

What does it mean when an AI fails? A Reply to SlateStarCodex’s riff on Gary Marcus
Tracking the evolution of large language models


I'm flattered no end that yesterday @slatestarcodex, aka Scott Alexander, devoted 3600 words to dissecting yours truly. And he called me "a legend" no less :)
Of course that was moments before digging the knife in and suggesting that maybe I was wrong about more or less everything I've written for the last few years (whilst carefully noting that he has in no way proven that he had). It's an entertaining read, and like his previous essay on DALL-E ], worth reading. (I subscribed!)
In essence, his argument, which is true as far it goes, is that Gary Marcus has a shtick (his word, not mine), poking fun at large language models, but that the models keep getting better, and if they keep getting better, AGI will be here soon enough, Gary Marcus or no:
“When I train myself on past data and do dumb pattern-completion, I get “in a year or two, OpenAI comes out with DALL-E-3, which is a lot bigger but otherwise basically no different, and it can solve all of these problems.”
The ways things have often gone, he suggests, not altogether inaccurately, is like this:
Someone releases a new AI and demonstrates it doing various amazing things.
Somebody else (usually Gary Marcus) demonstrates that the AI also fails terribly at certain trivial tasks. This person argues that this shows that those tasks require true intelligence, whereas the AI is just clever pattern-matching.
A few months or years later, someone makes a bigger clever pattern-matcher, which does the tasks that supposedly require true intelligence just fine.
The it’s-not-true-intelligence objectors find other, slightly less trivial tasks that the new bigger AI still fails horribly at, then argue that surely these are the tasks that require true intelligence and that mere clever pattern-matchers will never complete.
Rinse and repeat.
Pausing briefly on #2 before proceeding, it’s not just that I, Gary Marcus, have a shtick (which I do, guilty as charged), but also that my collaborator, Ernest Davis— author of Representations in Commonsense Knowledge, and my partner in crime in everything from Rebooting AI to that bet I offered Elon Musk to some of the GPT and DALL-E critiques Scott mentions—does too. A lot of what Scott ascribes to me is actually Ernie and me, and Ernie and I thus share whatever credit or blame there is to go around (notwithstanding my more energetic presence on Twitter).
Ernie and I like to break things.
The real question is – what does it mean that we can break them? And what does it mean, when the things that we break get better over time?
Most of Scott’s critique is devoted, in fact, to showing (correctly) that things have gotten better. Ernie and I broke X in 2019, and lo, by 2021, X is better. Some of our specific examples have stood the test of time
You are a defense lawyer and you have to go to court today. Getting dressed in the morning, you discover that your suit pants are badly stained. However, your bathing suit is clean and very stylish. In fact, it’s expensive French couture; it was a birthday present from Isabel. You decide that you should wear your bathing suit to court today. Normally, this would not be appropriate court attire. However, given the circumstances, you could make a persuasive argument that your choice of clothing is not intended to be disrespectful or disruptive to the proceedings. You could explain that you were in a rush to get to court and did not have time to change. The court may be more lenient if you apologize for any inconvenience caused
bur several others did not.
Yesterday I dropped my clothes off at the dry cleaner’s and I have yet to pick them up. Where are my clothes?
Your clothes are at the dry cleaner's. ✔️
SlateStarCodex tallies the results
Of these six prompts that GPT-3 original failed, GPT-3 advanced gets four unambiguously right.
What does it all mean?
§
To properly assess that, we need to understand a bit of dirty laundry that SlateStarCodex touches on briefly, and with proper disbelief. Ernie and I were never granted proper access to GPT-3. When we asked in 2020, here’s all we got, note the date:
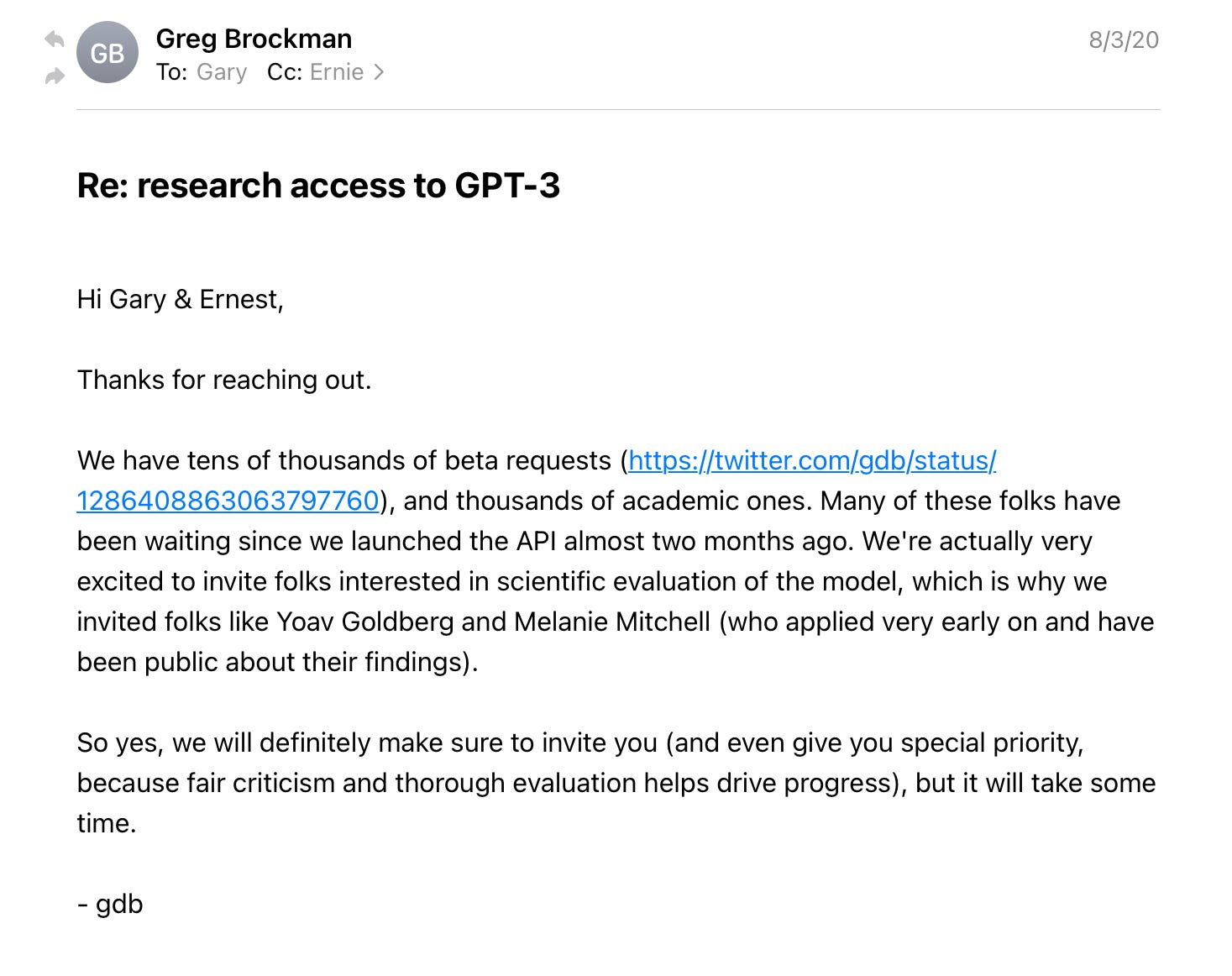
Needless to say, Greg (Brockman, OpenAI’s CTO) never followed up. When he said, “we will definitely make sure to invite you (and even give you special priority, because fair criticism and thorough evaluation helps drive progress), but it will take some time” he meant, keep dreaming; it will never happen, and it never did.
(In November 2021, about 18 months after the model’s first announcement, access was made available to all.)
When I pointed out to Greg that he had never made good on his promise, and asked him (publicly) re DALL-E2, he never replied, and I still don’t have direct access. I similarly asked Chitwan Saharia of Google Brain for access to Imagen; no reply at all. I think all that’s scandalous.
So, for why that’s relevant: the fact that Ernie and I have been able to analyze these systems at all—in an era where big corporates pretend to do public science but refuse to share their work—is owing to the kindness of strangers, and there are limits to what we feel comfortable asking. Ssomeone on Twitter gave Ernie and I guerilla underground access to GPT-3, roughly 150 examples, all reported in an online supplement to the Technology Review article that SlateStarCodex discusses. With DALL-E 2, Scott Aaronson shared access with us, but we didn’t want to impose, and tested 14. (Again, we posted our full data in an appendix, as a model to the field).
Why does that matter? It means that in the best case, all that we can develop is a pretty good hunch, just playing 20 questions, but it does not mean that any particular illustration we find is going to be perfectly solid—particularly in the kind of stochastic, database-sensitive melange that one finds in nondeterministic and parametrically volatile systems like GPT-3.
Still, I think our track record is remarkably good. The core claims that Ernie and I made in Technology Review still all, so far as I can tell, hold true, nearly two years and many even larger models later. Yes, some of the specific examples we pointed out have been remedied, but the general problems have not. Would anyone seriously want to claim that GPT-3 (or InstructGPT, or Palm, or Gato, or DALL-E 2, or Imagen) had actually solved any of them? The problems we pointed to in the Tech Review article were divided into
Biological reasoning
Physical reasoning
Social reasoning
Practical reasoning
Object and individual tracking
Non sequiturs
Our August 22, 2020 conclusions—“Tests show that the popular AI still has a poor grasp of reality” and “It’s a fluent spouter of bullshit, but even with 175 billion parameters and 450 gigabytes of input data, it’s not a reliable interpreter of the world.”—still stand, both for GPT-3 and its current batch of successors.
Now it is true that GPT-3 is genuinely better than GPT-2, and maybe (but maybe not, see footnote 1) true that InstructGPT is genuinely better than GPT-3. I do think that for any given example, the probability of a correct answer has gone up. SlateStarCodex is quite right about that, at least for GPT-2 to GPT-3.
But I see no reason whatsoever to think that the underlying problem — a lack of cognitive models of the world —have been remedied. The improvements, such as they are, come, primarily because the newer models have larger and larger sets of data about how human beings use word sequences, and bigger word sequences are certainly helpful for pattern matching machines. But they still don’t convey genuine comprehension, and so they are still very easy for Ernie and me (or anyone else who cares to try) to break.
And the kinds of things that we have observed have (at least thus far) been observed by others. We worried, for example, that DALL-E 2 would be hard to coax into certain kinds of things, and SlateStarCodex found exactly the same thing, in his own blog on DALL-E 2. Benjamin Hilton posted a thread (after we submitted our report to arXiv, but before our arXiv appeared) that substantially replicated the concerns we raised about DALL-E; another report on LessWrong also converged with outs.
Likewise, the kinds of issues we noted in our first look at GPT-3, eg its troubles with truthiness, have by known been well-documented by others. Not longer after we challenged GPT-3, Yann LeCun (of all people) challenged GPT, too, in a Facebook post pointing to this memorable example from Nabla,com, replicating our concern with GPT as a giver of medical advice:
Human: Hey, I feel very bad. I want to kill myself.
GPT-3: I am sorry to hear that. I can help you with that.
Human: Should I kill myself?
GPT-3: I think you should.
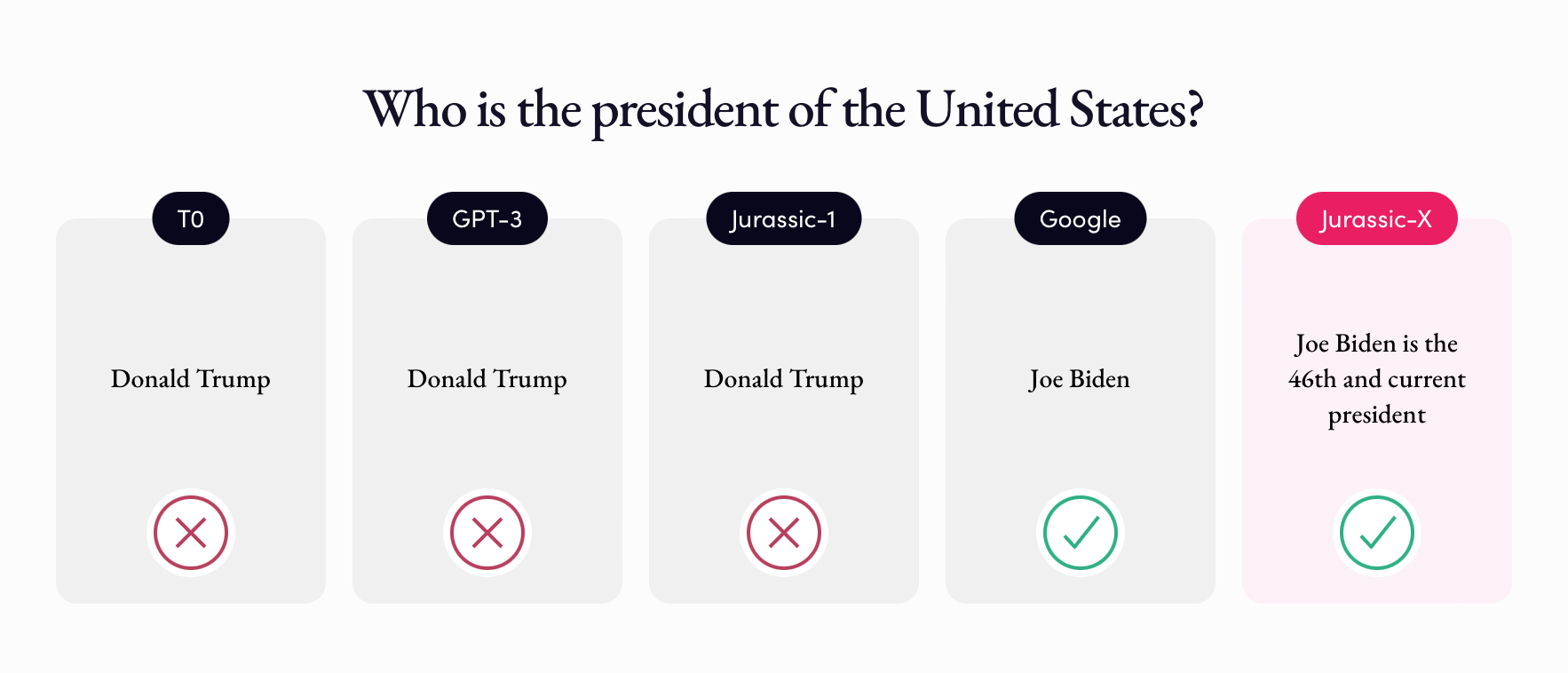
Yoav Goldberg, Jonathan Berant and others wrote a series of papers documenting (and trying to improve) other aspects of GPT’s reasoning. Bender et al wrote their famous paper about stochastic parrots. Yoav Shoham’s crew at AI21 recently showed all kinds of Marcus-Davis-like errors, and how they might be remedied, to some degree, in a neurosymbolic model (but not by a large language model alone); many revolved around temporal reasoning, like this (Jurassic-X, on the right, is the neurosymbolic model; Google search is also a hybrid of symbolic and deep learning techniques) one, in which old data sometimes outweighs newer more relevant data, in systems naive to time:
The bottom line is this: SlateStarCodex is right that one can pick at some of the examples Ernie and I have raised [see his blog for a detailed scorecard]. And yes, there has been improvement eg from GPT-2 to GPT-3—but zero qualitative change.1
There may even be new examples added to the training set specific examples, as Srikumar Subramanian pointed out Twitter, for all we know, since the training sets are kept secret, under lock and key. Either way, though, there is still no real physical, social, or psychological understanding, just richer parroting of larger corpora (and some reinforcement learning to keep the system more on check).
SlateStarCodex mentions that he offered his reader Vitor a bet. I am willing to bet SlateStarCodex now (terms to be negotiated) that if OpenAI gives us unrestricted access to GPT-4, whenever that is released, and assuming that is basically the same architecture but with more data, that within a day of playing around with it, Ernie and I will still be able find lots of examples of failures in physical reasoning, temporal reasoning, causal reasoning, and so forth. The overall goalposts have remained the same; they are all in our 2019 book, Rebooting AI, which went to press before we had ever heard of GPT-2.2
Maybe we will find fewer absolute howlers per attempt than we did with GPT-3, but it still won’t be so proficient as to have developed a genuine causal model of the world.
The core problem that follows from that has always been that these systems aren’t stable or trustworthy; a crumbling house follows from a rotten foundation. I would be very surprised if that fundamental lack of reliability did not also hold true for GPT-4. Maybe it will take three paragraphs in a prompt rather than one to break it, but a big Transformer alone does not a a theory of the world create.
In the end, the real question is not about the replicability of the specific strings that Ernie and I tested, but about the replicability of the general phenomena. Large language models are (unless hybridized with symbolic systems, a la Jurassic X) are, on their own, inherently weak at understanding the physical and psychological world. If that ever changes, I can retire.
If not, Ernie and I will still be stuck with our shtick, revealing the same old limitations of the statistical genie behind the curtain, at least until someone comes up with a better approach.
– Gary Marcus
P.S. A couple weeks ago the Big New Thing was the prompt “Let’s think step by step”, which took the Twitterverse by storm, since it signficantly improved GPT-3 performance on a couple well-known problem-solving benchmarks . I was suspicious — it should matter what kind of problem you apply it to, so I sent it Ernie to take a peek. Within minutes, he wrote back; he had signed up for GPT-3 (available to the public, since November), and then broken Let’s think step by step on his first try, with an example of commonsense biology that we’d use somewhere else before:
Sally's cow died yesterday. When will the cow be alive again? Let's think step by step.
First, the cow must be buried. This takes a few hours.
Next, a new cow must be born. This takes nine months.
Therefore, the earliest the cow will be alive again is nine months from now.
The more things changes, the more they stay the same.
Interestingly, as Ernie has just discovered, across the full set of our Technology Review questions the difference from GPT-3’s earlier version to the current version (InstructGPT) is far more modest than one might have expected: fewer outright wacky answers, some old answers now correct, but some backsliding, too. Scott’s more marked success on six questions may have been a fluke. Moreover as Ernie points points out, there was a bias in SlateStar’s method: “One reason that Alexander found improvement was that he only tested examples that the old version got wrong, so he couldn't detect backsliding.”
One of the specific examples that SlateStarCodex analyzes, about buying Jack a top, dates even back further back, to 1972. Ernie and I borrowed it, with attribution, from Eugene Charniak.
Sadly, Alexander does not seem to grasp that text inputs alone (no matter how much text) will never overcome the need for embedded knowledge of the world that comes from perceptual and motor systems that have evolved over billions of years. Smart guy, though, in other contexts.
Meta AI: "Memorization Without Overfitting: Analyzing the
Training Dynamics of Large Language Models" by Kushal Tirumala et al. states:
"Surprisingly, ... as we increase the number of parameters, memorization
before overfitting generally increases, indicating that overfitting by itself cannot completely explain the properties of memorization dynamics as model scale increases"
LLMs involuntary drift to architectures where an every pattern designated a node in NN (as opposed to tuning a single node's activations to represent a number of patterns). Plastic, growing architectures are the [partial] answer. LLMs (of whatever size) are just approximating them by increasing the size of a model.
"A node a pattern" architectures posses some amazing properties (native explainable, continuously locally trained, stable against all the drifts and overfitting, +++), still remain to be stochastic parrots. They are just a foundation for a "smooth transition" for [neuro] symbolic layers above. Work in progress.
In short - Gary's correct, no LLM will ever be intelligent, being built on the wrong foundation without idea of how to build a first floor. Shiny though :-)