An AI rumor you won’t want to miss
Converging evidence that the core hypothesis driving generative AI may be wrong

As recently as a few days ago, Sam Altman was still selling scaling as if it were infinite, in an interview with the CEO of Y Combinator. “When we started the core beliefs were that deep learning works and it gets better with scale… predictably… A religious level belief … was…. that that wasnt’t gotten to stop. .. Then we got the scaling results … At some point you have to just look at the scaling laws and say we’re going to keep doing this… There was something really fundamental going on. We had discovered a new square in the periodic table”
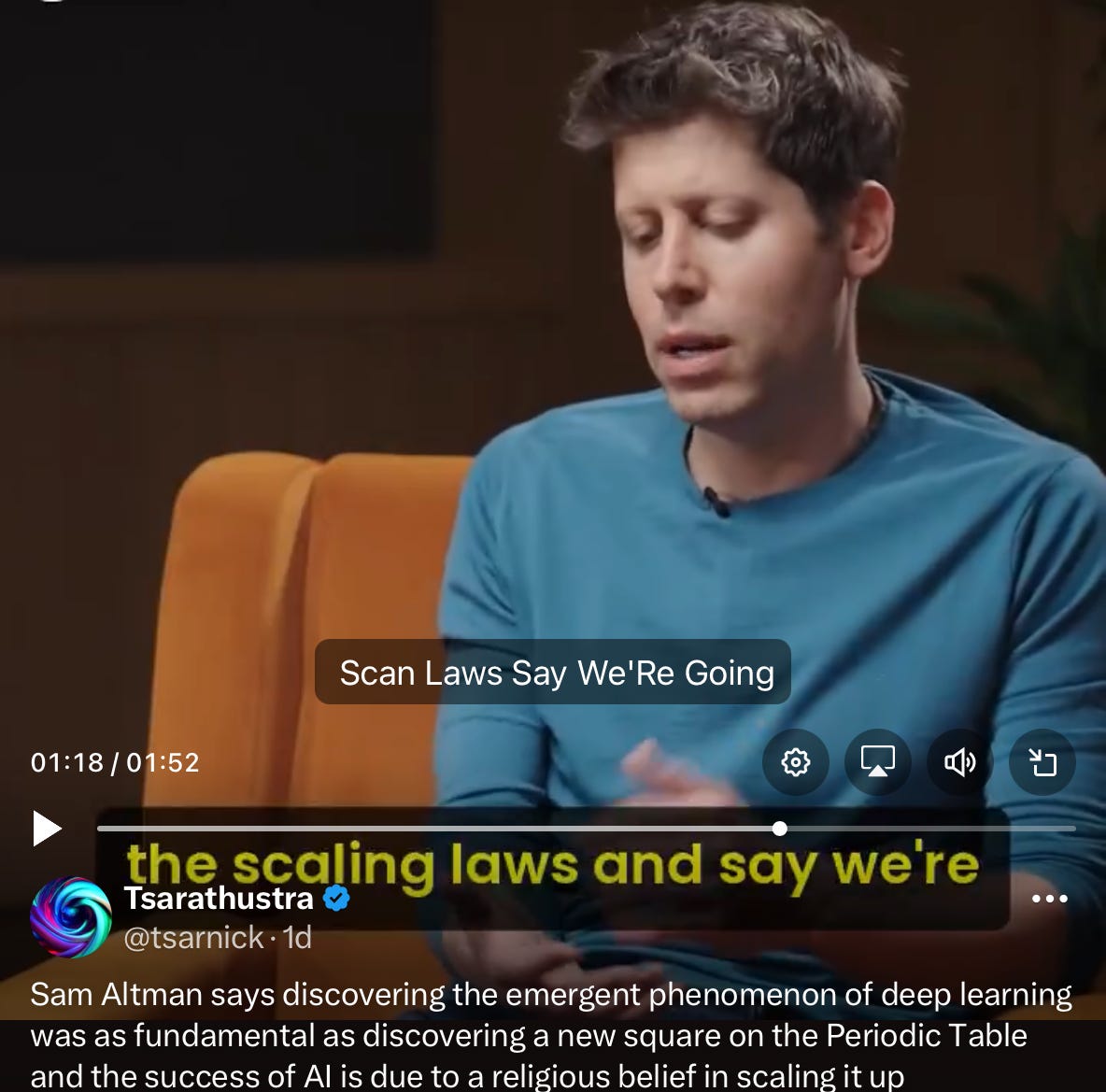
But, as I have been saying since 2022’s “Deep Learning is Hitting a Wall”, scaling laws” are not physical laws. They are merely empirical generalizations that held for a certain period time, when there was enough fresh data and compute. Crucially, there has never been any principled argument that they would solve hallucinations or reasoning, or edge cases in open-ended worlds —or that synthetic data would suffice indefinitely to keep feeding the machine.
As I wrote yesterday (and first noted back in April), I strongly suspect that, contra Altman, we have in fact reached a point of diminishing returns for pure scaling. Just adding data and compute and training longer worked miracles for a while, but those days may well be over.
Today, less than a day later, further potential evidence has just come out, in the form of a tweet, which I reprint below. The tweet is obviously just a rumor (albeit a plausible one, if you ask me), from a researcher who runs an algorithmic trading company.
But if it is true, wow. This not about OpenAI that’s already been reported, but a second major company converging on the same thing:
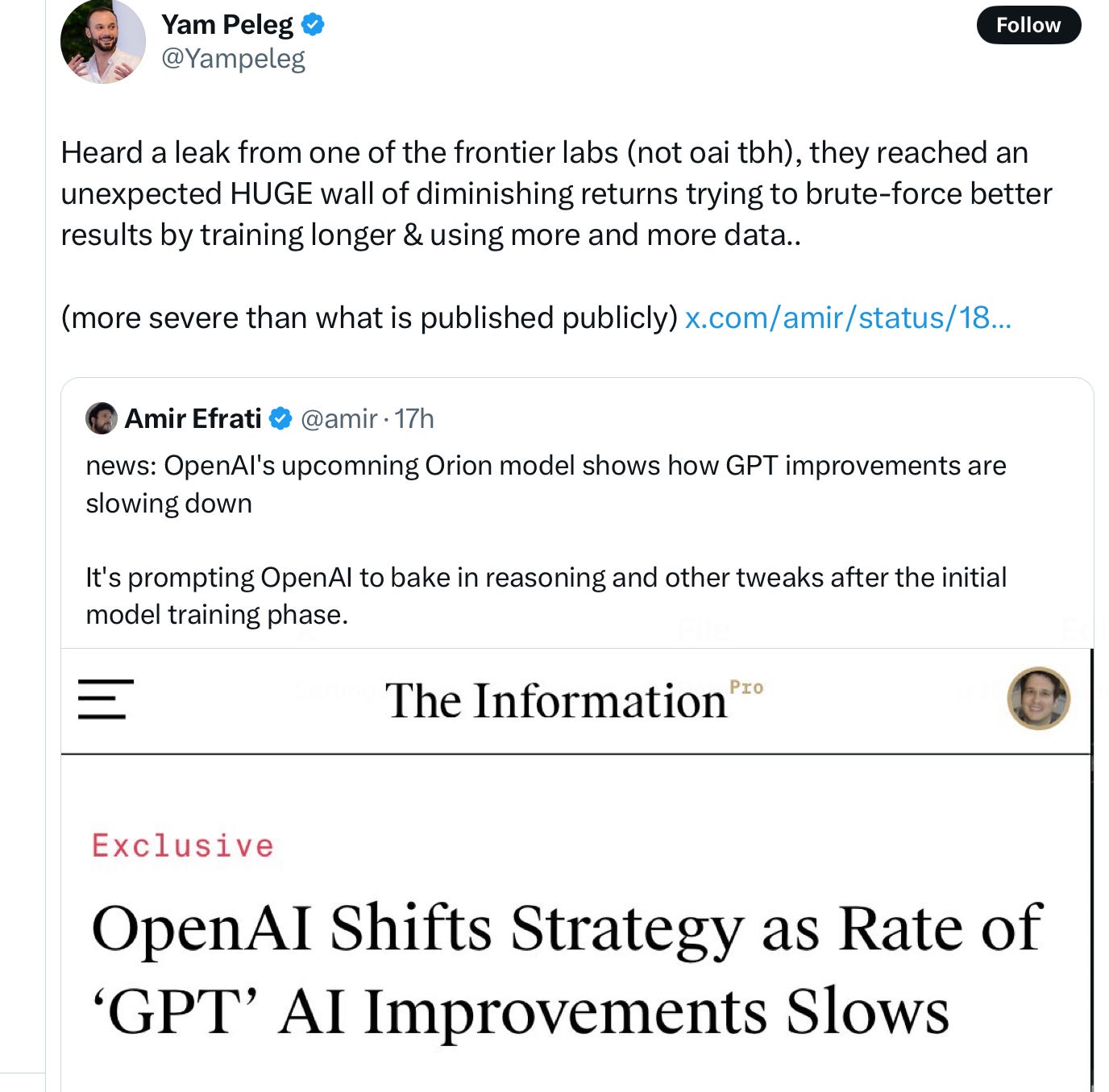
This fits with Amir Efrati’s OpenAI report and Andreeseen’s recent interview that I wrote about yesterday, and the preliminary results I reported in April. (“Unexpected?” Not if you have been reading this Substack!)
If the rumor is verified, there could be the AI equivalent of a bank run.
§
Scaling was always a hypothesis. What happens if suddenly people lose faith in that hypothesis?
Stay tuned.
Gary Marcus is the author of “Deep Learning is Hitting a Wall”.
What I find amazing is that anyone would take a "scaling law" seriously as any kind of predictor of intelligence capacity. How could scaling, or anything else lead a word guesser to become a model of cognition instead of a model of language patterns?
I think of scaling as a Hellman's mayonnaise approach. Pour enough ingredients into the jar and pour out a mind. Wishful thinking.
Sydney Harris drew a cartoon of two scientists looking at a black board on which a three-step process is being described. The middle step is "And then a miracle occurs." That is what the scaling law is. As Harris noted, we need to be a little more explicit about step 2. https://www.researchgate.net/figure/Then-a-Miracle-Occurs-Copyrighted-artwork-by-Sydney-Harris-Inc-All-materials-used-with_fig2_302632920 The required miracle is akin to spontaneous generation in which a piece of vermicelli stored in a glass container, through some unknown means began to show voluntary movement (Mary Shelley in the 1831 edition of Frankenstein). It's a nonsense idea in biology and a nonsense idea in artificial intelligence.
Empirically, what the scaling law advocates miss is that the volume of training text also grew as the number of model parameters grew. The probability that any known problem would be contained in the training set grew as the size of the training set grew. Scaling advocates failed to control for the possibility that the models were merely emitting slight paraphrases of text that the models had been trained on. Instead they relied on the logical fallacy of affirming the consequent to justify their scaling "analysis."
If scaling really is the core of generative GenAI, then it may be useful as long as the problems that people give it are sufficiently similar to existing text. As a theory, it is bankrupt. GenAI models may be sufficient to help people work, but they are no more competent than actors reciting lines to appropriate cues. They are definitely not models of cognition or intelligence.
I have been writing a draft about all the dimensions, i.e. "volume of parameters, "volume of training", "token vector size", "token dictionary size" (these all go hand in hand, there have been slow down reports where only one scaled, but they need to scale concurrently to not hit a wall quickly, in combination they hit a wall as well, just more slowly), "prompt" and 'algorithm width and length' (e.g. o1's CoT, but also the fact that these days many continuations are calculated side by side with pruning the less promising ones on the fly, some LLMs providing more than one continuation (marshalling the users to train the system more). It's all 'engineering the hell out of a limited approach', scaling isn't going to provide any real understanding, period, and if you need understanding, you need a new paradigm. Maybe I'll finish that and publish.
But that LLMs becoming AGI through scaling is dead (it was dead before it started, afaic) doesn't mean GenAI is going to go away. Cheap "sloppy copy" (of skills) may have a decent market, it can definitely speed up a human work, we simply don't know how much and which use cases are economically viable. Not that much as the hype tells us, but also not zero.
So, the current valuations will get some sort of (large) correction, that seems pretty likely. Many investors will get burned. GenAI will remain.
We won't get AGI or any valuation that requires it, certainly not through scaling. I'm convinced of that. Why not simply ignore that hype instead of fighting it? Maybe because of the energy issue? But then, we have bigger problems with that since a day or five.