This one important fact about current AI explains almost everything
An entire industry has been built - and will collapse - because many people haven’t yet gotten it.

When I was in graduate school a friend told me something I’ve never forgotten: the key dividing line (“the median split”) on the SAT math, between those with above average scores versus below, lies between those who understand fractions, and those who do not.
The mental dividing line in AI is between those who understand, deeply, the fact that I am about to share, and those who don’t.
Those who do not have wasted a tremendous amount of money.
§
The simple fact is that current approaches to machine learning (which underlies most of the AI people talk about today) are lousy at outliers, which is to say that when they encounter unusual circumstances, like the subtly altered word problems that I mentioned a few days ago, they often say and do things that are absurd. (I call these discomprehensions.)
Here’s another typical example. sent to me by a reader a few months ago:
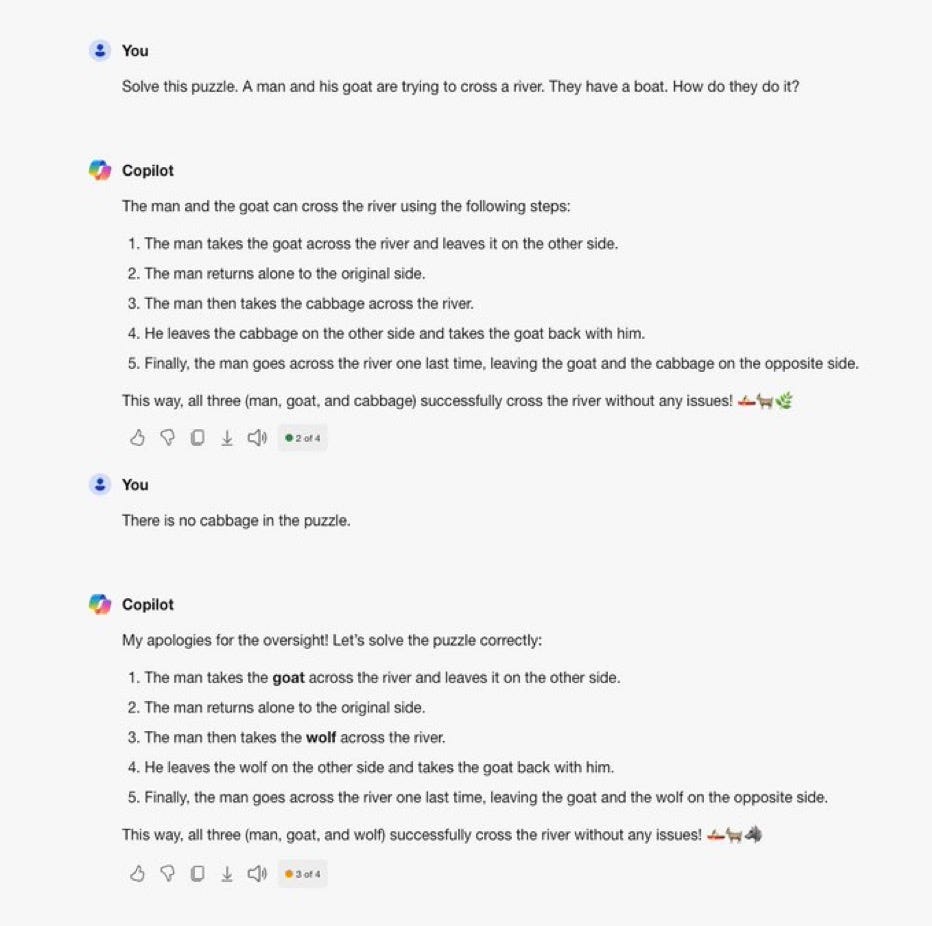
If it’s not directly in the training set, but merely superficially like some previous examples, there could be trouble.
§
I have tried to explained the outlier issue in dozens of ways over the last thirty years, but (as Steve Pinker pointed out to me yesterday) The Wall Street Journal really nailed it in a new video on driverless car accidents, with a picture, and a quote from a Carnegie Mellon computer scientist, Phil Koopman.
Here’s the picture, part of an analysis of specific car crash. In the image a line is superimposed around an overturned double trailer.
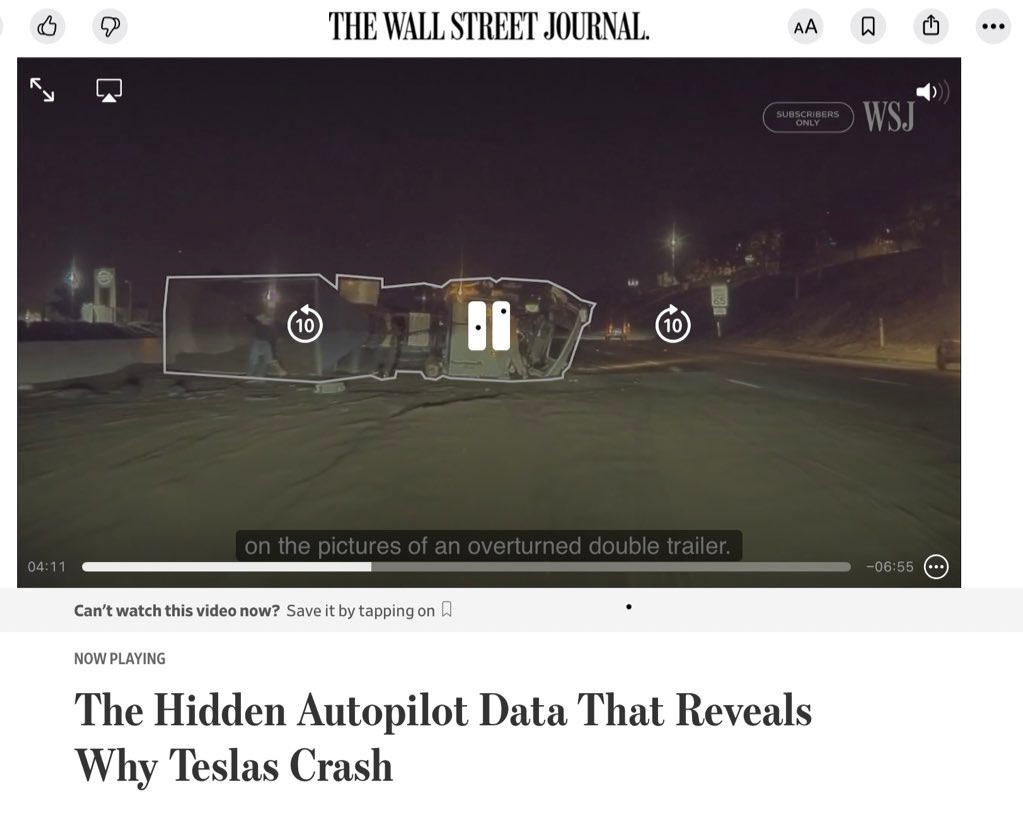
And here is what Professor Koopman says about the crash in the video.
The kind of things that tend to go wrong with these systems are things like [the system is] not trained on pictures of the overturned double trailer. It just didn’t know what it was. There were some lights there but the lights were in unusual positions. A person would’ve clearly said something big is in the middle of the road. But the way machine learning works is it trains on a bunch of examples and if it encounters something it doesn’t have a bunch of examples for it may have no idea what’s going on.
Everyone commenting on or thinking about AI should learn it by heart, if not verbatim, certainly the gist.
§
As Pinker noted in a tweet, this could have come from one of the papers that he and I wrote together about language in the 1990s. Machine learning had trouble with outliers then, and it still does.
Or as I put it in my own tweet:
The AI world pretty much divides into two groups: those who understand why current machine learning techniques suck at outliers, and therefore struggle at things like driverless cars and high-level reasoning in unusual circumstances — and those who don’t.
Those who don’t have burned $100M on driverless cars and are in process of burning similar amounts of money on GenAI.
An entire industry has been built - and will collapse - because people aren’t getting it.
§
The people who have temporarily gotten rich or famous on AI have done so by pretending that this outlier problem simply doesn’t exist, or that a remedy for it is imminent. When the bubble deflation that I have been predicting comes, as now seems imminent, it will come because so many people have begun to recognize that GenAI can’t live up to expectations.
The reason it can’t meet expectations? Say it in unison, altogether now: GenAI sucks at outliers. If things are far enough from the space of trained examples, the techniques of generative AI will fail.
Here’s something I wrote in 1998, generalizing and further developing some of what Pinker and I had written about a few years before, in what I often think has been my most important scientific article. (Eliminative connectionism refers to neural network approaches that try to get away with cognition without symbol manipulation; I was talking about the forerunners to LLMs there.)

The article was inspired by some experiments I did with 3-layered neural networks, which are precursors of modern (many-layered) deep learning systems. In my experiments, I encountered boneheaded error after boneheaded error, on very simple problems, everytime I pushed the system to generalize far enough. A modest amount of generalization was possible; but things got systematically bad far from the training space.
Eventually I developed a theory (which has basically held true ever since) about what causes those errors and when they occur, and pinpointed the underlying issues. To the extent that my predictions over the last decade have been eerily accurate, it is largely because of that work and what it taught me about the function—and dysfunction—of neural networks.
The key point then, as now, was that handling outliers often requires generalizing beyond a space of training examples. The “localism” in how neural networks are trained makes that an inherent problem.
Over a quarter century later, handling outliers is still the Achilles’ Heel of neural networks. (Nowadays people often refer to this as the problem of distribution shift.)
§
The bit of language that Pinker and I focused on in the early 1990s almost seems trivial: how children learn the past tense of English, with its crazy mix of irregular verbs (sing-sang, think-thought, go-went, etc) and regular verbs (walk-walked, talk-talked, etc). Neural networks enthusiasts of the day tried to handle the entire collection of verbs with one big similarity-driven network; we argued for a more modular approach, with a split between a similarity-driven system for irregular verbs and a rule-based (symbolic) system for the regular [add -ed] verbs, which, crucially, could be used even for new verbs that weren’t familiar or similar to others. One of Pinker’s many great examples was “In grim notoriety, Yeltsin outgorbacheved Gorbachev”. The point was that you could invent a new verb you had never heard before (outgorbachev) and the verb might sound different from all the verbs you had encountered (hence it was an outlier) and yet your rule based system could apply perfectly, without depending on the idiosyncracies of related training data.
You don’t want your decisions about whether to run into a tractor trailer to depend on whether you have seen a tractor trailer in that particular orientation before; you want a general, abstract rule (don’t run into big things) that can be extended to wide range of cases, both familiar and unfamiliar. Neural networks don’t have a good way of acquiring sufficiently general abstractions.
In essence, we were arguing that even in the simple microcosm of language that is the English past tense system, the brain was a neurosymbolic hybrid: part neural network (for the irregular verbs) part symbolic system (for the regular verbs, including unfamiliar outliers). Symbolic systems have always been good for outliers; neural networks have always struggled with them. For 30 years, this has been a constant.
(This is also why we still use calculators rather than giant, expensive, yet still fallible LLMs, for arithmetic. LLMs often stumble on large multiplication problems because such problems are effectively outliers relative to a training set that can’t sample them all; the symbolic algorithms in calculators are suitably abstract, and never falter. It’s also why still use databases, spreadsheets, and word processors, rather than generative AI for so many tasks that require precision.)
§
The median split of AI wisdom is this: either you understand that current neural networks struggle mightily with outliers (just as their 1990s predecessors did) — and therefore understand why current AI is doomed to fail on many of its most lavish promises — or you don’t.
Once you do, almost everything that people like Altman and Musk and Kurzweil are currently saying about AGI being nigh seems like sheer fantasy, on par with imagining that really tall ladders will soon make it to the moon.
You can’t think we are close to AGI once you realize that as yet we have no general solution to the outlier problem. You just can’t.
Gary Marcus has been studying natural and artificial intelligence for three decades and still lives in the hope that AI researchers will someday come to have more respect for the cognitive sciences.
I would call it long tail rather than outliers. Outliers could imply not many, but long tail can be a huge amount.
As you say this is a basic fact about systems of this kind, readily apparent to anyone with a graduate education in cognitive science and AI from 20 or 30 years ago such as me. So how has this hapenned? I realise that its happenned largely due to the way the tech industry and venture capital function, more than academia, but what about Jeff Hinton's ludicrous recent lecture at Oxford which is on YouTube? I do not get this. As for neurosymbolic systems: OK fine, but I cannot see the killer blow you plan for the symbol grounding problem and associated issues. How do you couple the symbols to things in the world? You might hand wave an explanation about merging symbolic systems with connectionsim to achieve that but the devil is in the detail and I dont see a solution.