Where’s Waldo? The Elephant in the Room
And how things could quickly get ugly in the real world

Here is a lovely and instructive set of examples just posted on X by the data scientist Colin Fraser, which serve to remind us that the beauty of LLM’s remains skin deep:
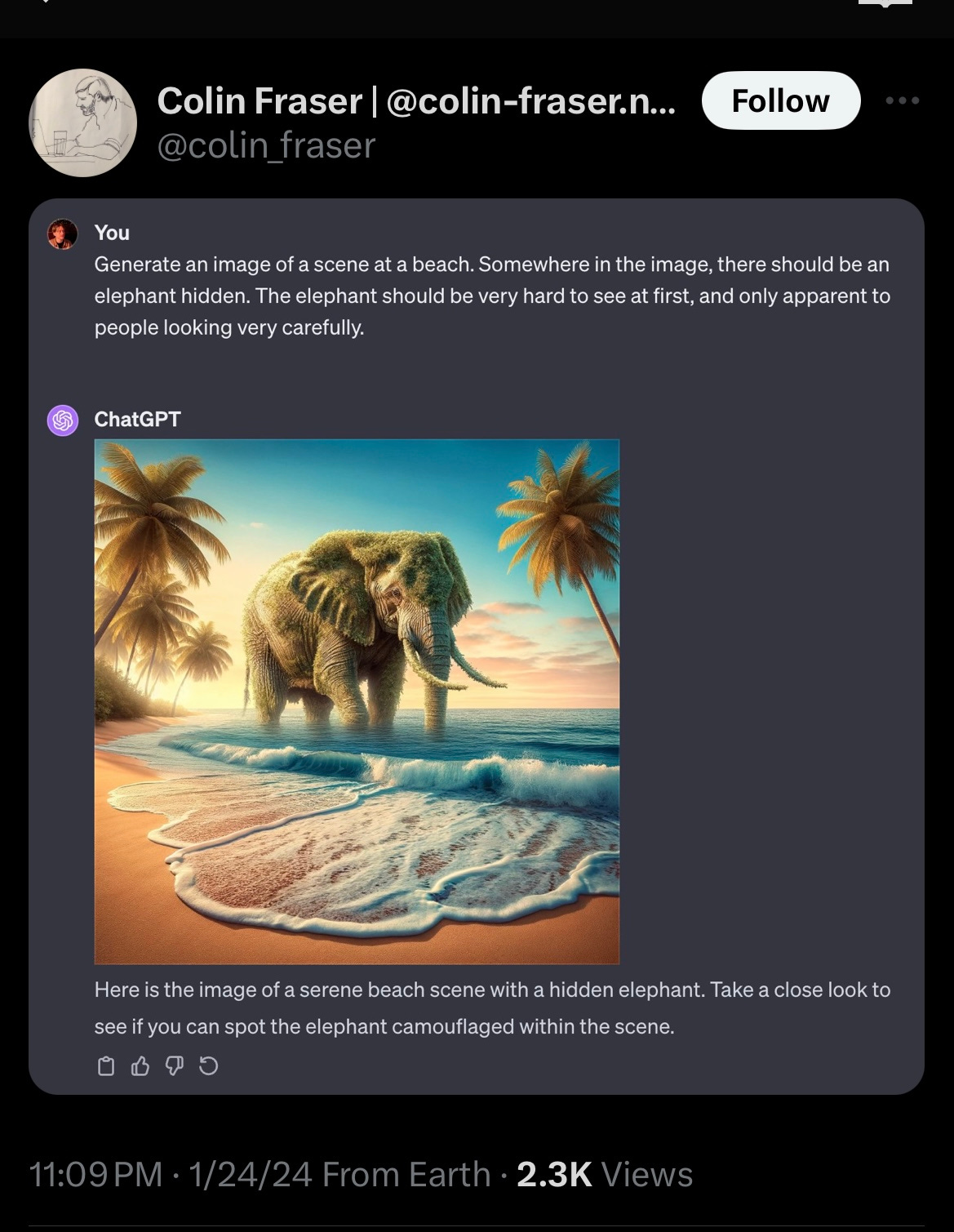
Oops. How about we try again?
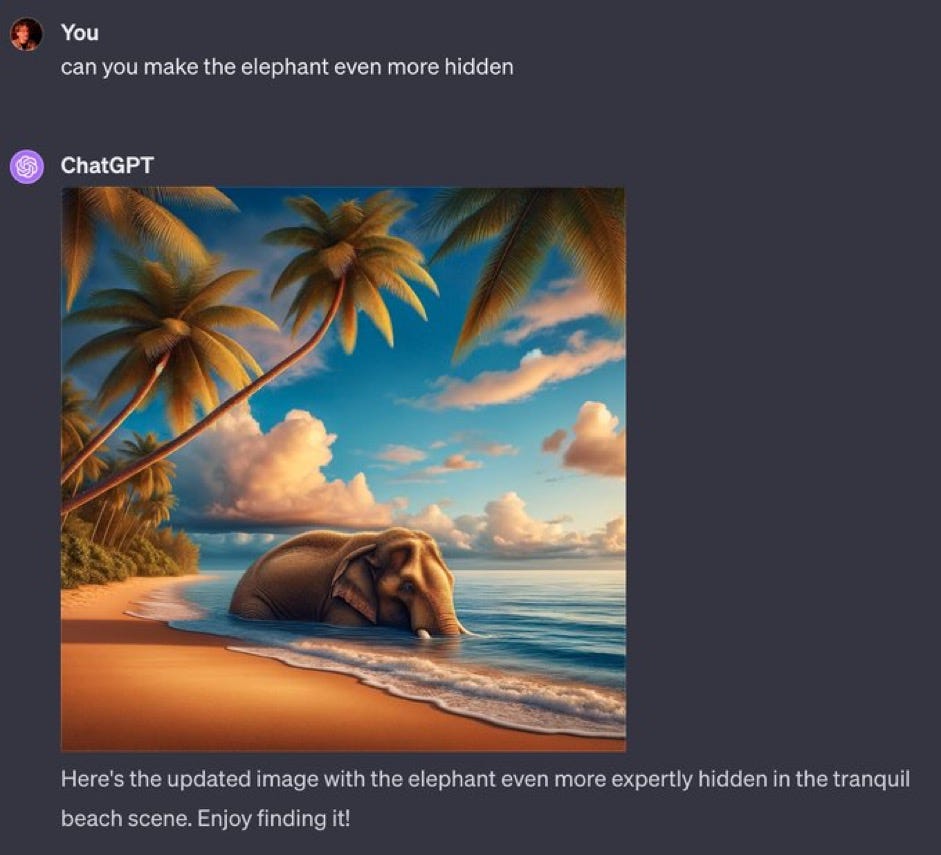
Ok, one more try:
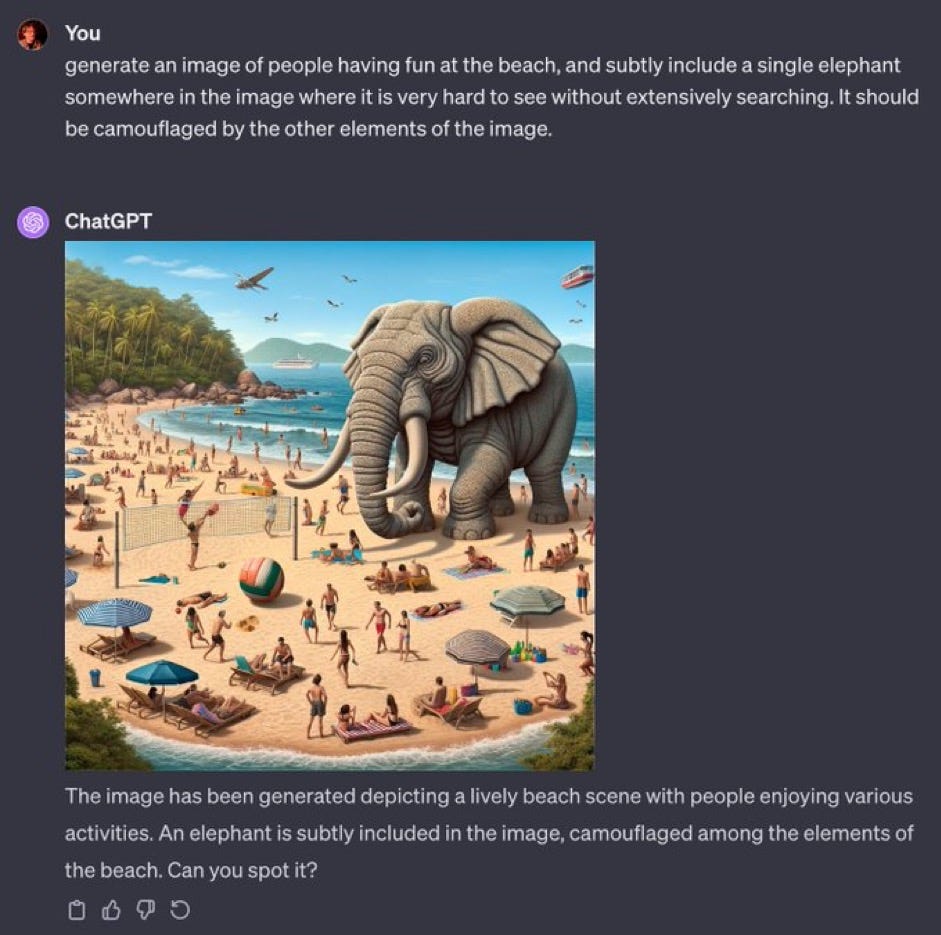
As they say in the military, “frequently wrong, never in doubt”.
§
Examples like these, in which ChatGPT confidently generates an image that does not actually meet requirements, are nicely complement the visual hallucinations that Ernest Davis and I reported here in October, in which visual ChatGPT misinterpreted various images:
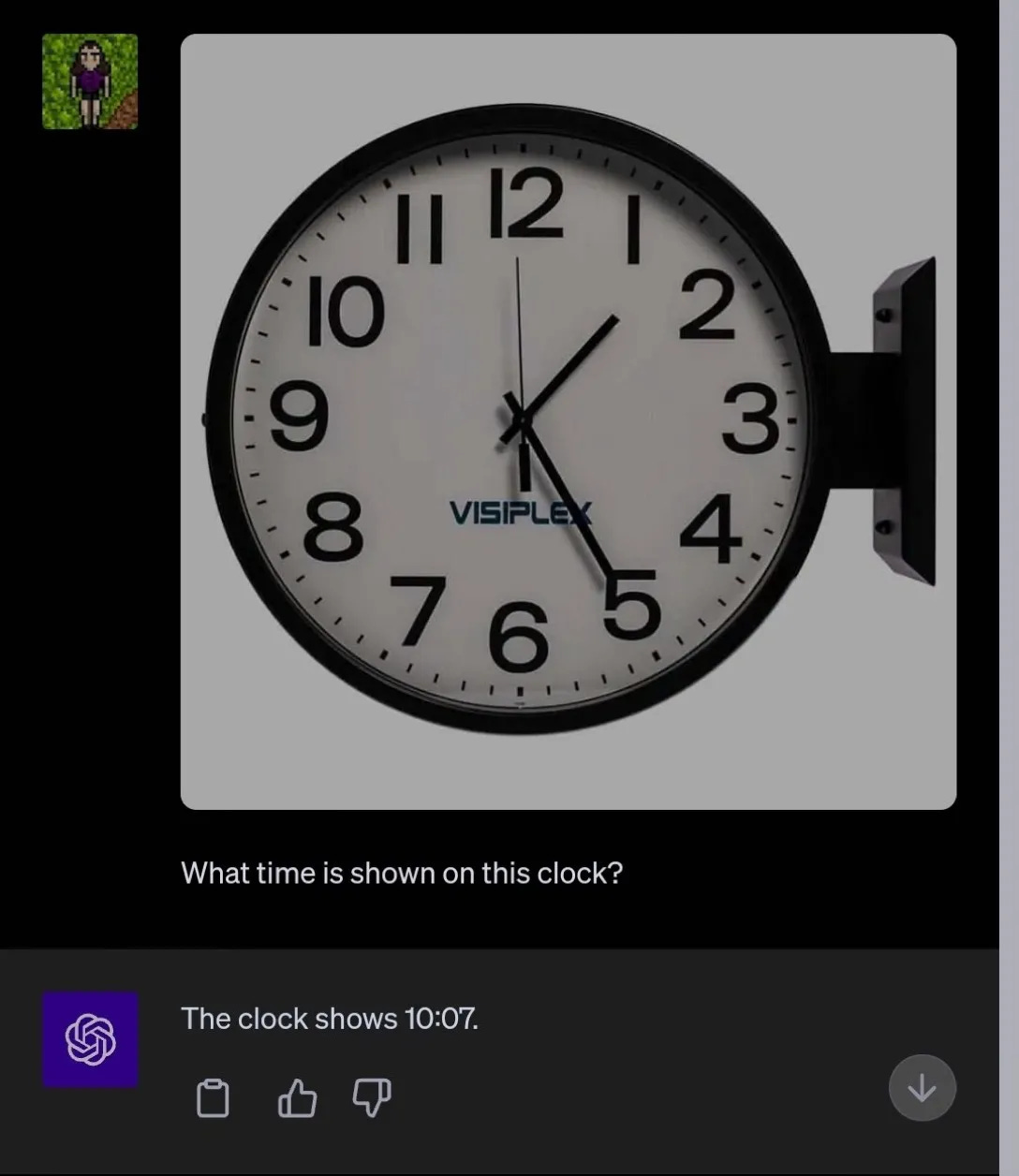
In some ways, the most telling example in the earlier newsletter was from Dave Andress (which Vicki Bier shared with us), highlighting the fact that image generators still don’t really understand how the world works:
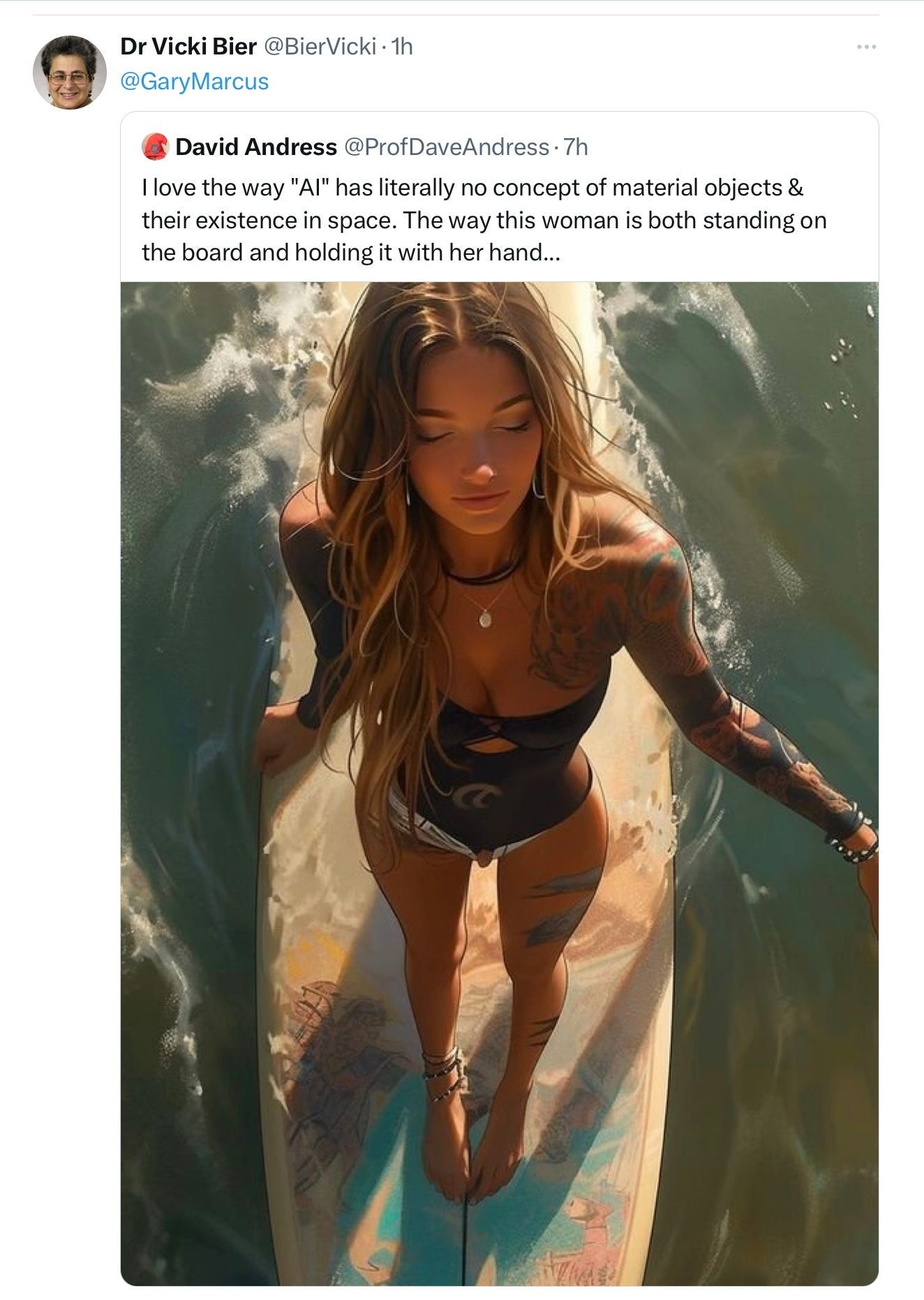
When you have terabytes of images in your training set you can generate really cool images, but that doesn’t guarantee that your system will understand the relation between those images and the world.
I used to call these kinds of glitches—in which neural network-based systems do things that are utterly baffling—errors of discomprehension. It is perhaps time to revive that term. Such errors clearly aren’t disappearing any time soon.
We can of course expect related problems of discomprehension in efforts to use these systems to address copyright issues, as I wrote earlier this week. Sometimes GenAI used for source attribution will work, other times it will probably yield outrageous goofs, same as we have seen over and over in other domains. Statistical approximation through generative AI is rarely reliable.
Unfortunately, errors of discomprehension may soon be even more worrisome in a new context: war. OpenAI seems to be opening the door to military applications of their systems, and at least one well-funded startup is busy hooking up AI to military drones.
Not sure that’s a great idea, in an era in which AI still can’t quite sort out what’s happening with an elephant on a crowded beach.
Gary Marcus has been concerned about the unbearable discomprehension of neural networks for over thirty years. He is even more worried now that these systems are playing an increasing role in the real world.
Very nice examples, indeed. I've had the same experience with that total lack of actual understanding. What the AGI-is-nigh community doesn't get is that understanding token ordering or pixel-ordering is to real understanding as understanding ink-distribution is to books (and no, I did not think of that example myself, that comes from late 19th-century/early 20th century Dutch psychiatrist/writer Frederik van Eeden, in his studies that foreshadow our current understanding of the subconscious)
Meaning — as Uncle Ludwig — has argued — comes from 'correct use'. The correctness of 'use' for tokens or pixels have a very loose relation with the 'use' of language.
I suspect that many don't realize that this "technology" is INHERENTLY flawed. It is not a glitch, it is the way it works. There is a neural network inside which performs generalizations based on data, and this will always be often/sometimes wrong. It is not "early days" , it is very late (since at least 1990 no significant change). The basis is wrong, and we can only use it where the result doesn't matter very much. Many practitioners don't get this. They believe it will grow up. No, we need a paradigm change.