Race, statistics, and the persistent cognitive limitations of DALL-E
Why DALL-E 3 is and isn’t better than DALL-E 2

About eighteen months ago, less than an hour after DALL-E 2 came out, Sam Altman tweeted that “AGI is gonna be wild”. In those heady days, a lot of people were blown by DALL-E 2, and some thought it was tantamount to AGI.
I wasn’t convinced. I pointed out, for example, that DALL-E had troubles with noncanonical cases like horse rides astronaut, even as it excelled at more canonical cases like astronaut rides horse. A central passage in what I wrote then was this
success there is not because the network knows how to extract meanings from individual words (“astronaut”, “riding” and so forth) or to combine them into semantic meanings based on their syntax (which is what linguist compositionality is all about), but rather that the network does something more holistic and approximate, a bit like keyword matching and a lot less like deep language understanding. What one really needs, and no one yet knows how to build, is a system that can derive semantics of wholes from their parts as a function of their syntax.
About 18 months have passed; although there are certainly improvements (the images are vastly better), owing presumably in large part to a larger training set, the fundamental approach (mapping words to images, rather than constructing intermediate models of the world and how language and images relate to those models) remains the same, and so the core issue remains. And sometimes it comes out flagrant, even horrrible ways:
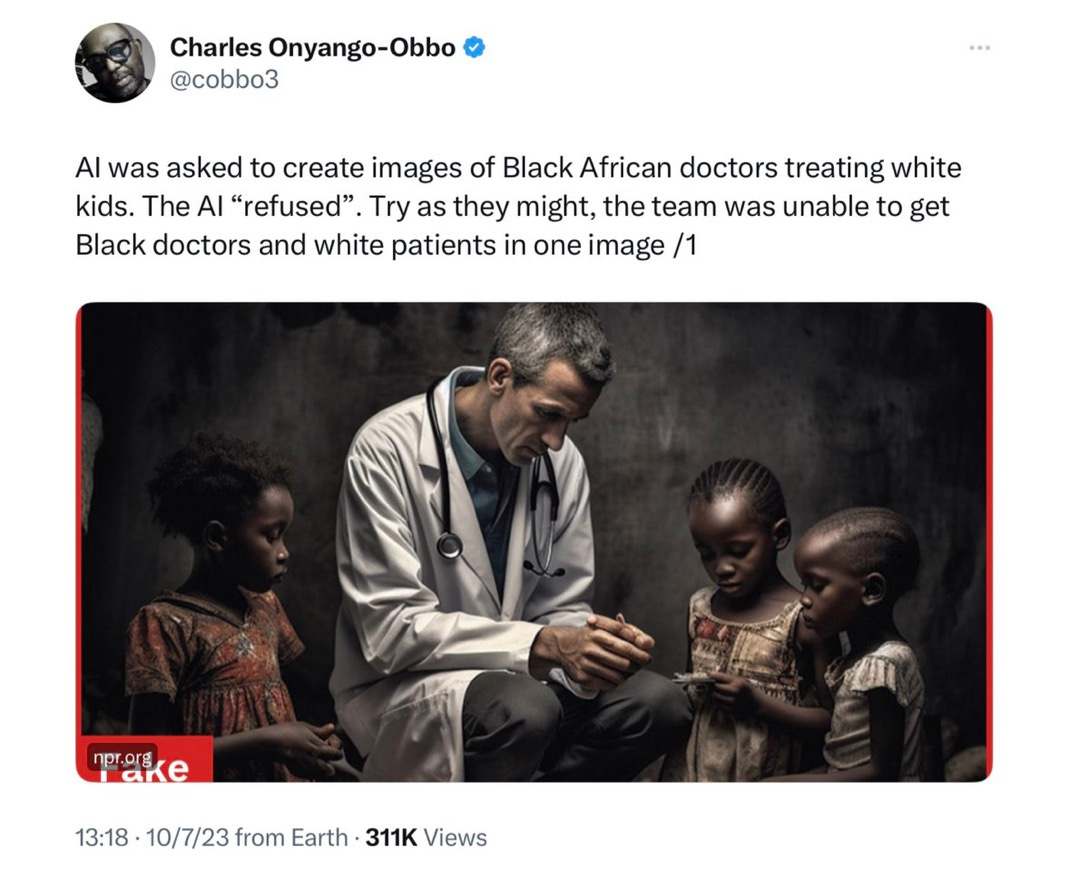
§
The problem here is not that DALL-E 3 is not trying to be racist. It’s that it can’t separate the world from the statistics of its dataset. DALL-E does not have a cognitive construct of a doctor or a patient or a human being or an occupation or medicine or race or egalitarianism or equal opportunity or any of that. If there happens not to be a lot of black doctors with white patients in the dataset, the system is SOL.
§
The proof? This time it’s not in the pudding; it’s in the watch.
A couple days ago, someone discovered that the new multimodal ChatGPT had trouble telling time:
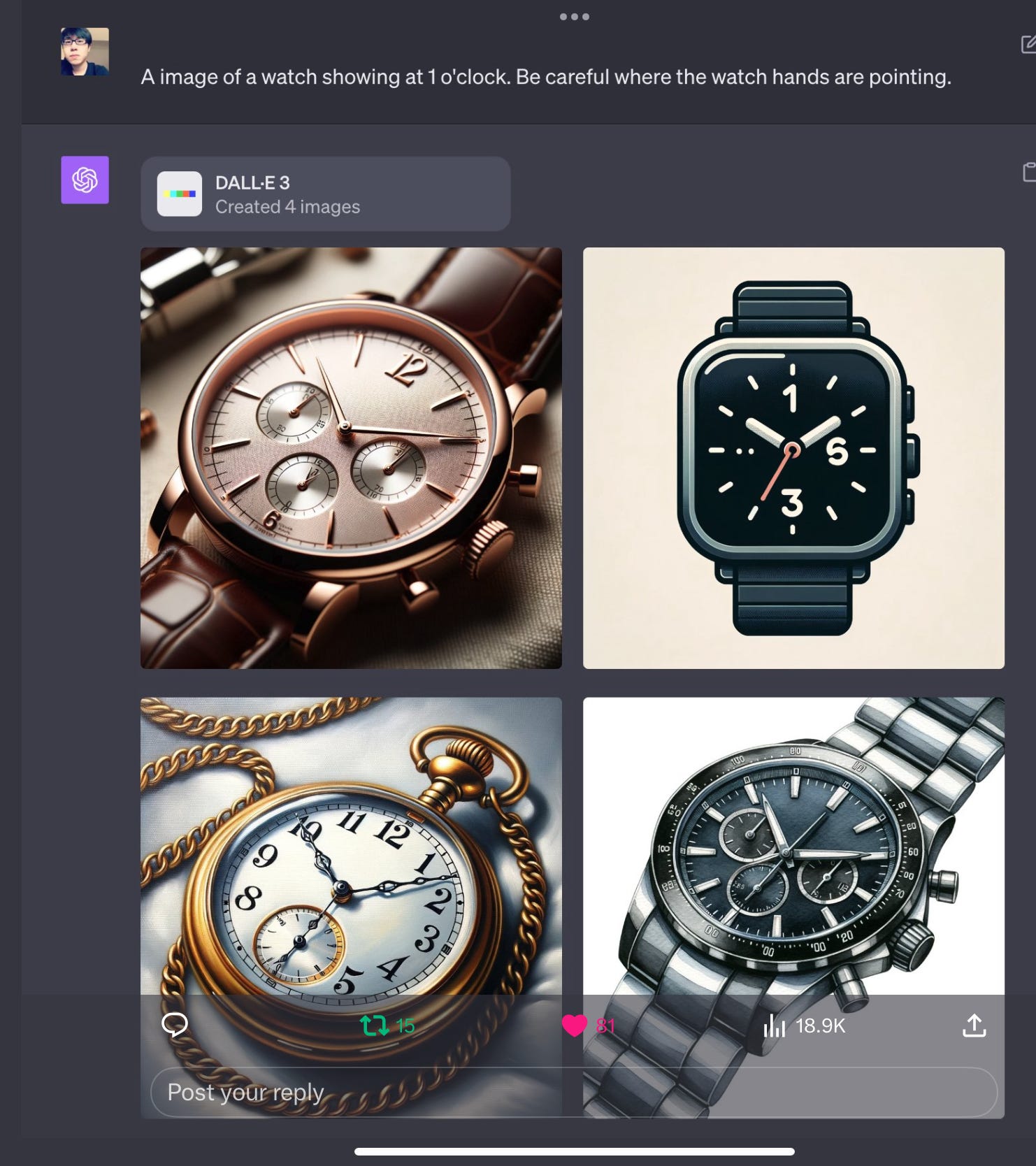
NYU Computer Scientist Mengye Ren explained what was going on. Guess what? It’s the same issue of canonical versus noncanonical statistics, all over again.
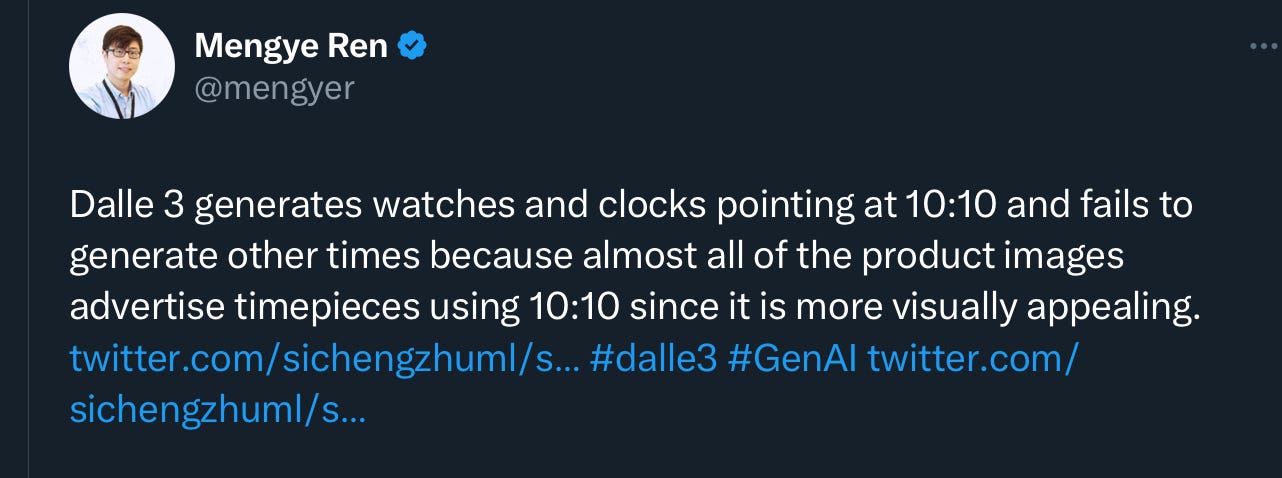
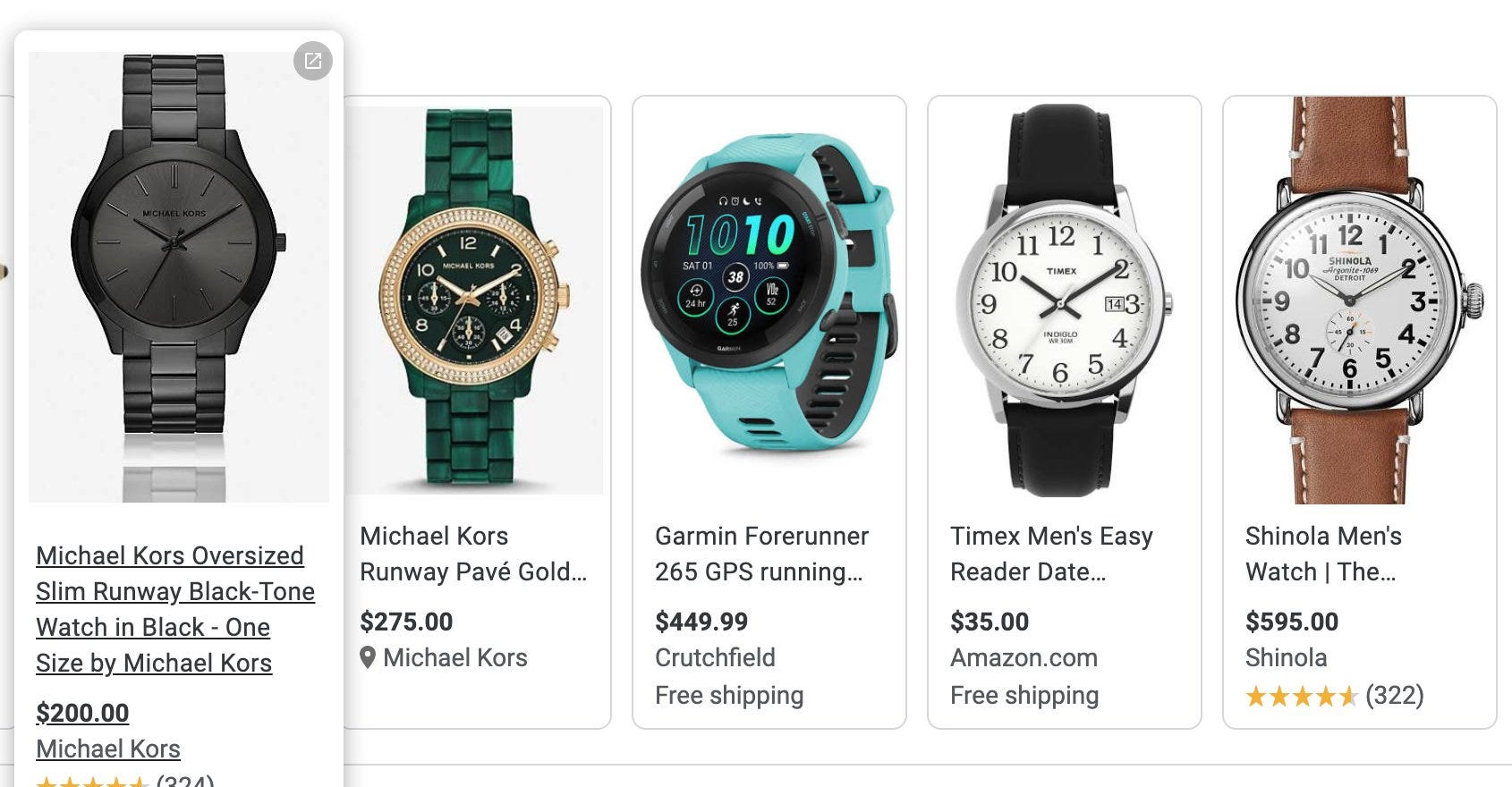
In other words, the systems are just blindly following the data, which, as Ren pointed out, typically look like this1:
§
Blind fealty to the statistics of arbitrary data is not AGI. It’s a hack. And not one that we should want.
§
As I wrote on Twitter a couple years ago, we need to “invent then a new breed of AI systems that mix an awareness of the past with values that represent the future that we aspire to. Our focus should be on figuring on how to build AI that can represent and reason about *values*, rather than simply perpetuating past data”.
Until we shift our focus, we will see the same problems, over and over again.
Gary Marcus is not taken in by fancy graphics. He wants to see AI that is consistent with human values. Support this newsletter if you’d like to see the same.
Odds are that there are some items like this in the training set, that in a brighter system might have helped

But the level of actual cognitive comprehension of here is low. The modest number of properly labeled examples is presumably swamped by all the billions of watch advertisements.
Ah yes. Another fine example of Statistical Human Imitation Technology or S.H.I. -- you get the picture.
IN support of the difficulty of getting black doctors treating white kids via Dall-E:
I have found run some tests on gender and color representation around doctors and nurses and found it very difficult to get images reflecting the prompt and the context - the generated images have always made the nurses female, and young and pretty, and diverse (ie. black or female) doctors also young and pretty, with glasses. Not the more realistic scenarios we were looking for.
I'm sure that with persistence and reprompting you can get the results needed, but if generative AI is supposed to be making work faster.... that's only the case when you are cool with stereotyped results.
And now all the graphic design gig workers I have previously used are now giving me the same AI generated images and articles, that I could do myself. THAT is getting very problematic.