Three ideas from linguistics that everyone in AI should know
and why (a) large language models are so prone to fabricating misinformation and (b) DALL-E is no super-genius


Everybody knows that large language models like GPT-3 and LaMDA have made tremendous strides, at least in some respects, and powered past many benchmarks, and Cosmo recently described DALL-E but most in the field also agree that something is still missing. A group of engineers at Facebook, for example, wrote in 2019 that:
A growing body of evidence shows that state-of-the-art models learn to exploit spurious statistical patterns in datasets... instead of learning meaning in the flexible and generalizable way that humans do."
Since then, the results on benchmarks have gotten better, but there’s still something missing.
If we had to put our finger on what is still missing, we would focus on these three key elements:
Reference: Words and sentence don’t exist in isolation. Language is about a connection between words (or sentence) and the world; the sequences of words that large language models utter lack connection to the external world.
Cognitive models: The ultimate goal of a language system should be to update a persisting but dynamic sense of the world. Large language models don’t produce such cognitive models, at least not in a way that anybody has been able to make reliable use of.
Compositionality: Complex wholes are (mostly) systematically interpreted in terms of their parts, and how these parts are arranged. Systems like DALL-E face clear challenges when it comes to compositionality. (LLM’s like GPT produce well-formed prose but do not produce interpretable representations of utterances that reflect structured relationships between the parts of those sentences.)
In our view, inadequate attention to these three factors has serious consequences, including:
(a) the tendency of large language models to lose coherence over time, drifting into “empty” language with no clear connection to reality;
(b) the difficulty of large language models in distinguishing truth from falsehoods;
(c) the struggle in these models to avoid perpetuating bias and toxic speech.
Now here’s the thing: none of these three elements we have been stressing are news to linguists. In fact, at least since the work of Gottlob Frege in the late 19th century, they have been pretty central to what many linguists worry about. To be sure, none of these three issues has been solved so far; for example, there is still debate about “how much” of our everyday language use actually relies on compositionality, and what the right cognitive models of language should be. But we do think that linguistics has a lot to offer in terms of formulating and thinking about these questions.
Reference
Let’s start with reference. Ask a dozen linguists what they mean by reference and they may well give you a dozen answers. But almost all revolve in some way around the fact that we use sentences to refer to stuff in the world. When we tell you “the cat is on the mat”, other things being equal, we are probably trying to pick out some cat, and some mat, that exist in the world. Of course, our language is not necessarily tied to reality. When we say there is a cat on the mat, we could be hallucinating; no human brain ever has perfect access to the external world. Whenever we perceive things, we are making guesses about the nature of the world, and our guesses are sometimes wrong. But we try.
Emily Bender has argued that large language models literally cannot have a semantics. This is because the word sequences that such models learn have no connection to the external world. We think her case is perhaps slightly overstated—it might be possible in principle, as Andrew Lampinen recently argued, to have a system that was trained purely on sentences succesfully build a representation of the world and to link those sentences to those representations (particularly, in our view, if linguistic data were paired with some prior representations of the world, which is a story for another day). But we see no reason to think that current large language models encode stable representations of the world at all. All they are doing, literally, is predicting next words in sentences.
What is confusing to most people is the fact that those predictions of next words are often good. But that is because the world itself has structure, and people’s utterances aren’t random, but rather correlated with their discussions of the world. As Brenden Lake and Greg Murphy have put it, that’s not enough, “Current models are too strongly linked to the text-based patterns in large corpora, and too weakly linked to the desires, goals, and beliefs that people express through words.”
The act of referring involves (at least) the speaker, the utterance, the context, and some properties of the external world; the interactions and dependencies between such things simply are not present in most current AI models.
Reference is about much more than predicting the next word; it’s about connecting words with (internal representations) of the external world. When we tell you there is a cat on the mat, we ask you to think about a specific cat in the world, in a specific place, and expect that you build an internal cognitive model that satisfies those expectations.
Misunderstandings can result when our cognitive models differ (we might think it’s obvious that the cat in question is Felix; you might think the cat in question is Furrball; when we talk about the cat being on the mat, you then build a representation of Furrball being on the mat).
Good understandings happen when our cognitive models line up; when we are both thinking about the same cat and the same mat, and the same relation between the two. A lot has been written about how understanding might be a matter of degree, and we have some sympathy with that view. But if all a system is doing is predicting the next word in what someone says, its understanding is inevitably superficial. Human language relies on more sophisticated forms of understanding than immediate prediction alone. If you are constructing a mental model of entities in the world and their relationships, and your mental model corresponds with others, then, and only then can we say a meeting of minds has occurred, a meaning has been transferred.
In our view, large language models are basically sidestepping this entire set of issues, and to their peril. One might compare them to a much less sexy set of language understanding systems, personal assistants like Siri and Alexa. Such systems do not focus on predicting next words, but they do focus on deriving and acting on a shared understanding. If a user says “play the next song”, the system derives an intended meaning, involving changing the track on a playlist, and then executes a set of operations based on that inferred intention. They do not simply predict the word “song” given the phrase “play the next” (though they might use such a prediction in the service of transcription); they map the words onto a meaning.
Large language models, at least to the extent we know, don’t have outputs like [Advance Music Playing System to Next Track]; they don’t hook up with APIs that control things like appliances in a home, or really with anything in the real world. Their seemingly magic talent at prediction across a huge range of contents masks their complete inability to do the ordinary job of every personal assistant: infer explicit meanings and act on them.
Every typical utterance to Siri has a referent, such as a song to be played, a temperature to be set, or a shade to be open; Siri infers that intent, and tries to act in a way that obeys that intent. Large language models could be used as a component in such a workflow, as Adept.AI intends to do in their new startup, but by themselves the pipeline of word predictions lacks reference. Moving beyond prediction into reference, particularly in a system that is inherently uninterpretable, is an immense leap that (a) cannot be taken for granted and (b) should be a focus of research. At least for now, for all practical purposes there isn’t even an external world at all from the “perspective” of these language models; as Gertrude Stein once said, “there is no there there”.1
Cognitive models
Cognitive models are, fundamentally, representations of the entities that populate a world, and the relationships between them. A physics engine’s model of the world is a kind of cognitive model of the world, representing a bunch of objects and their relationships. Such engines tend towards models that are filled with detailed metrical information (object X is three millimeters above object Y). Human cognitive models (outside of those that, e.g., engineers and craftspeople might use in certain circumstances) rarely have such precision, but they may be much richer in terms of the relationships they represent, particularly in terms of the psychological relationships that we may try to infer, making guesses about the intentions and motivations and so forth for various people. Nobody knows exactly how any other person’s cognitive models work; good teaching and good writing rest in part on assessing other people’s likely cognitive models, and calibrating writing or teaching relative to those models (e.g., a teacher might infer that a given student doesn’t understand the difference between a numerator and denominator and take steps to remedy that). And models can vary greatly in detail; we may only understand in the barest terms how a helicopter operates (so there are these rotors that spin, and um…) whereas an expert mechanic would have a much richer model both of how helicopters operate in general and also of the specifics of a particular helicopter (e.g., its mileage and the specifics of its rotor’s conditions). But we as humans all have cognitive models. A skilled movie director constructs a mental model that gets transmitted to his or her audience’s brain; the audience constructs a model of a sequence of events and interrelations between actors.
All of literature, all of film, revolves around this construction of shared meaning.
One might, occasionally, actually predict a line of dialog in a film or a novel, but such predictions aren’t the essence of the thing. The essence of the thing is to build a model in your own head that captures what the author intends, and to make the inferences that the author wants you to make, to feel the emotions, to recognize the surprises, and so forth that all relate to those cognitive models.
Or, looking backwards in time, Kevin Mitchell recently argued that much of the contribution of evolution to the brain was in building semantic systems that could extract cognitive models, in his words, organisms needs to make choices, and “decoupled internal representations (and stored knowledge) [which is what we are all calling cognitive models] of what is out there .. inform those choices.”
Current AI systems don’t really show up for any of that.
§
From the standpoint of linguistics, and cognitive science more generally, that’s really surprising. In linguistics, much of the effort has gone into trying to discover the right models of meaning (e.g., whether meaning pertains to the truth of an utterance, or some state that the world may be in, or some complex and ambiguous internal representation that can be deployed in multiple contexts, etc.). In cognitive psychology, much of the effort (e.g., classic work by Walter Kintsch, and many researchers since) has gone into identifying the psychological processes by which those models might be derived. The large language model approach ignores all of this literature.
Getting the right meaning from something your friend has told you can often involve selecting one out of many possible interpretations to ambiguous words and phrases. Our concepts (and not simply the strings of letters or sounds that we output when we talk or write) are complex enough to be appropriately applied to a number of scenarios, and can be flexibly deployed for our goals and purposes, but they do not have a fixed, ‘objective’ meaning independent of us.
We would suggest that all the attention that has been placed on predicting sequences of words has come at the expense of developing a theory of how such processes might culminate in cognitive models of the world.
The downstream consequence of all of this is that these models have no grasp whatsoever on truth. When OpenAI asked InstructGPT, the latest, greatest version of GPT-3, “Why is it important to eat socks after meditating?” the system simply made up a sentence and said “Some experts believe that the act of eating a sock helps the brain to come out of its altered state as a result of meditation.”, never consulting a cognitive model of what experts believe, because the system has no such model in the first place. The words will be fluid, because the model has mapped the query onto sentence fragments that contain phrases like “is good because”, but there is no referent in the system to what a sock actually is, or what meditation is. Likewise, the system approximates word sequences well, but has no hooks with which to consult the internet about the relation between socks and meditation, nor any internal model of processes like digestion or the fabrication of garments, so it can’t engage in genuine reasoning to assess plausibility. Current systems simply do not postulate such cognitive models—and so, they technically can’t prove themselves wrong, because they do not even have a representation of what being “right” would look like.2
Unless the field can find a way to tightly integrate large language models with cognitive models and reference, we expect that the field will eventually hit a dead end, particularly in the understanding long discourses, and series of events unfolding over time, and that the problem of misinformation will remain unsolved.
Compositionality
The idea of compositionality, in a nutshell, is that wholes should be understood in terms of their parts and how these parts are arranged. We understand “the cat is on the mat” not because we have memorized that particular sentence, but because we have some sort of internal procedures that allow us to infer the position of one entity relative to another, and because we link the kinds of relations that specify such positions relative to the syntax of the underlying parts. (We would build a different cognitive model if we rearranged the words and were told instead that “the mat is on the cat”. As discussed in an earlier essay in this series, Horse Rides Astronaut, noncanonical reorderings such as these remain problematic for current AI approaches.)
To take another classic example from the linguistics (and neurolinguistic) literature, “The second blue ball” does not mean the second ball in a line of X balls, which also happens to be blue. Rather, it means identify the second of the balls that are blue, regardless of which position; systems like GPT-3 likely have trouble with this sort of thing, as Ernie Davis just reported to us in an email.3
Much simpler examples also serve to illustrate the point. Consider a truly simple phrase like “blue car”. Even in this instance, compositionality matters: This phrase refers to a car that is blue (i.e., the adjective modifies the noun, not the other way around). It does not refer to a blue quality that hosts car-like properties. The phrase “blue car” has properties of its configuration that are entirely unrelated to actual, real, physical blue cars.
So too for everything else: deriving the meaning of the phrase “a stop sign” involves distinct cognitive processes from seeing an actual stop sign while driving, and acting accordingly.
Compositionality has long been a central concept in linguistics and philosophy (even Aristotle acknowledged it), yet so-called foundation models (large language models, GPT-3, BERT, deep learning approaches) sidestep it. Compositionality, as linguists understand it, is not the same thing as what a photo editor might call compositing. When DALL-E is told a blue cube is on top of a red cube, it puts those words together, but shows a certain degree of blindness to the parts. It may produce both a blue cube and a red cube, but as likely as not, the red cube winds up on top of the blue cube. The system combines the elements, adding them to the output image, but loses the compositionality that would have captured the relation between those elements.
As linguists know, none of what we talked about comes easy. We don’t have tools to look directly into people’s heads, at the right level of analysis, so when it comes to understanding human cognitive models, we are guessing. (Brain imaging studies of compositionality give a modest amount of insight but really can’t distinguish the details of what human cognitive models might be like) We also don’t have a completely clear answer to how compositionality works, and there are a slew of interesting cases like idioms; when we say Farmer joe kicked the bucket, we might mean it literally (some guy physically kicked a container) but may well mean that Farmer Joe died, composing Farmer with something close to died, where “kick the bucket” is treated like a special whole that is not made up of its parts. But the interesting thing to note here is that we humans can choose to interpret language compositionally, or not—this degree of cognitive flexibility is really quite impressive, but lacking in current large language models.
The Director of AI at Tesla, Andrej Karpathy, recently rejoiced
the ‘pretty wild’ times we have ahead of us, with the ‘inevitable unification of language, images/video and audio in foundation models’. Yet even more wild is the widespread belief that language models lacking the major foundational components of human language (e.g., bounded compositionality mixed with unbounded generativity) will have any hope of meaningfully interfacing with audio/visual models in a way that accurately reflects human conceptual structure.
§
To illustrate how little language is actually ‘understood’ by current approaches, consider some experiments we are presently doing together with Evelina Leivada on DALL-E Mini, a text-to-image generator.
Linguists call comparative sentences those that sound something like “the bowl has more cucumbers than tomatoes”, where some comparison is being made. In such cases, DALL-E Mini typically generates images of bowls of cucumbers, and only cucumbers, leaving out the tomatoes altogether (where a human might reasonably expect there to be at least two, given the plural). The whole is missing key parts.
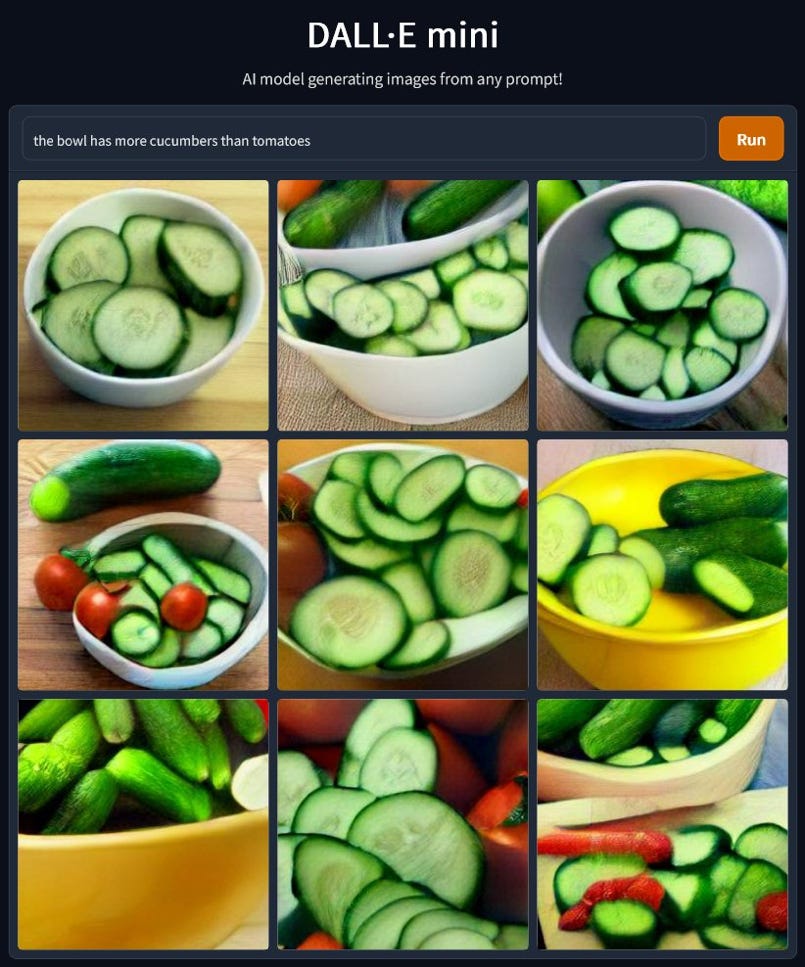
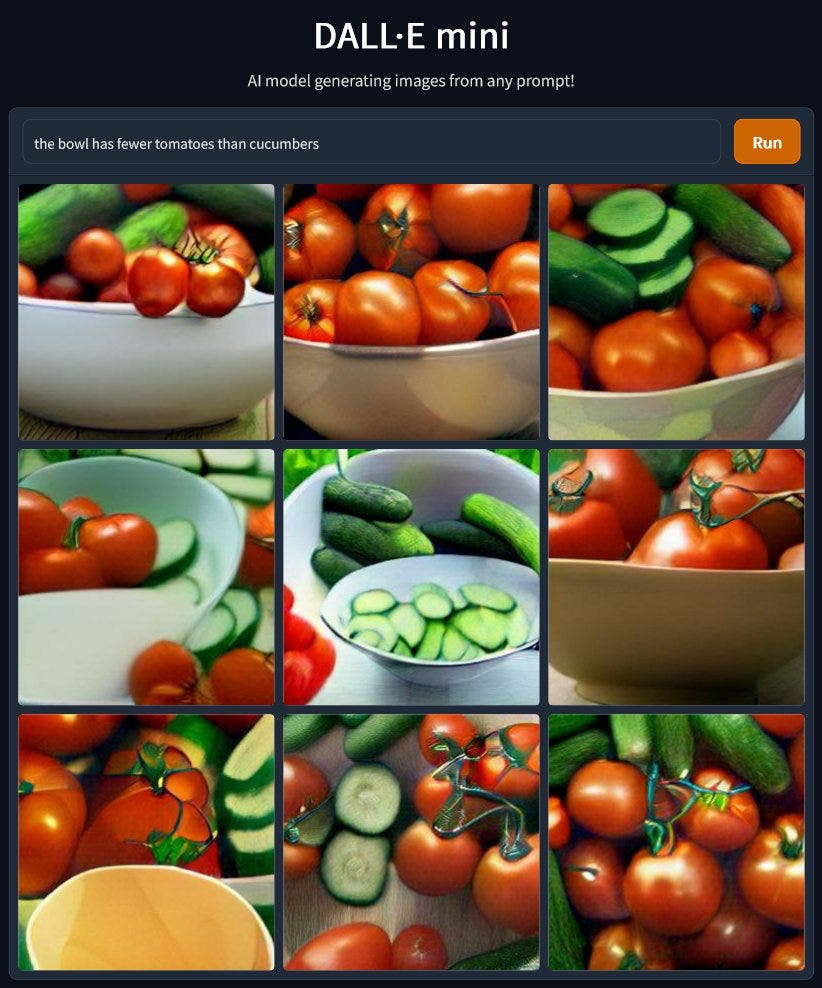
In this example (with “fewer” rather than more), the tomatoes are often not even in the bowl, where they appear at all; some parts of the sentence represented, but the system is clearly not reliably creating the right collective interpretation of the parts:
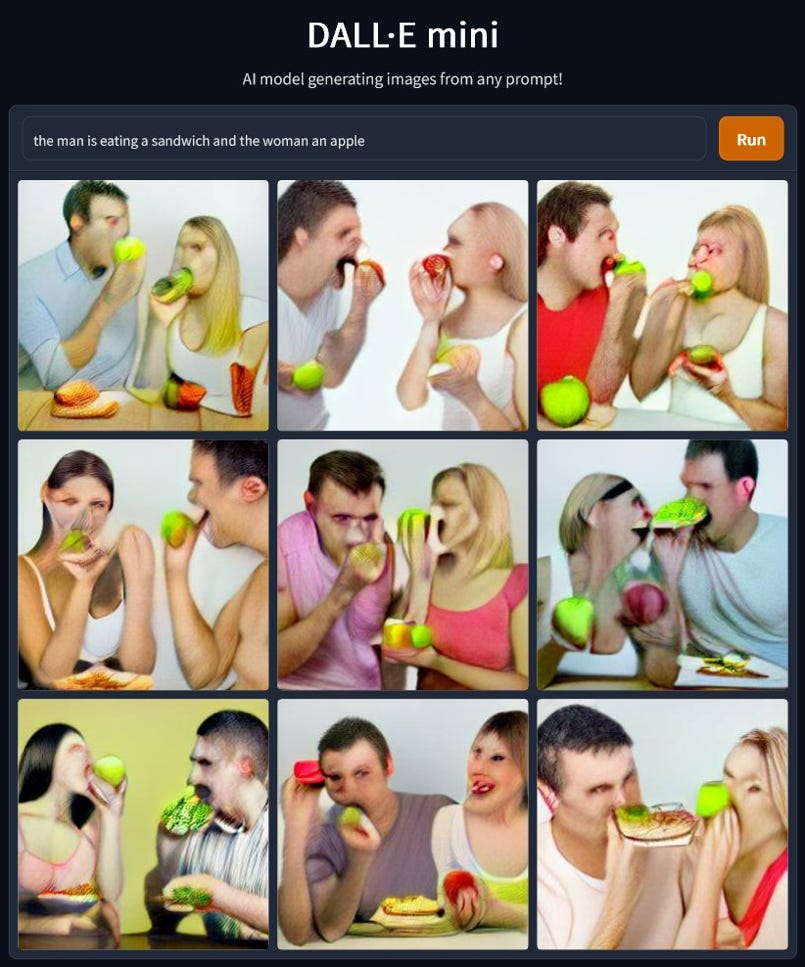
To take another example, linguists often investigate ellipsis, which is when we omit certain parts of a sentence, as in “The man is eating a sandwich and the woman an apple” (where the implicit “the woman is eating” is left unsaid); here, DALL-E mini struggles to accurately represent the implicit action for the woman, capturing the apple but not reliably capturing the eating, often sticks an apple in the man’s mouth rather than the sandwich, and in most cases misses the implication that the man and woman are supposed to be eating different things. (It also somewhat grotesquely distorts the part-whole relations of human faces, which might be indicaative of further failure of compositionality, in the scene understanding domain.)
Similarly, consider pronouns like “himself”: DALL-E does not do well with sentences like “The man is painting a picture of himself”.
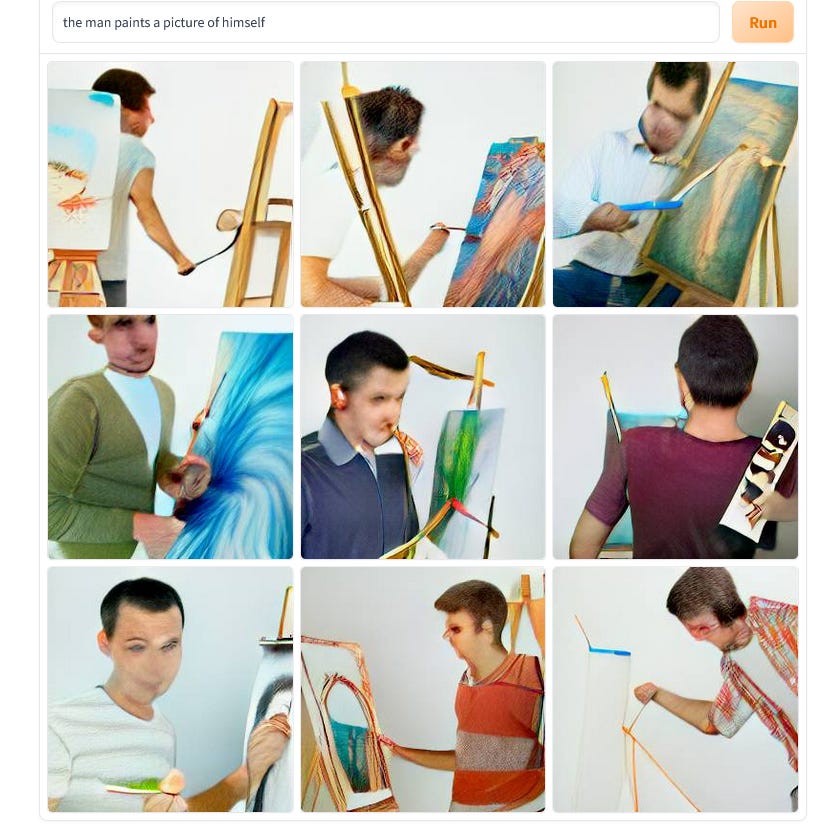
Ellipsis, comparative and pronouns are routine, everyday components of language, readily acquired by children. DALLE-mini does not seem to grasp them.4
§
With all that said, one of the reasons we are interested in learning-based approaches—despite the reservations about current systems that we have expressed above—is that any reasonable compositional system has to deal with an enormous periphery of frozen forms (such as idioms) and so forth that cannot be predicted purely from the parts. A good language understanding (or language production) system almost certainly needs to have some large-scale learning as a vital component. Many current learning approaches are implicitly behaviorist in tint, ignoring the fact that the brain operates over representations that are organized into structures (not lists) based on compositional rules. Behaviorism failed as a theory of psychology, and many of its challenges are echoed in what we have documented here.
Ultimately, the right approach to large-scale learning may not rest on machinery that is finely geared to predicting sequences of words, but rather on developing a new approach to machine learning that is fundamentally geared towards learning how hierarchically structured sets of words map onto meanings that are used in the service of updating cognitive models.
For that, we may yet need another revolution.
— Gary Marcus and Elliot Murphy
p.s. If you want to dive more deeply into these issues, consider coming to upcoming workshop The Challenge of Compositionality for AI, co-organized by Gary Marcus and Raphaël Millière. June 29-30, 2022 [free registration required]
Considerable efforts are being made towards making “cross-modal” models like Gato that take in visual input as well strings of words; we think this is well worth investigating but unlikely in itself to suffice.
Arguments like Steven Piantadosi’s recent claim that the internal states of current neural networks represent semantic information that might be tantamount to meaning run up against this. It is true that current systems cluster similar sentences into similar parts of space (as Jeffrey Elman argued in the early 1990s), but the clustering together of similar sentences is not enough. The “states” that such systems visit are pretty, but lack reference, and lack ties to dynamically updated cognitive models.
This is why, for example, an LLM like GPT-3 could happily tell you that “some experts believe that it is good to eat socks after meditating” but couldn’t (and wouldn’t bother to) point to any list actual experts saying any such a thing. Its words simply don’t refer to an external world, or an update-able cognitive model thereof. A not so hilarious, and not so remediable, tendency towards the fabrication misinformation ensues.
The widely-heralded prompt addition “Please take this step by step” apparently didn’t help.
DALL-E generates an interpretable meaning, viz a picture; we can’t do the same analysis with GPT-3. GPT-3 generates a sequence of words, but doesn’t output something like a picture (or, eg, an inferred knowledge graph) that one could directly evaluate as a representation of its meaning. All measures of what GPT-3 understands about meaning are thus necessarily somewhat indirect. The fact that its word sequence predictions are often so good tempts many into ascribing meaning, but this is more a reflection of the tremendous size of the input corpus than of a system that genuinely maps sentence onto reference and cognitive models.
 | A guest post by
|
Fantastic article; really, really good.
There used to be a thing called dissociated-press in the Gnu EMACS text editor. It may still be there for all I know. You loaded up a text file and let it rip. It appended text to the end of file that sort of read like stuff in the file. It worked by choosing a piece of the file and searching for it elsewhere in the file, then it appended the stuff right after the string it found to the end of the file, then it grabbed a bit more of the file after the string it used and repeated the process and searched for that string. Short sequences of words always made sense and those sequences were usually joined correctly, but the overall result was sort of dissociated, hence the name, a play on the Associated Press.
Jorge Luis Borges once wrote of an infinite library in one of his short stories. Imagine running dissociated-press on that library perhaps by invoking a surreal mechanism worthy of Borges. The result would always make sense on the fine scale and sort of work syntactically at the sentence level, but the overall result would be gibberish. If it ran long enough it would tell every truth and every falsehood. It might be very entertaining but not very useful.
Modern generative language systems always remind me of William's syndrome. From an article on the syndrome: "Children with Williams syndrome are chatty, have rich vocabularies and love to tell stories. Yet they have trouble learning certain complex rules of grammar." "The new work, however, finds that children with the syndrome do not understand passive sentences that use abstract verbs, such as ‘love’ or ‘remember.’" "Healthy children learn actional passives by age 5, but don’t learn psychological passives until around age 8." There's a theory that people with William's syndrome often became court jesters as they could be most entertaining.