

What’s wrong with Google’s new robot project

From a showmanship standpoint, Google’s new robot project PaLM-SayCan is incredibly cool. Humans talk, and a humanoid robot listens, and acts. In the best case, the robot can read between the lines, moving beyond the kind of boring direct speech (“bring me pretzels from the kitchen”) that most robots traffic in (at best) to indirect speech, in which a robot diagnoses your needs and caters to them without bothering you with the details. WIRED reports an example in which a user says “I’m hungry”, and the robot wheels over to a table and comes back with a snack, no futher detail required—closer to Rosie the Robot than any demo I have seen before.
The project reflects a lot of hard work between two historically separate divisions of Alphabet (Everyday Robots and Google Brain); academic heavy hitters like Chelsea Finn and Sergey Levine, both of whom I have a lot of respect for, took part. In some ways it’s the obvious research project to do now—if you have Google-sized resources (like massive pretrainined language models and humanoid robots and lots of cloud compute)— but it’s still impressive that they got it to work as well as it did. (To what extent? More about that below).
But I think we should be worried. I am not surprised that this can (kinda sorta) be done, but I am not sure it should be done.
The problem is twofold. First, the language technology that the new system relies on is well-known to be problematic and second it is likely to be even more problematic in the context of robots.
Putting aside robots for the moment, we already know that so-called large language models are like bulls in a china shop: awesome, powerful, and reckless. They can be straight on target in one moment, and veering off into unknown dangers the next. One particularly vivid example of this comes from the French company Nabla, that explored the utility of GPT-3 as a medical advisor:

Problems like this are legion. Another of Alphabet’s subsidiaries DeepMind described 21 social and ethical problems with large language models, around topics such as fairness, data leaks, and information; embedding them in robots that could kill your pet or destroy your home wasn’t one.
It should have been. The PaLM-SayCam experiment makes it pretty clear that the list of 21 problems is due for an update. It’s not just that large language models can counsel suicide, or sign off on genocide, or that they can be toxic and that they are incredibly (over)sensitive to the details of their training set - it’s that if you put them inside a robot, and they misunderstand you, or fail to fully appreciate the implications of your request, they could cause major damage.
To their credit, the PaLM-SayCan crew included at least one check on this happening. For every request that they got from the robot, they included a kind of feasibility check: could the thing that the language model inferred the user wanted to do actually be done. But should it be done? If the user asks the system to put the cat in the dishwasher, it might be feasible, but is it safe? Is it ethical?
Analogous questions apply if the system misunderstands the human, e.g. if the person says “put it in the dishwasher”, and the large language takes the referent to “it” to be the word cat, when maybe the user had something else in mind. And we know from all the research on large language models that they simply aren’t reliable enough to give us anything like 100% clarity on user intentions. Misunderstandings will arise; without really firm checks on these systems, some of those misunderstandings could lead to mayhem.
Maayan Harel drew this great illustration for Rebooting AI, of a robot being told to put everything in the living room away:
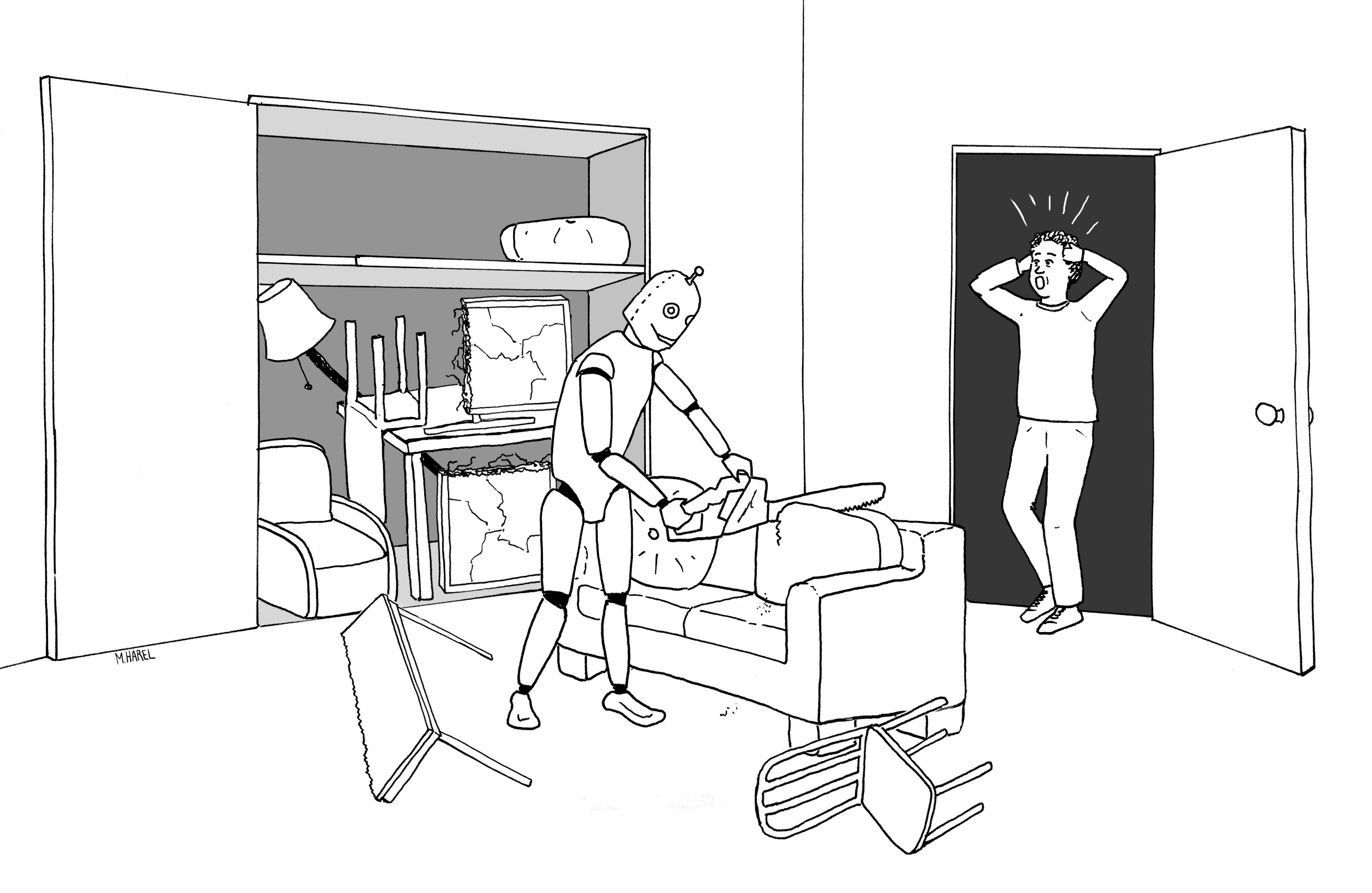
§
The reality is that the field has no compelling idea at the current time how to solve the many “alignment” problems that bedevil large language models. As I have argued throughout the essays in this Substack (eg. Three ideas from linguistics that everyone in AI should know and The New Science of Alt Intelligence) , that’s because large language models are superficial statistical mimics, rather than systems that traffic in rich cognitive models of the world around them. Building a robot on top of language system that has such little comprehension of the world can’t be a recipe for success.
But that precisely what Google’s new system is, a stitching-together of superficial and incorrigible language understanders with powerful and potentially dangerous humanoid robots. And as the old saying goes, garbage in, garbage out.
§
It’s important to remember that there is often vast gulf between demos and reality. Driverless car demos have been around for decades, but making them work reliably has proven far harder than most people realized. Google co-founder Sergey Brin promised in 2012 that we would have them in 2017; in 2022 they are still only in very limited experimental tests. As I warned in 2016, the core problem is edge cases:
[T]hink about driverless cars. What you find is that in the common situations, they're great. If you put them in clear weather in Palo Alto, they're terrific. If you put them where there's snow or there's rain or there's something they haven't seen before, it's difficult for them. There was a great piece by Steven Levy about the Google automatic car factory, where he talked about how the great triumph of late 2015 was that they finally got these systems to recognize leaves.
It's great that they do recognize leaves, but there're a lot of scenarios like that, where if there's something that's not that common, there's not that much data.
That continues to be the core problem. Only in the last few years has the driverless car industry woken up to this reality. As Waymo AI/ML engineer Warren Craddock put it recently in a thread that ought be read in its entirety:

and, critically,
There is no reason on earth to think that robots, or robots with natural language interfaces (a la Google’s new system) are exempt from these problems.
§
A related problem is interpretability. Google makes a big deal about how the system is to do some degree interpretable, but there is no obvious way to integrate large language models with the kind of formal formal verification methods that are now routine in the design of microprocessors, USB drivers and large aircraft.
You don’t need verification if you use GPT-3 or PaLM to write surrealist prose; you can fool a Google engineer into believing that your software is sentient without making sure that what the system is coherent or correct. But humanoid home robots that work on a wide range of household chores (as opposed to just say Roomba’s vacuuming) need to do much more than be social with their users; they need to reliably and safely act on their requests. Without a much greater degree of interpretability and verifiability, its hard to see how we can get to that level of safety.
And more data, the answer that the driverless car industry has been betting on, is not all that likely succeed; here’s something else I said in the same 2016 interview, and that I very much still think is true. Big data won’t be enough to solve the problems of robotics:
If you're talking about having a robot in your home—I'm still dreaming of Rosie the robot that's going to take care of my domestic situation—you can't afford for it to make mistakes. [Reinforcement learning, popular then and part of the new Google system] is very much about trial and error on an enormous scale. If you have a robot at home, you can't have it run into your furniture too many times. You don't want it to put your cat in the dishwasher even once. You can't get the same scale of data. If you're talking about a robot in a real-world environment, you need for it to learn things quickly from small amounts of data.
§
Google and EveryDay Robots ultimately know all this, and have even made a funny video to acknowledge it.
But that doesn’t stop the media from getting carried away. WIRED (blame the editor not the author) wrote this one up with an overblown headline, glorifying pilot research as if a key problem had been solved:

that reminds me of two earlier stories at Wired from 2015, with equally optimistic headlines about projects that never came to light:

and
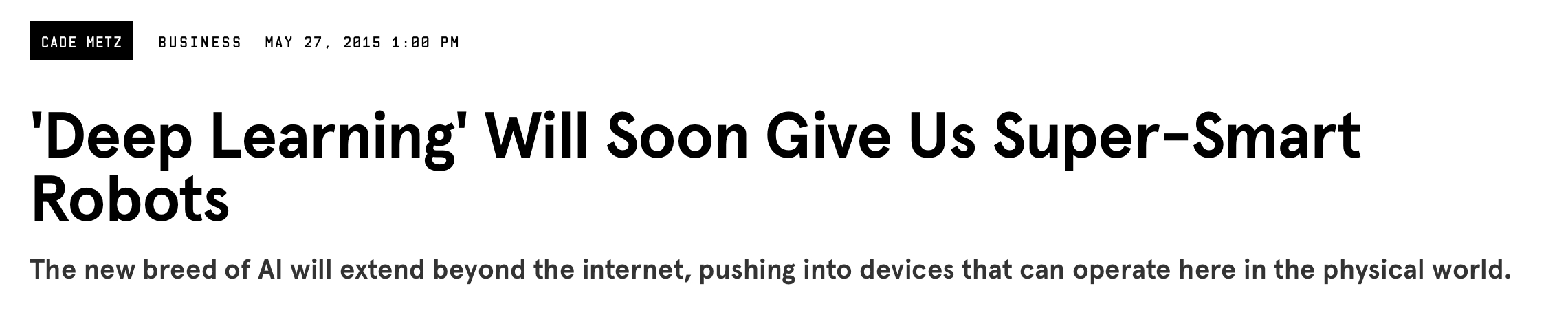
Facebook M was canceled, and 7 years later nobody yet can buy a super-smart (or even decently smart) robot at any price.
§
Of course, Google’s new robot really did learn to take some orders (partly) by scraping the web but robotics is in the details. Performance hovered at around 75% in the best case, when the robots had a limited number of options to consider. And the more actions a robot might consider, the worse performance is likely to be. The Palm-SayCan robot only had to deal with 6 verbs; the average human understands thousands. On some actions, reading Google’s report carefully, the system was at 0% correct execution. This is not enough to get Rosie through the night.
In a general-purpose, humanoid domestic robot, 75% is nowhere near good enough. Imagine a home robot that was asked to lift grandpa into bed, and succeeded only three out of four times. Cool demo, yes. Real world product, anytime soon? Fuggedaboutit.
PaLM-SayCan offers a vision for the future - a system in which, Jetsons-like, we can talk to our robots and have them help with everyday chores. It’s a fine vision, but none of us—and that means you too, Elon Musk—should hold our breath expecting systems like that to materialize in reliable form in the next several years.
Great article!
Again, all this can be traced to 'lack of common sense', which in turns stems from training/'learning' via data - in other words, the robot has no first-hand, physical, ongoing, EXPERIENCE with the physical world it inhabits. The most common things that we say, eg. 'put things away' mean inherently nothing to a robot.
We humans directly deal with the env'mt, form models of it in our minds (however incorrect/incomplete/arbitrary/... they might be), invent symbols (language, math) to externalize our models, communicate our models to each other via those symbols. This is precisely how we have come such a long way, collectively, from our cave past.
The problem is, in current AI, language is used to 'communicate' (train all at once, really) with an **entity that is not set up to form its own models directly from the environment**! IMO this is the #1 problem with any/all of AI [neuro, symbolic, RL...].
Well written again. What I find very interesting is that — regardless of facts — convictions (about almost true AI just around the corner) remain unchanged. Of course that rhymes with how people’s handling of facts is more driven by their convictions than by the facts. Psychology has created quite some insights here, especially over the last 20 years or so.
There is a simple bottom line: there is no chance in hell that we will get the AI people believe we soon will have based on massive amounts of classical (machine) logic. It remains true that humanity is convinced our intelligence has to do a lot with our (limited) ability to do logic, but the fact is that we’re better at frisbee than at logic (Andy Clark). That doesn’t mean that that cultural conviction (already mentioned by Dreyfus in his takedown of the first wave of symbolic AI) is going away soon.