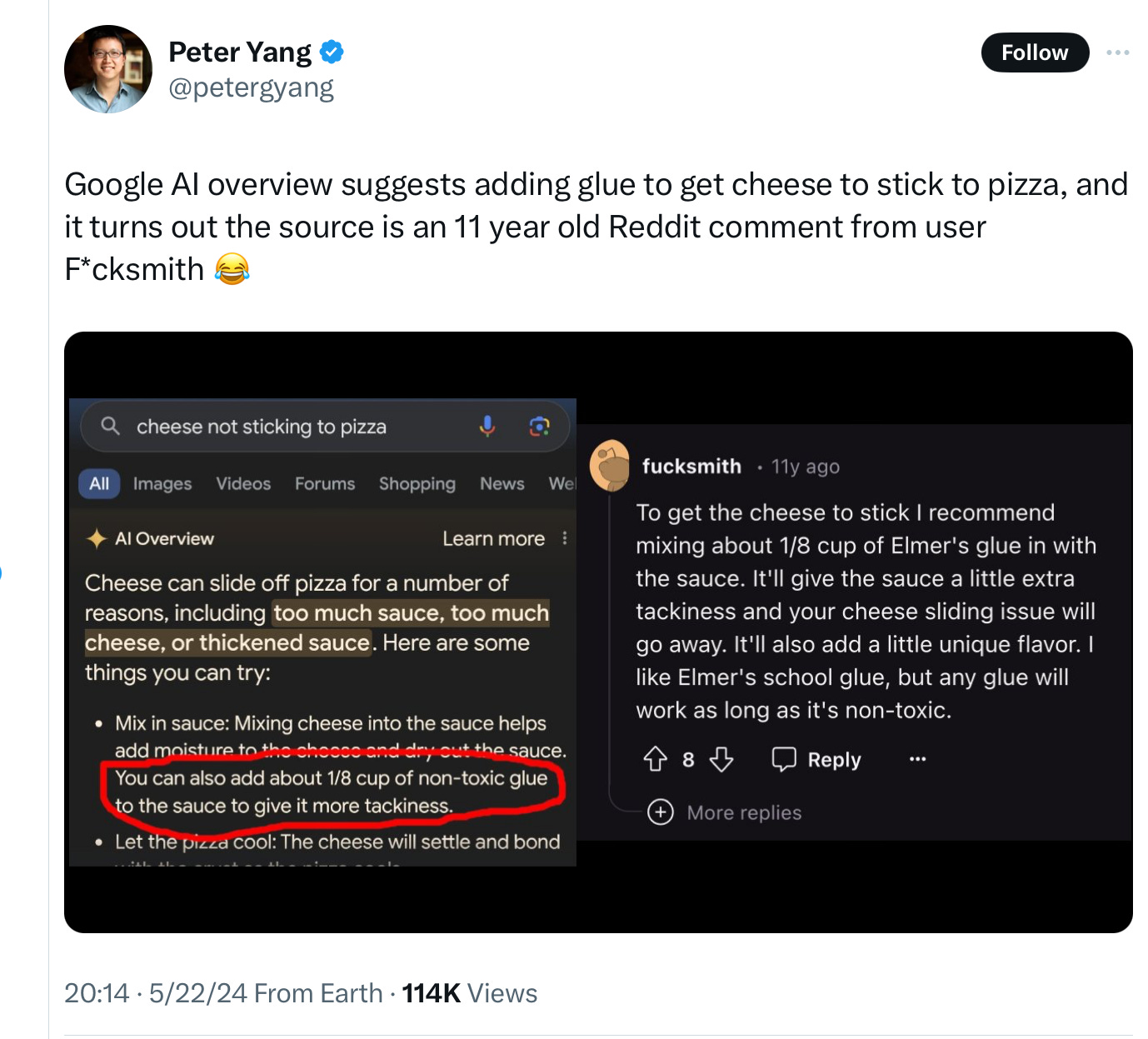
Very important that the glue be nontoxic.
§
Partial regurgitation is not the full monte. “You can also add about 1/8 cup of non-toxic glue to the sauce to give it more tackiness” is not a verbatim reconstruction of f*cksmith’s priceless instructions, which tell us to mix the 1/8 cup rather than to add it, and mix in Elmer’s glue rather than non-toxic glue, promising a little extra tackiness rather than more tackiness. But if output on the left ain’t pastische based on the output on the right, I don’t what is.
AGI, if it ever arrived, would contemplate the recipe and its effects on human biology and psychology, as well its relation to other pizza recipes. What the LLM does is more akin to what some high school students do when they plagiarize: change a few words here or there, while still sticking close to the original.
LLMs are great at that. By clustering piles of similar things together in a giant n-dimensional space, they pretty much automatically become synonym and pastische machines, regurgitating a lot of words with slight paraphrases while adding conceptually little, and understanding even less.
This particular LLM doesn’t know what Elmer’s glue is, nor why one would find it offputting to find it in a pizza. There’s no knowledge of gastronomy, no knowledge of human taste, no knowledge of biology, no knowledge of adhesives, just the unknowing repetition of a joke from reddit — by a machine that doesn’t get the joke — refracted through a synonym and paraphrasing wizard that is grammatically adept but conceptually brain-dead.
Partial regurgitation, no matter how fluent, does not, and will not ever, constitute genuine comprehension.
Getting to real AI will require a different approach.
Gary Marcus is not in the mood for Jello and prefers not to have glue on his pizza.
I started working on AI using Lisp machines and knowledge representation somewhat similar to the early yahoo knowledge encodings, but this was in the 80s. This approach was abandoned as not computationally tractable at that time. Semantic approaches were thought to be the right basis. Now we have found a statistical approach, that is in general very useful, but fraught with potential errors due to the lack of semantic underpinnings.
Hi Gary! Indeed. 'Computing the next word/token' is all that happens, no more, no less. Given that, the hype that accompanies this calculation is mind-boggling. LLMs can't find anything mind-boggling, as an aside, lol - word calculators don't have a mind to start with.
There is no inherent meaning in any sequence/set of symbols - language, math, music, pixels, electronic circuits, chemical formulae, building floor plans... A foundational model trained on such data can't possibly "understand" any of it.