

o3, AGI, the art of the demo, and what you can expect in 2025
OpenAI’s new model was revealed yesterday; its most fervent believers think AGI has already arrived. Here’s what you should pay attention to in the coming year.


Yesterday was a big deal in AI. Or maybe it wasn’t.
OpenAI revealed o3 in a 25 minute live demo, and its biggest fans thought the demo showed that it was either AGI or really close or an important step to AGI. (It certainly was not the long-awaited GPT-5).
The best results were truly impressive, such as major advances on Francois Chollet’s ARC task and on an important mathematical benchmark FrontierMath.
But what wasn’t shown (or provided) was as important as what was shown.
§
What was shown was a carefully curated demo. What was not provided was any opportunity (yet) for the public to actually try the thing. (What was not shown I will discuss below.)
Before the demo, I made three predictions:
People were certainly amazed.
They did not however get to dive in. What we saw yesterday was a carefully curated demo.
The product was not yet released to the general public; it’s not been vetted by the scientific community. OpenAI chose what to highlight about o3, and hasn’t yet allowed experts to test its scope (with the arguable exception of Chollet and his partner on a single task).
We have seen a bunch of OpenAI demos before of things that either haven’t yet materialized, such as the GPT-4o-based tutor that Sal Khan demo’d in May, which as far as I know is still not publicly available for any sort of testing. Or the 2019 Rubik’s Cube demo that never led to anything the public could try. Until lots of people get to try o3 on many different kinds of tasks, we should not assume that it is reliable. At best, I would wager, it will be reliable for some kinds of problems, and not others. Which brings me to my third prediction, and the next point:
Importantly, there was a dog that didn’t bark. Essentially everything we saw yesterday pertained to math and coding and a certain style of IQ-like puzzles that Chollet’s test emphasizes. We heard nothing about exact how o3 works, and nothing about what it is trained on. And we didn’t really see it applied to open-ended problems where you couldn’t do massive data augmentation by creating synthetic problems in advance because the problems were somewhat predictable. From what I can recall watching the demo, I saw zero evidence that o3 could work reliably in open-ended domains. (I didn’t even really see any test of that notion.) The most important question wasn’t really addressed.
§
It is also insanely expensive. By which I mean that at least for now far far more expensive than average humans. One estimate that I saw is that each call to the system might cost $1000; another suggested that on Chollet’s test, the cost of the most accurate version was about 1000 times paying Amazon Mechanical Turkers.
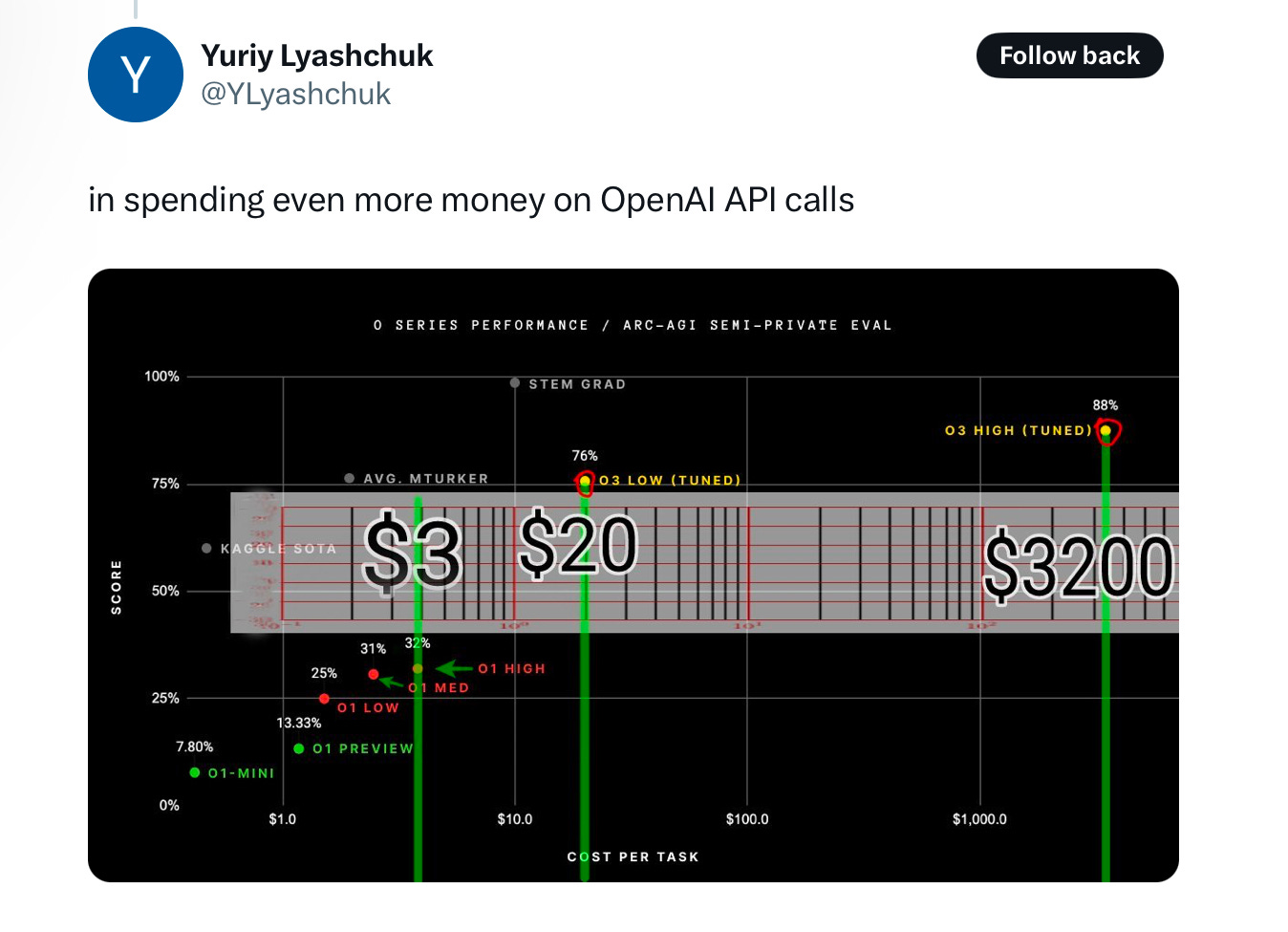
Spending a quarter trillion dollars in order to have something 1000 times more expensive than average humans is maybe not the way to go.
Even if it gets three orders of magnitude cheaper, it’s not as good as the STEM grads at the top of the graph, and probably in many ways not as versatile.
I am struggling to understand the economics here.
Furthermore, the impact of all this on the environment could be immense.
§
On social media, I posted some advice about how to think clearly about demos like o3.
A basic idea in philosophy: something can be necessary but not sufficient. As in: Passing ARC may be necessary but certainly not sufficient for AGI. (Chollet was super clear about this.)
A basic idea in cognitive science and engineering: a mechanism can be effective in some domain, and not others. As in O3 may work for problems where massive data augmentation is possible, but not in others where it’s not.
Most commentary has ignored one or both of these ideas.
Even setting aside the 1000x costs, not one person outside of OpenAI has evaluated o3’s robustness across different types of problems.
If it were truly robust across all or even most problems, they would have called it GPT-5.
The fact that they didn’t is 𝙖 𝙨𝙩𝙧𝙤𝙣𝙜 𝙝𝙞𝙣𝙩 𝙩𝙝𝙖𝙩 𝙩𝙝𝙖𝙩 𝙞𝙩𝙨 𝙨𝙘𝙤𝙥𝙚 𝙞𝙨 𝙞𝙢𝙥𝙤𝙧𝙩𝙖𝙣𝙩𝙡𝙮 𝙡𝙞𝙢𝙞𝙩𝙚𝙙.
§
A lot of fans quoted some positive words from an essay by Chollet yesterday on the new results. Almost none seem to have read further, to the most important part of Chollet’s essay:
it is important to note that ARC-AGI is not an acid test for AGI – as we've repeated dozens of times this year. It's a research tool designed to focus attention on the most challenging unsolved problems in AI, a role it has fulfilled well over the past five years.
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training)”
§
In 2025, a lot of AI influencers and maybe some companies are going to claim we have reached AGI. Almost nobody will give you their definition.
I gave some definitions and examples here in 2022, with some supplemental examples earlier this year (below), in each case offering to put significant money on my predictions, and will stand by what I said.

I wish that others would give lines in the sand in advance; instead, they are likely to craft definitions post hoc, or not give them at all.
Caveat emptor.
§
A couple months ago, I wrote about Apple’s paper on limits in AI reasoning, and how it related to the fundamental point I started discussing 26 years ago: neural networks tend to be better at generalizing “within distribution” than “outside distribution”. An important new paper just out by Qin, Saphra, and Alvarez-Mellis makes this point yet again.

Nothing in the o3 presentation yesterday suggested to me that this decades-old core problem has been remotely solved.
§
I am not saying we will never get AGI.
I am saying that many basic problems haven’t been solved. And I am saying, as every roboticist on the planet knows, that we shouldn’t take demos seriously, until purported products are actually released and subjected to outside scrutiny.
As someone named TauLogicAI elegantly put it on X yesterday,
Lowering the bar for AGI only muddles progress. True AGI requires reasoning frameworks that ensure correctness, adaptability, and logical consistency. The dream of AGI will not be realized by statistical tricks but by building systems capable of true logical reasoning.
I couldn’t agree more. Yesterday’s demo, impressive as it was, doesn’t change that.
Gary Marcus wishes everyone happy holidays. See you in early January.
The simplest way to describe what the o1/o3 GPTs probably basically do is this: instead of being finetuned on generating output directly, it is finetuned on generating CoT steps (in a number of specific domains). For this it has been RLHF'd.
So instead of approximating the textual results, it approximates the textual form of the reasoning steps. It also heavily features the generation of multiple continuations in parallel with evaluation functions and pruning of less scoring ones. Both approaches substantially grow the amount of basic transformer-work (hence the expense). But it still remains the same approximation approach, though because it approximates 'reasoning text' it works better for (specific) 'reasoning tasks'. This improves *on those specific tasks* the approximation quality. But the price is inference cost and more brittleness. Which is why it isn't *generally* better. Some tasks, standard 4o will do better, for instance those that revolve around regenerating meaning out of training material where not so much reasoning but 'memory' is required.
Impressive engineering, certainly, but not a step to AGI, as the core remains 'without understanding brute force approximating the results of understanding'
(My quick educated guess, this)
I worked in database R&D for decades, and for a time the big relational vendors (Oracle, Informix, Sybase, Ingres) were competing based on performance. This led to the creation of a variety of vendor-neutral benchmarks. One might simulate a simple banking transaction, another would simulate a high volume, bulk database update.
Before long every vendor started creating what were called "benchmark specials" by tailoring their software toward the needs of each benchmark suite. Sometimes these capabilities were not considered safe (because they could compromise database integrity, typically) so they couldn't be added to the mainline product; rather, they'd be activated by secret parameters specified at the start of the benchmark run.
The entire Valley has known about benchmark specials for decades. There's a famous 1981 case where a company called Paradyne created fake hardware in order to win a $115 million Social Security contract. The SEC said one device was “nothing more than an empty box with blinking lights” (Paradyne countered by claiming the “empty box” was intended to show how the final product would work).
So I wouldn't rule out the creation of a "benchmark special"