Sora still appears to have trouble with physics
Exactly as I warned in February

In February, the day after Sora came out, I warned that it didn’t really understand physics—and wouldn’t — in essay called Sora’s Surreal Physics:
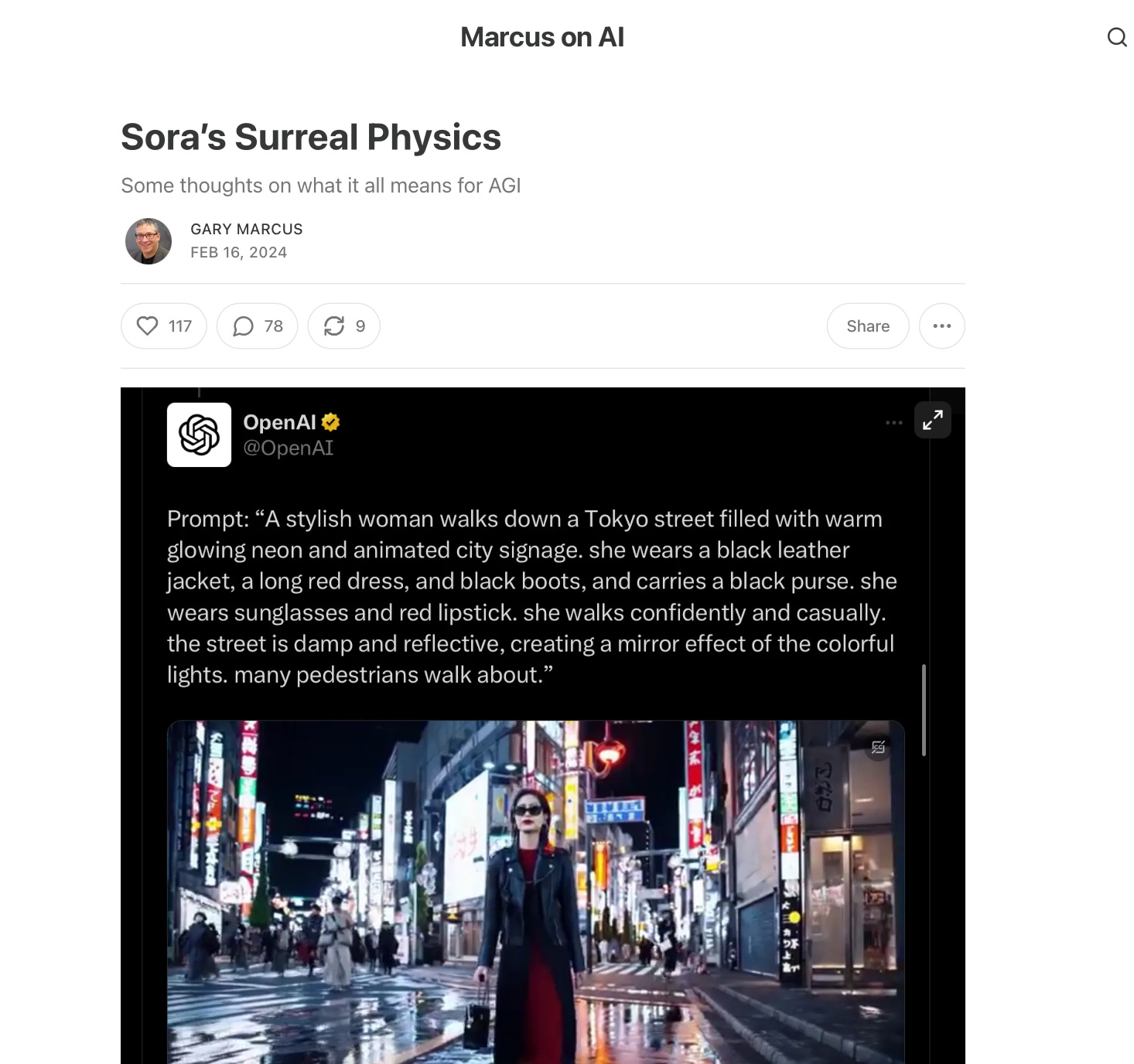
In part it read as follows:
When you actually watch the (small number of available) videos carefully, lots of weirdnesses emerge; things that couldn’t (or probably couldn’t) happen in their real world. Some are mild; others reveal something deeply amiss
and
What really caught my attention though in that video is what happens when the guy in the tan shirt walks behind the guy in the blue shirt and the camera pans around. The tan shirt guy simply disappears! So much for spatiotemporal continuity and object permanence. Per the work of Elizabeth Spelke and Renee Baillargeon, children may be born with object permanence, and certainly have some control it by the age of 4 or 5 months; Sora is never really getting it, even with mountains and mountains of data.
That gross violation of spatiotemporal continuity/failure of object permanence is not a one-off, either; it’s something general. In shows up again in this video of wolf-pups, which wink in an and out of existence.
Looks like these problems linger in a new release of Sora that came out today, per a media report in Mashable of Marques Brownlee’s Sora reviews that comes close to being a perfect echo of my February article:

As I warned in February
More data won’t solve [Sora’s] problem [with physics]. And like other generative AI systems, there is no way to encode (and guarantee) constraints like “be truthful” or “obey the laws of physics”or “don’t just invent (or eliminate) objects”.
Time and money haven’t robustly solved these problems.
The John Locke hypothesis that you can learn physics purely from sense data is failing, over, and over, and over again; this time perhaps (if I had to guess) to the tune of a billion dollars.
Sorry to keep saying I told you so, but well, I did.
Gary Marcus has been emphasizing the importance for AI of richer representations of common sense physics (often with Ernest Davis) for over a decade. He doesn’t quite know when the hype will die, but the problems he has been harping for the last two decades remain quite real.
Hi Gary you were right on!
It is a forever unsolvable problem, using existing approaches alone [that are centered on data, including 'multimodal', 'contrastive']. That's because video will always be an incomplete record of the physical world at large. It's impossible to build a realistic world model using pixels and their text descriptions. Matter behaves on account of its structure (eg a flute with its carefully drilled holes, diffraction grating with microscopic rules, and thousands of other examples), and its interaction with forces (always invisible), under energy fields (also always invisible). What can be gleaned from one video ("this block is catching on fire") is invalidated by another ("wow it's not catching on fire"). Humans learn these via direct physical experiences, not watching videos (alone). If videos by themselves can help form world models, we could shut down every physics, biology, chemistry... lab in the world!
Object permanence artifacts are just a visual annoyance for products like Sora. Unfortunately, the same problem plagues so called self-driving systems. Not much fundamentally changed over the years in this respect. Looking at the display of modern systems, e.g. Tesla, you will often notice pedestrians, cars and trucks appear and disappear into a quantum foam. I call it the Schrödinger's traffic.