

The New Sport of Misrepresenting AI Criticism

AI has undeniably made progress; systems like DALL-E and Stable Diffusion are impressive, surprising, and fun to play with. We can all agree on that.
But can the current state of AI be criticized? A lot of recent media accounts have tried to stick AI critics in a little box. Scientists like the linguist Emily Bender and the computer scientist Melanie Mitchell have rightly pushed back on that. Mitchell, for example, wrote yesterday, and I agree with every word:

What provoked Mitchell’s tweet? In no small part it was (as she acknowledged later) a recent Substack post by the writer and scientist Erik Hoel, “How AI's critics end up serving the AIs”, which claims in its subtitle to be discussing “the obscuring effects of AI criticism”. Needless to say, a lot of people don’t like AI criticism, and the essay has gotten a fair bit of traffic. If you are impressed with current AI and don’t want anyone to spoil your fun, I recommend it.
§
Most of Hoel’s criticism is directed at me. (“I single out Marcus as representative of AI critics everywhere”.)
From the outset, I could tell that the 4,200 word long piece was not going to be fair. In the introduction, for example, Hoel tries to paint me as a dilettante, “Marcus hit on this topic [AI] after searching around for a few different ones over the years, ranging from a nonfiction book on how he learned to play the guitar to his book on evolutionary psychology, Kluge”, entirely neglecting the fact that my 1993 MIT PhD dissertation was on child language acquisition, generalization, and neural networks – which is exactly what I am writing on today, nearly 30 years later. He also neglects my book The Algebraic Mind, a 2001 book that Luis Lamb and Artur Garcez credit as a major inspiration for their own pioneering work on neurosymbolic AI.1 (Yes, it’s true I spent my 2009 sabbatical learning to play guitar, and wrote about it. Sue me.)
After Hoel mangles my biography, he proceeds to mangle my views.
Part of his strategy (common in criticism of those who dare suggest that AI has not been solved) is to accuse me of goal post shifting - without even once actually pointing to a goal post I have shifted. In fact, to the contrary, the only sign he seems to give of what my goal posts allegedly used to be is this excerpt from a passage that I wrote in 2012 for The New Yorker:
[deep learning systems] lack ways of representing causal relationships (such as between diseases and their symptoms), and are likely to face challenges in acquiring abstract ideas like “sibling” or “identical to.” They have no obvious ways of performing logical inferences, and they are also still a long way from integrating abstract knowledge, such as information about what objects are, what they are for, and how they are typically used.
For goodness’ sakes! Does he really think I abandoned those goal posts? Let’s look at the last Substack essay I wrote, um, all of 4 days ago:
The argument I made there is that … systems like DALL-E don’t “understand what wheels are—or what they are for”, because (as I discovered on Sunday) they systematically fail to properly illustrate requests like these:
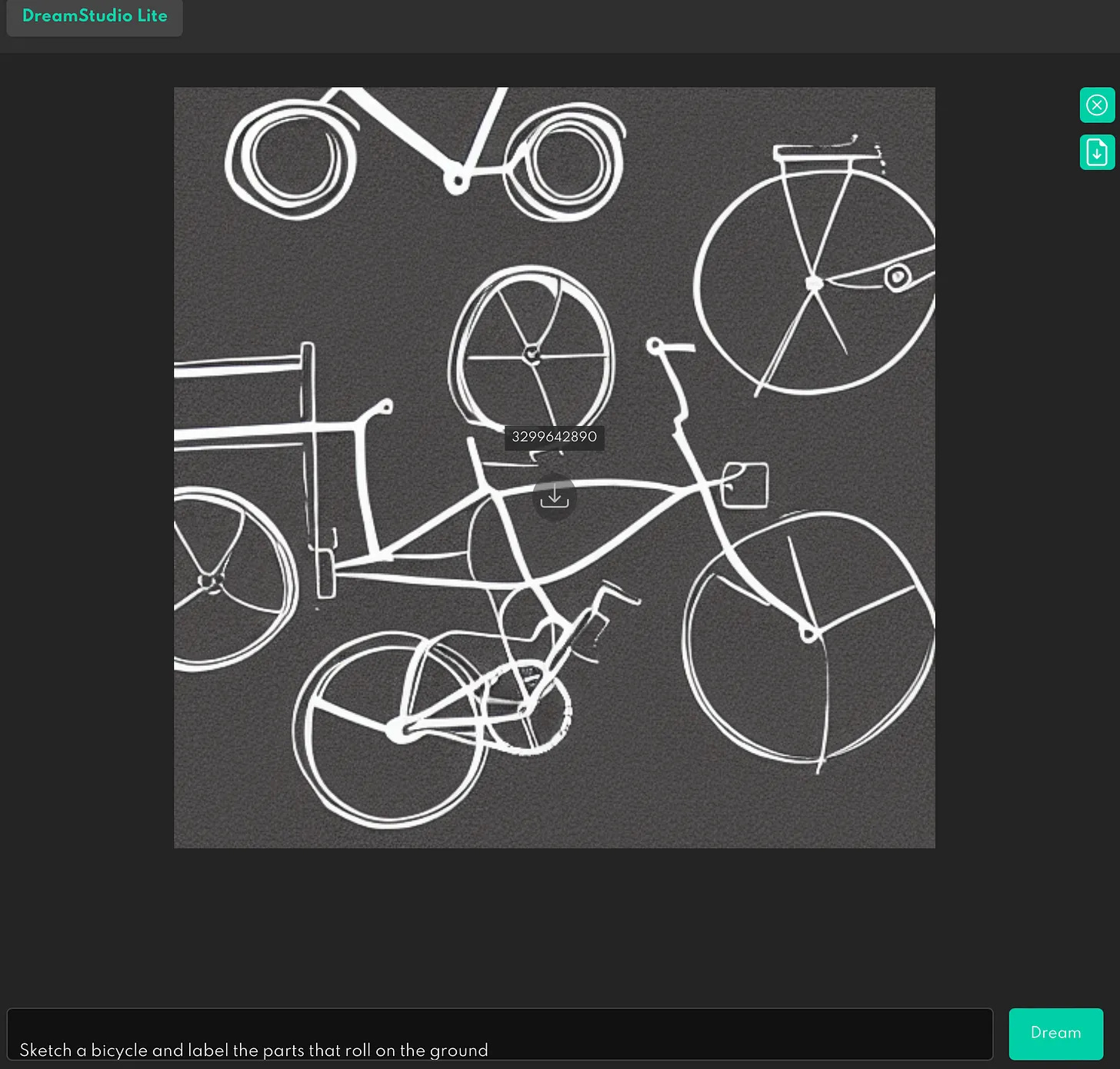
If that’s not an example of exactly what I pointed to a decade ago — an illustration of deep learning systems lacking way of “integrating abstract knowledge, such as information about what objects are, what they are for, and how they are typically used”, I don’t what is. Hoel’s goal-post shifting accusations are absurd.
I stand by the bit about logic too, and highly highly recommend a recent article by Guy van den Broeck’s lab at UCLA that shows that apparently successful performance on logic by neural networks is often driven by unstable statistical contingency, apparently reaffirming the importance of another of my 2012 goal posts. As van den Broeck’s team put it, their results “unveil the fundamental difference between learning to reason and learning to achieve high performance on NLP [natural language processing] benchmarks using statistical features.”
The problem for the neural network community is not that I have changed my goal posts, it’s that my 2012 concerns still stand. (Quite of the few examples that Ernie Davis and I mentioned in Rebooting AI go back a long further, to the 1970s.)
It may be boring to hear about the same challenges over and over, but it’s hard to see how we will get to trustworthy general intelligence until these problems are resolved, in ways that are robust, rather than merely statistically contingent.
§
In the only really substantive part of Hoel’s critique, Hoel tries to make it sound like I think that human beings are the measure of all things, which is something I have never said. In the evaluation of computational models, I have always been careful to distinguish two questions (and would urge the fields of AI and cognitive science to do the same):
Is a particular model sufficient for its engineering purpose (e.g., for reasoning about the physical world)?
Is a particular model a good model of human beings?
Over and over I have stressed that you could have a good model of engineering without being a good model of humans, or vice versa. A good model of the average human’s mathematical abilities would be a lousy calculator, and a good calculator would be a lousy model of the average human’s mathematical prowess.
Hoel tries to pretend that I don’t know the difference. Whereas I often say stuff like this, emphasizing that good engineering does not have to mimic humans:

I did recently ask whether GPT-3 is a good model of a human, but that’s different question, a scientific question about cognitive modeling, rather than a question about how to build AI.
§
The place where Hoel founders mostly deeply, though, is not on my personal biography or intellectual history, but on the question of the relationship between benchmarks and underlying cognitive mechanisms—a bit surprising for someone who is apparently trained as a neuroscientist (though not uncommon in people without scientific training). The heart of Hoel’ss argument boils down to (my words not his) “AI has done better over time on benchmarks so we must be making progress”; in reality, progress can be and often is illusory.
The naive view is that if a system does well on a benchmark that is designed to solve X, the system has actually solved X.
Over and over, the field of AI has discovered otherwise. Guy van den Broeck’s study is a perfect example of this. The Turing Test is another (succeeding or improving on it doesn’t necessarily mean you are intelligent; ELIZA did pretty well, and knew nothing).
§
Most active researchers have by now learned to tell the difference between what a benchmark says on the tin and what it is really getting at; in my Next Decade in AI essay, for example I quoted a team of Facebook AI researchers as saying
"A growing body of evidence shows that state-of-the-art models learn to exploit spurious statistical patterns in datasets... instead of learning meaning in the flexible and generalizable way that humans do."
Hoel is sure that AI has made progress because it has done well on a bunch of benchmarks. But the smart money is still on being cautious about this, and in recognizing that what the Facebook researchers said in 2019 is still the case.
That’s why people like MetaAI’s chief AI scientist Yann LeCun (who deeply disagrees with me about some foundational issues like innateness still thinks AI needs fundamental paradigm shifts and agrees with me that language models aren’t learning enough about the world. Even Geoff Hinton, arguably my staunchest critic, would agree that benchmarks aren’t cutting it, and that too much emphasis on them has stifled innovation:
One big challenge the community faces is that if you want to get a paper published in machine learning now it's got to have a table in it, with all these different data sets across the top, and all these different methods along the side, and your method has to look like the best one. If it doesn’t look like that, it’s hard to get published. I don't think that's encouraging people to think about radically new ideas
Hoel could be smarter than me and LeCun and Hinton and all the rest of us, but a little modesty might not have hurt. Framing concerns as mostly unique to me when they are shared by the likes of LeCun and Hinton is rhetorical nonsense.
Those who wish that AI criticism would go away are welcome to their views, but misrepresenting critics and their views (and obscuring the degree to which even mainstream researchers agree) won’t magically solve the problems AI has yet to solve.
Hoel also seems to know that I went to Hampshire College, but not (though it is a matter of public record) that I was given early admission there (after 10th grade) because I wrote a Latin-English translator, one of my first AI efforts. I suspect that I have been thinking about AI for longer than Hoel appears to have been alive, quite to the contrary of his false and irrelevant accusation of dilettantism.
I find two things interesting about the thinking of AI fanbois (for want of a better word).
1. They are "asymmetrically surprised". When an AI does something amazing and clever, they are rightly excited, but they downplay or ignore the same AI doing something stunningly stupid. Yet errors are surely at least as important as successes, especially if you want to figure out where all this is going.
2. They misunderstand understanding, either underestimating what a general intelligence actually is, or overestimating what can be achieved simply by using larger and larger training datasets. Do they think understanding is just a statistical artefact? Or do they suppose it's an emergent property of a sufficiently large model?
These things interrelate, because if you're not paying attention to the sheer insanity of AI's mistakes, you won't notice that it's not progressing towards general intelligence at all.
Where it's headed is perhaps more like a general *search* capability.
I appreciate the speed of your replies, but there are many confusions here. Symbols precede modern cognitive science by a century; the algorithm that performs Monte Carlo Tree Search uses symbols to track a state in a tree; trees are pretty much the most canonical symbolic structure there is. (Standard neural networks don’t take them as inputs, but a great many symbolic algorithms do). It doesn’t matter when cognitive scientists appeal to MCTS or not; you are conflating cognitive science with a hypothesis and set of tools that are foundational to computer science. And again, it doesn’t matter what AlphaFold 2 *cites*; what matters is that the representations it takes on are handcrafted symbolic representations. Poring through citation lists is not the right way to think about this. Furthermore, I don’t say that “classic models of cognitive science” had any impact on those specific architectures (Alpha* and Google Search) at all; I am not sure where you are even getting that. Again I urge you to separate the engineering question from the cognitive modeling question. Here I was talking about the engineering questions, I said that these systems are hybrids of deep learning and symbols. (You are also wrong on Google Search; as far I know, they now use LLMs as one cue among many). You are also playing games by switching between current foundation models (somewhat narrow) and neural networks in general (neurosymbolic is older than foundation models and open to a variety of neural approaches); and certainly google has been using neural networks as a component in search since at least 2016. (And Google Search, the most economically successful piece of AI history, has used symbols from the beginning; PageRank, for example, is a symbolic algorithm).